双核不可阻挡!首款双核处理器Tegra2详解
来源:互联网 发布:php flash session 编辑:程序博客网 时间:2024/05/14 17:16
原文出处:http://www.3533.com/news/2011/3/31/125820.htm
智能手机 的兴起带动了整个手机软硬件的发展和升级,当我们惊呼1Ghz高频手机处理器的出现并成为主流的时候,却又发现即使这样还是无法满足我们对智能手机的无限追求;并且在移动互联网蓬勃发展的今天,越来越多的应用需要用到更高的硬件处理性能,以满足之前只能在PC上实现而现在需要在智能手机上实现的功能。
当一切显示出需要一款比1Ghz更强劲的手机处理器出现时,于是我们看到了潜伏在手机芯片研发多年的NVIDIA开始爆发,一款基于ARM Cortex A9架构设计,具备两个ARM Cortex A9处理器同时还搭配8颗Geforce核心的超级手机处理器诞生了——NVIDIA Tegra 2。

Tegra 2开手机双核处理器先河
对于Tegra 2来说其双核心设计毫无疑问开创了手机业界先河,并且两颗1Ghz频率的处理器也达到了手机性能的一个空前高度。不过,Tegra 2的强悍不仅于两颗1Ghz的处理器,还有八颗Geforce图形核心,要知道在图形核心领域NVIDIA可是一直处于全球领先的位置。因此具备了如此高硬件规格的Tegra 2在今年的CES大放光彩也就并不意外了。
在可以预见的未来,双核手机势必会逐渐增加并且取代单核成为主流(至少是高端机主流配置),作为开手机双核处理器先河的Tegra 2,我们或许知道它拥有两个ARM架构处理器也知道它具备非常出众的3D性能,但是对于这款处理器的更为详细的介绍我们或许并不一定知道,在基于Tegra 2处理器手机越来越多的时下,我们不妨先来全面了解一下有关Tegra 2的详细介绍。

Tegra 2处理器核心架构图
Tegra 2处理器采用的是异构多核架构设计,所谓异构多核架构简单的说就是将不同类型的内核集成在一起,每个核心独立进行不同的任务,而不再只是是CPU进行全部的处理。从NVIDIA的官方资料中可以得知Tegra 2处理器的面积只有1/4个硬币大小,而就是在这个仅1/4硬币大小的面积上,Tegra 2集成了8个独立的处理器单元,相比第一代多了一个处理器单元,因为Tegra 2处理器采用的双核心设计。

七个处理器独立处理任务
Tegra 2的七个独立处理器分别是两颗ARM Cortex-A9处理器、一颗8核心的Geforce GPU处理器以及高清视频解码器、音频解码器、图像处理器和ARM7控制核心。七颗独立的处理器让Tegra 2无论在上网、音视频播放、图像处理器以及3D游戏的Flash加速方面都能得心应手。下面我们为大家分别介绍这几颗核心在Tegra 2中的作用。
ARM Cortex-A9处理器相关介绍
Cortex-A9处理器基于先进的推测型八级流水线,该流水线具有高效、动态长度、多发射超标量及无序完成特征,这款处理器的性能、功效和功能均达到了前所未有的水平,能够满足消费、网络、企业和移动应用等领域产品的要求。
Cortex-A9微架构可提供两种选项:可扩展的Cortex-A9 MPCoreTM多核处理器和较为传统的Cortex-A9单核处理器。可扩展的多核处理器和单核处理器,支持16、32或64KB四路组相联一级缓存的配置,具有无与伦比的灵活性,皆能达到特定应用和市场的要求。

ARM Cortex- A9架构
特定应用优化 :Cortex-A9和Cortex-A9 MPCore应用级处理器都拥有丰富的功能,同时也承袭了ARMv7 架构的强大优势,为特定应用和通用设计提供了高性能、低功耗的解决方案。
先进的微架构 :Cortex- A9微架构的设计不但着眼于解决超高频设计的效率低下问题,而且把目标定为在不增加嵌入式设备硅成本的前提下最大限度地提升处理效率。通过综合技术,这种 处理器设计能使设备的时钟频率超过1GHz,而且提供了较高的功效水平,满足了长时间电池供电工作的要求。

ARM Cortex- A9架构的诸多优势
流水线性能 :Cortex- A9处理器最主要的流水线性能包括以下几条:第一,先进的取指及分支预测处理,可避免因访问指令的延时而影响跳转指令的执行;第二,最多支持四条指令 Cache Line预取挂起,这可进一步减少内存延时的影响,从而促进指令的顺利传输;第三,每个周期内可连续将两至四条指令发送到指令解码,确保充分利用超标量流 水线性能。Fast-loop模式:执行小循环时提供低功耗运行;第四,超标量解码器可在每个周期内完成两条完全指令的解码;第五,支持指令预测执行:通 过将物理寄存器动态地重新命名至虚拟寄存器池来实现。
第六,提升了流水线的利用效率,消除了相邻指令之间的数据依赖性,减少 了中断延时;第七,支持寄存器的虚拟重命名:以一种有效的、基于硬件的循环展开方法,提高了代码执行效率,而不会增加代码大小和功耗水平;第八,四个后续 流水线中的任何一个均可从发射队列中选择执行指令—提供了无序分配,进一步提高了流水线利用效率,无需借助于开发者或编译器指令调度。确保专为上一代处理 器进行优化的代码能够发挥最大性能,也维护了现有软件投资。
第九,每周期支持两个算术流水线、加载-存储(load- store)或计算引擎以及分支跳转的并行执行;第十,可将有相关性load-store指令提前传送至内存系统进行快速处理,进一步减少了流水线暂停, 大幅提高了涉及存取复杂数据结构或C++函数的高级代码的执行效率;第十一,支持四个数据Cache Line的填充请求:而且还能通过自动或用户控制预取操作,保证了关键数据的可用性,从而进一步减少了内存延时导致的暂停现象;第十二,支持无序指令完成 回写:允许释放流水线资源,无需受限于系统提供所需数据的顺序。
Cortex-A9 MPCore技术
Cortex-A9 MPCore多核处理器是一种设计定制型处理器,以集成缓存一致的方式支持1到4个CPU内核。可单独配置各处理器,设定其缓存大小以及是否支持FPU、 MPE或PTM接口等。
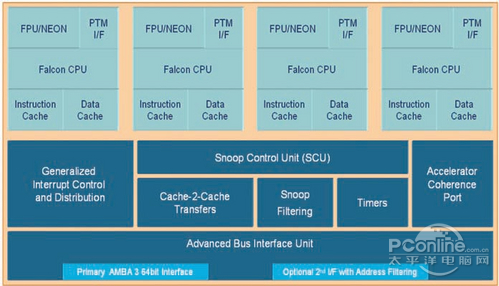
Cortex-A9多核处理器
此外,无论采用何种配置,处理器都可应用一致性加速口,允许其他无缓冲的系统控制外设及加速器(如DMA引擎或加密加速器)核与一 级处理器缓存保持缓存一致。另外还集成了一种符合GIC架构的综合中断及通信系统,该系统配有专用外设,其性能和软件可移植性都更上一层楼,适当配置后, 可支持0(legacy bypass 模式)到224个独立中断资源。这种处理器可支持单个或两个64位AMBA3 AXITM互联接口。

ARM MPCore灵活和先进的功耗管理技术
利用ARM MPCore技术的设计灵活性和先进的功耗管理技术,Cortex-A9 MPCore的针对性应用能够在有限的功耗下维持移动设备的正常运转,从而为移动设备带来优于现有解决方案的峰值性能。这种处理器充分利用了可扩展峰值性能,在性能上超越了现有的同等高端嵌入式设备,并在更为广阔的市场中维持了持续稳定的软件投资。
侦测控制单元(SCU)
SCU 是ARM多核技术的中央情报局,负责为支持MPCore技术的处理器提供互联、仲裁、通信、缓存间及系统内存传输、缓存一致性及其他多核功能的管理。
同时,Cortex-A9 MPCore处理器还率先向其他系统加速器及无缓冲的DM A驱动控制外设开启此类功能,通过处理器缓存层次的共享,有效地提高了性能、减少了整个系统的功耗水平。不仅如此,利用这种系统来维持每个操作系统驱动中 的软件一致性,软件复杂性就大大降低了。
加速器链接埠
这个与AMBA 3 AXI兼容的Slave接口位于SCU之上,为多种系统Master接口提供了一个互联接口;出于总体系统性能、功耗或软件简化等方面的考虑,最好直接将 这些Master接口与Cor tex-A9 MPCore处理器相连。这是个标准的AMBA 3 AXI Slave接口,支持所有标准读写事务,对所接部件无任何附加一致性要求。

加速器链接埠
然而,指向某个一致内存区的读取事务要与SCU发生作用,以检测所需信息是否已经存储在处理器的一级缓存之中。若检 测出确已存储,相应信息将被直接返回给发出请求的组件。如果一级缓存中不存在该信息,在最终传给主内存之前也可能检测二级缓存。对于指向一致内存区的写入 事务,SCU会在把写入事务传送至内存系统之前强制确保一致性。也可选择性地将事务分配给二级缓存,以避免直接写入片外内存所带来的功耗及性能影响。
通用中断控制器(GIC)
该 GIC采用了最近标准化和架构的中断控制器,为处理器间通信及系统中断的 路由 选择及优先级的确定提供了一种丰富而灵活的解决办法。最多支持224个独立中 断,通过软件控制,可在整个CPU中对每个中断进行分配、确定其硬件优先级并在操作系统与信任区软件管理层之间进行路由。这种路由灵活性加上对中断虚拟进 入操作系统的支持,是进一步提升基于半虚拟化管理器解决方案功能的关键因素之一。
先进的总线接口单元
Cortex-A9 MPCore处理器增强了处理器与系统互联之间的接口性能,其先进特色功能最大限度地提高了系统性能,为各种系统集成芯片设计理念创造了更大的灵活性。
这种处理器支持单个或两个64-b i t AMBA 3 AXI Master接口的设计配置,可以按CPU的速度全负荷地将事务传送至系统互联之中,最高速度可达12G B/s以上。另外,第二接口也可定义某种事务过滤,只处理全局地址空间的一部分;也就是说,可在处理器内部直接对地址空间进行切分,进一步加强了系统设计 的灵活性。
而且每个接口还支持不同的CPU-总线频率比(包括同步半时钟比),不但提高了设计灵活性,而且为需要考虑DVFS或高速集成内存的设计增加了系统带宽。同时为完整的A RM智能能量管理 (IEM)功能提供了良好的支持。
特定应用的计算引擎加速
处理器不但拥有优化的标准架构特色,而且还可增加以下任一设计功能:

先进二级缓存控制器 :ARM二级缓存控制器( Prime Cell PL310)与Cortex-A9系列处理器同步设计,旨在提供一种能匹配Cortex-A9处理器性能和吞吐能力的优化二级缓存控制器。PL310最多可为每个接口提供8项AXI事务支持,支持按Master接口进行锁定;这样一来,即通过将PL310用作加速器与处理器之间的缓冲器,充分利用一致性加速口,实现多个CPU或组件之间的可控共享,既提升了系统性能,也降低了相关功耗水平。
另外,PL310不但具有Cortex-A9先进总线接口单元的各项功能,支持同步1/2时钟比,有助于减少高速处理器设计中的延时现象,而且能够对第二MasterAXI 接口设置地址过滤,分割地址和频率域、以及集成片上内存的快速存取提供了支持。PL310最高可支持2MB的四至十六路组相联二级缓存,可与奇偶校验及支持E C C的R A M集成,而且运行速率能够与处理器保持一致。而先进的锁定技术也提供了必要的机制,从而将缓存用作相关性加速器和处理器之间的传输RAM。
Cortex-A9 程序跟踪宏单元(PTM):Cortex-A9 PTM为两款Cortex-A9处理器提供了兼容ARM CoreSight技术的程序流跟踪功能,能够对处理器中的实际指令流实现完全可视化的管理。Cortex-A9 PTM通过周期计数实施性能分析,可对所有代码分支和程序流变动进行跟踪管理。
Tegra 2 GeForce处理内核相关介绍
Tegra 2之所以强大除了采用两颗频率高达1Ghz的Cortex-A9处理器之外,另外一个非常重要的原因就是它在手持设备中引入了强大的Geforce处理器,借助于Geforce处理器的强大性能,可以为Tegra 2提升3D图形性能以及加速网页浏览等诸多功能。下面我们就来说说Tegra 2里面非常重要也非常强大的Geforce处理器。
八个核心构成GeForce处理器
Tegra 2的GeForce内核实现了功能强劲的管线顶点和像素处理架构,可通过各种特性降低功耗和提高图形质量,支持下一代移动 3D 游戏、流畅的高清视频播放、在线 Flash 游戏性能和高度响应的移动 GPU 加速用户界面,而不会影响 移动电源 预算。
OpenGL ES 2.0 图形处理管线
OpenGL ES 是一个标准的应用程序编程接口 (API),开发人员可使用它为智能电话、平板设备和便携式游戏设备等移动设备编写图形应用程序。OpenGL ES API是桌面OpenGL API 规范的一个子集,并且在图形应用程序和 GPU 硬件之间定义了一个灵活而强大的低级接口。最新的 OpenGL ES 2.x 规范针对完全可编程的 现代 GPU 管线,并将 API 的所有固定函数元素替换为可编程着色。大多数移动 GPU 架构均采用OpenGL ES API 标准,并且主要根据OpenGL ES API 的定义来实现逻辑处理管线。

OpenGL ES 2.0 逻辑图形处理管线
为了显示游戏或图形应用程序中定义的场景,应用程序开发人员必须先使用3D建模软件创建各种3D对象和角色模型。每个对象和角色都可以由数百、数千甚至数百万个相互连接的三角形网格构成,具体取决于所需的几何真实水平。

三维图像上的三角网格
接下来3D游戏软件或其他3D应用程序可以使用这些模型,并将它们置于模拟的3D场景或“3D世界”中。3D世界通过XYZ坐标系定义,并且3D对象或角色将放置在3D世界的特定位置上。对象中的每个三角形都由它的三个顶点定义,并且每个顶点都由代表其属性的一组数值构成,这些属性包括在3D世界中的XYZ位置、颜色值 (RGB)、阿尔法透明度、纹理坐标、法线等。随后,定义对象特定部分的顶点集将分组到一个顶点缓冲区中,后者类似于原始顶点流。
3D软件会向GPU驱动程序发起一个OpenGL ES调用,指向共享系统内存中的顶点缓冲区位置,从而允许 GPU 直接访问和处理数据。OpenGL管线的原型处理阶段发生在GPU中,并且会将传入顶点数据转换为可供GPU使用的格式和组织。随后,顶点会传递至Vertex着色器;这时,顶点着色器程序可以运行各种矩阵转换和光照计算,以便将顶点移至新的X、Y和Z位置,或者改变灯光值等属性。
转换后的顶点将被组装为原型, 然后光栅化阶段会将原型转换为像素片段,为像素着色器阶段做准备。现在,像素片段处于2D屏幕空间格式。像素着色阶段将运行像素着色器程序来处理每一个像素,并且可能会应用新的照明或颜色值、应用纹理或者执行各种其他操作来计算应用于像素的最终颜色值。
在典型的OpenGL管线中,随后会对各个像素运行Z缓冲测试,以确定是否比帧缓冲区中的相同屏幕位置中的已有像素更加接近观众的眼睛。如果确定新像素更加接近观众,它会取代帧缓冲区中的已有像素值,但如果它在已有像素后面,则会被丢弃。(注意:帧缓冲区可能位于与CPU共享的系统内存空间中,或者可能位于专用内存中,比如大多数独立 显卡 所使用的内存)。
如果可见像素的 Alpha 值指示它是部分透明的,那么它将与相同屏幕位置的帧缓冲区中的已有像素相混合。如果启用了抗锯齿,那么可以通过修改像素的颜色值来创建更加平滑的边缘,以便在写入帧缓冲区中之前减少锯齿效果。
Tegra 2 GeForce处理架构及功耗介绍
双核处理器或许让消费者对于Tegra 2的功耗问题比较担心,而双核处理器再加上GeForce内核,顿时让很多人对于Tegra 2的功耗问题更加怀疑和关注。的确,现在手机续航时间短已经成为 智能手机 的一个普遍现象,而Tegra 2同样也绕不开功耗的问题,下面我们就来看看Tegra 2中的GeForce内核架构以及它如何实现功耗的控制。
GeForce架构是一种固定函数管线架构,包括完全可编程的像素和顶点着色器,以及一个先进的纹理单元,可支持高品质的各向异性过滤。

Tegra 2处理器中的GeForce架构
GeForce包含四个像素着色器内核和四个顶点着色和内核,专用于高速顶点和像素处理。GPU管线在像素管线中使用FP20数据精度的80位RBGA像素格式,在顶点管线中则使用FP32 精度的80位RBGA像素格式。它还实现了一种独一无二和专有的各向异性过滤 (AF) 算法,该算法优于许多 台式机 GPU所使用的AF技术。该架构支持各种高级特性,例如高动态范围 (HDR) 照明、多重渲染目标 (MRT),并且两种纹理支持均不会带来功耗。该架构同时支持 DXT 和 ETC 纹理格式。
虽然GeForce架构是一种类似于OpenGL ES 2.0标准定义的管线架构,但它还包含一些特殊特性和自定义功能,可显著降低功耗并提供更高的性能和图形质量。Tegra 2移动处理器中实现的一些独特特性包括:
1、Early‐Z 支持,专用于过滤掉不可见的像素。
2、集成像素着色器 (Pixel Shader) 和混合单元 (Blend Unit),可实现编程灵活性和更高的性能。
3、像素缓存、纹理缓存、顶点和属性缓存,可减少内存操作。
4、独特的 5 倍覆盖采样抗锯齿 (CSAA) 技术,可在更低的内存带宽下实现更高的图像质量。
5、高级各向异性过滤 (AF),可实现高细节纹理。
6、内部开发的自定义内存控制器,可提高 GPU 性能和降低功耗。
7、实现超低功耗的众多电源管理功能。
Early–Z 技术
现代 GPU使用Z缓冲(也称作深度缓冲)来跟踪该场景中的可见但由于被其他像素遮挡而不需要显示的像素。每个像素在Z缓冲中都有相应的Z信息。单一3D帧会经过处理并转换为2D图像,以便在 显示器 上显示。该帧由从主机发送至GPU的顶点顺序流构成。多边形将由顶点流组配而成,并且会生成和呈现2D屏幕空间像素。
在指定时间单元(如1/60秒)内构建单一2D帧的过程中,多个多边形及其相应像素可能会覆盖相同的基于2D屏幕的像素位置。这经常被称作深度复杂性,并且现代游戏的深度复杂性可能达到 3、4 或者更高,即在覆盖相同 2D 屏幕位置的帧中呈现 3 个、4 个或更多像素。
想象首次在顶点流中处理构成某块墙的多边形(和由此产生的像素),以构建场景。接下来,处理位于墙前面的一把椅子的多边形和像素。对于特定的2D屏幕像素位置,观众最终只能看到一个像素,即椅子的像素或墙的像素。椅子离观众更近,因此会显示它的像素。(请注意,某些对象可能是透明的,并且透明对象的像素可以与背景中已有的不透明或透明像素相混合,或者与之前帧的帧缓冲区中的已有像素相混合)。

缓冲示例
OpenGL ES2.0 逻辑管线定义的针对各像素数据的 Z 比较会在像素经过像素着色器处理之后执行。在像素着色处理之后评估像素的问题在于,像素必须遍历几乎整个管线才能最终确定堵塞且需要丢弃的像素。对于拥有数百或数千处理步骤的复杂着色器程序,所有处理都浪费在永远不会显示的像素上! 更重要的是,在移动设备中,处理这些像素涉及 GPU 和共享系统内存之间大量事务。由于系统内存位于片外,因此内存操作会显著消耗电源并且会迅速耗尽电池电量。
GeForce中的Early‐Z实现是高端台式GeForce中所使用的实现的优化版本。Early‐Z操作会测试所有像素的Z深度并仅将可见像素传递给像素着色器块。通过执行Early‐Z操作,GeForce架构会仅获取通过Z测试的可用像素的Z值、颜色和纹理数据。Early‐Z效率极高,可准确检测出和丢弃隐藏像素。
Early‐Z处理的主要优势在于它不仅可通过减少GPU与片外系统内存之间的内存流量来显著降低功耗,而且速度也要快于其他 Z 比较算法。大多数情况下,高效的Early‐Z都可以识别和丢弃隐藏像素。但在极少数情况下,对于一些特殊场景程序员可能需要在像素着色完成之后隐藏像素。对于这些极少数的情况,GeForce管线实现了一种后期阶段深度计算,并混合于集成像素着色器和混合单元中。
像素和纹理缓存可减少内存操作
传统的OpenGL GPU管线指定纹理、深度、颜色等像素信息存储在系统内存(或帧缓冲存储器)中。在像素处理阶段,像素信息会在内存之间来回移动。这就需要在片外系统执行大量内存操作,从而消耗大量电能。GeForce架构实现了片上像素、纹理和属性缓存,以及独特的缓存管理算法,不仅可减少系统内存操作,而且还可以最大限度地利用这些缓存。
像素缓存用于存储像素的片上Z值和颜色值,并且适应于所有重复访问的像素,比如用户界面组件。此外,由于像素颜色和深度数据在许多其他图形场景图像中的良好空间及时间局部性,像素缓存可提供非常理想的缓存命中率,并且可降低访问系统内存的需要。
纹理数据具有良好的空间和时间局部性。 特定像素通常会在双线性过滤等纹理过滤操作过程中使用许多相同的纹理元素(像素)作为相邻像素,并且纹理经常在图像的至少一些帧中保持相同。因此,在片上缓存纹理数据有助于重用纹理数据以及显著减少通过访问系统内存来获取纹理数据。
覆盖面采样抗锯齿
锯齿是出现在图像上的锯齿状边缘,而这些区域本应显示为流畅的线条或边缘;抗锯齿 (AA)技术在计算机图形中用于让这些锯齿线条更加平滑。当高清晰度图像在较低分辨率的 显示器 上显示时,或者当较高分辨率的图像转换为较低分辨率的图像时便会出现锯齿效果。
通常,GPU使用多重采样抗锯齿(MSAA)和超级采样抗锯齿(SSAA)技术减少锯齿效果。在之前的抗锯齿技术中,覆盖面始终与“实际”采样类型相关联,而覆盖面采样与此不同。在SSAA中,每个实际采样都有其独特的颜色和Z值,并且在4xAA的情况下,着色器程序会运行四次,并获取四个纹理 ‐ 每个样本一个纹理(或者在多纹理的情况会更多)。采用4xAA时,帧缓冲区要比未使用抗锯齿时大四倍,并且会经过向下过滤,以创建最终像素颜色。
CSAA可以将简单的覆盖面采样从颜色/z/模板/覆盖面采样中解耦出来,进一步优化抗锯齿流程,从而较 MSAA和SSAA减少带宽和存储成本。CSAA 使用更多覆盖面样本来计算指定像素区域中的多边形的覆盖面水平,从而实现更高质量的抗锯齿效果,而不会由于处理额外的实际颜色和Z样本而产生内存和功耗成本。
高级各向异性过滤
各向异性过滤是一种用于提高表面上处于斜视角的纹理的图像质量的技术。 通常,屏幕上的每个像素都需要从内存的纹理贴图中获取多个纹理元素,经过过滤并应用于像素以改变其颜色。从正面看表面时(垂直于镜头或观众),通常会使用方形采样模式为每个像素采样同等数量的纹理元素。但是,在极端视角下(即屏幕上的图像从一个轴延伸至另一轴),从纹理贴图中为每个轴提取相同数量的样本会导致纹理沿延伸至水平方向的轴出现模糊。

通过各向异性过滤得到改善的纹理质量
可以看到接近地平线处的跑道部分的纹理细节出现了模糊。 各向异性过滤技术可以智能地沿该延伸轴采集更多的纹理样本,并保留沿该轴的纹理细节。GeForce支持高达16倍各向异性过滤。它采用自适应过滤算法和高效纹理缓存管理技术来提供高纹理质量,同时不会显著增加内存操作。
优化的内存控制器
Tegra 2)处理器包括经过全新设计的GPU和内存控制器(MC)内核,GPU内核的性能极度依赖于MC交付带宽的效率以及图形处理延迟要求。由于GPU和MC均采用了内部开发,因此MC针对GeForce的特定需求进行了高度调优,同时还增强了GPU性能和降低了功耗。
MC控制器设计的一些关键优化包括:
动态时钟速度控制(DCSC): DCSC支持内存控制器迅速提高工作频率以响应来自GPU内核的高级指标便于系统内存访问,以及在 GPU 完成其内存访问后将工作频率迅速降低至节能水平。由于采用了严密的内部设计流程,因此MC可以直接接入GPU内核硬件,主动预测GPU需求和管理其工作水平,以满足GPU需求。
以GPU为中心的内存仲裁: 系统内存是移动处理器中最宝贵的资源之一。CPU、GPU、视频和音频等各种内核都需要能够以高带宽、高度响应性的形式访问系统内存。MC实现了高级仲裁机制,可有效确保多个客户端访问系统内存。
MC内核具有关于来自GPU客户端的内存访问请求的类型和紧急性的深入信息,并且实现了一种高度优化的仲裁机制,可满足呈现器和几何请求对带宽的苛刻要求,以及满足对服务高优级级延迟敏感的显示和CPU请求在低延迟方面的苛刻要求。MC还掌握GPU内核生成的各请求的优先级的信息,并且可进一步优化其性能以满足这些请求的需求。
GPU请求分组: 片外系统内存设备在任何特定时间都只能打开特定数量的内存条。当内存的请求访问区不包含在当前打开的内存条中时,MC需要关闭当前打开的内存条,然后激活包含所需内存单元或区域的新内存条。这一过程不仅会影响延迟和带宽,同时对功耗的需要也较高。
GeForce掌握当前的系统配置,并且会对访问模式进行优化,而不会发起多个不同的访问内存子系统的不同部分中的随机内存条的内存请求。GPU可以将访问相同内存条的内存请求组合在一起。MC控制器还可以根据内存条访问模式对独立内存请求进行重新排序。这些功能可以提供更加高效的内存访问,并通过限制频繁的内存条切换来降低功耗。
高级电源管理
GeForce内核实现了一些可降低功耗的高级电源管理技术,包括:
多层频率门控: GPU实现了多层频率门控,可在空闲状态下关闭频率。它使用一种系统级功率控制算法来控制Tegra 2处理器中的所有8个内核的功率和频率。当功率控制逻辑检测到空闲状态的GPU内核时,它会通过频率门来控制送入GPU的主干线频率,从而将GPU的动态功耗有效限制至接近零毫瓦特的水平。当功率控制器检测到系统处于待机模式时,它会通过功耗门来控制GPU内核,从而将其功耗降低至接近零的水平。
本地电源管理功能: GPU内核具有一些电源管理功能,可进一步降低功耗。它实现了一些功能级频率门控机制,可通过频率门来控制GPU内核中的各种不同的空闲块。例如,当管线未执行任何顶点着色任务时,顶点着色器会采用频率门控并处于低功耗状态,直到接收到下一个顶点着色命令为止。同样,当像素着色器正在处理数学计算等不需要获取纹理的任务时,纹理单元可采用频率门控。此外,如果 GPU 仅仅刷新设备显示而非积极呈现,内存控制器可以借机将系统内存置于低功耗状态。

显示请求分组: GPU会对多个显示请求进行分组,并按批次向系统内存发出这些要求。然后,GPU 向内存控制器(通过计时器)通知下一个请求的时间。在发送GPU显示请求之间的空闲期,内存控制器会积极寻找机会将系统内存置于低功耗状态。
功耗优化的晶体管设计: GeForce内核还在晶体管级针对超低功耗进行了优化。非计时敏感的块使用了低漏晶体管,而需要高速运作的关键路径则采用了速度更高的晶体管。因此GeForce内核可以在不影响性能同时实现低功耗。
动态电压和频率缩放(DVFS): Tegra 2处理器还实现了一个先进的芯片级DVFS技术,该技术在任何时候都可以控制六个主要系统时钟的时钟频率,以及最多两个电压轨的电压水平。可以使用软件控制的设置来选择在DVFS控制下的时钟及电压轨。
DVFS的基本原理是为各种处理单元采用不同的内核频率和电压,从而控制功耗。半导体芯片的功耗与工作频率成正比关系,同时也与工作电压的平方成正比关系。当处理器未处理任何任务时,频率和电压可降至较低水平,从而大大降低空闲功耗。当Tegra 2中的8个内核中的任何一个检测到传入任务时,该事件将被报告给全局DVFS控制块,并且频率和电压会立即提高至合适的水平,以确保更高的性能。
DVFS 软件会智能地将电压和频率提高至最适合的水平,以满足应用程序的性能需求。DVFS算法可以非常精细地控制频率水平,并且可以按1MHz的增量来增加或降低频率。
Tegra 2其它处理核心介绍
2007年的时候NVIDIA花费3亿多美元收购了为 苹果 提供音频处理器的PortalPlayer公司,有了PortalPlayer公司强大的技术支持,NVIDIA为Tegra 2提供了更优秀的音频解码器,这一点从微软采用Tegra平台来打造Zune播放器也能看出来。

采用Tegra处理器的Zune播放器
第一代Tegra只能实现720P高清视频的编解码,而Tegra 2分别采用了独立的视频编码器和视频解码器设计。Tegra 2的视频编码处理单元可以实现每秒10帧的1080P H.264加速能力。NVIDIA称Tegra 2在1080P解码时,其功耗低于100毫瓦,并且声称其它1080P解码方案,在功耗方面至少需要1W,因为许多运算要依赖于CPU完成,这对于整个系统来说会有许多额外的附加运算。
独立的第三代图像处理器支持 1200万像素 的图像传感器,可以给手持设备带来非常强悍的图片和图像功能。Tegra 2采用的ARM 7控制芯片则负责处理器数据和电源管理。
PConline 评测 室总结
当年第一代Tegra出现的时候,我们苦于在市场上找不到基于Tegra的产品,甚至不觉得Tegra能在移动设备领域找到属于自己的空间。然而,当Tegra 2再次来到我们眼前的时候,却是以一种几乎席卷整个移动设备的姿态出现。的确,目前不仅在手机方面能够看到越来越多的Tegra 2产品,在平板电脑等其他移动终端设备上也有越来越多的产品出现,可以说Tegra 2不仅开创了手机双核的先河,也开创了属于NVIDIA的一个崭新的面貌。

基于Tegra 2处理器的移动设备越来越多应用也越来越广
不可否认的是借助于Tegra 2强大的性能,带来的Flash、高清视频以及3D游戏的加速,不仅可以让我们体验到更加畅快的应用体验,同时也能更加丰富和真实化我们的应用,目前NVIDIA推出了适用于Tegra 2处理器的Tegra Zone平台,相信随着Tegra 2设备的增加类似于Tegra Zone平台上的应用将会更多,而手机势必也将会成为全方位的移动多媒体设备。
Tegra 2(实际型号Tegra 250)基于台积电40nm工艺制造,共包含2.6亿个晶体管,核心尺寸约为49mm2,8.8mm BGA封装。按照NVIDIA的说法,Tegra 2共有8个独立的处理器核心(第一代Tegra为7个)。不过这8个核心并非我们在Intel/AMD CPU中看到的那些传统意义上的处理器核心,而是各自有其专门用途。
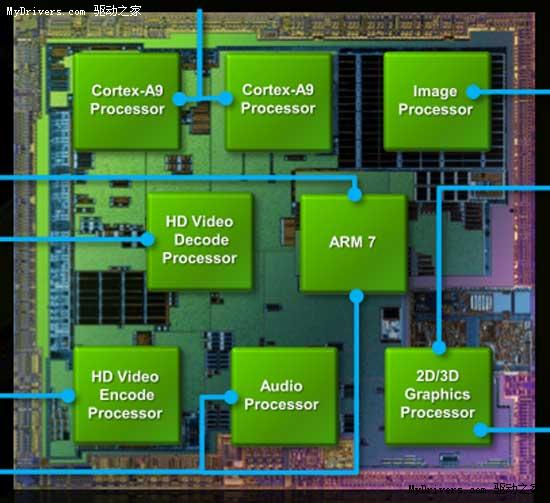
首先的两个核心,实际上来自于一颗双核ARM Cortex-A9处理器,最高频率1GHz。在第一代Tegra中,NVIDIA使用的是单核心的ARM 11,而此次则跳过了Cortex-A8这一代,直接升级双核版Cortex-A9,性能备受期待。NVIDIA表示,该处理器的性能是现有智能手机的10倍,上代Tegra的4倍。
余下的六颗核心,则分别对应不同的多媒体应用。包括一个音频解码核心,一个支持1080p H.264硬件加速的视频解码核心,一个高清视频编码核心,一个最高支持1200万像素摄像头的图片/照片处理核心,一个GeForce 2D/3D图形核心以及一个用于芯片内部数据/功耗管理的ARM 7处理器核心。

- 双核不可阻挡!首款双核处理器Tegra2详解
- tegra2
- ERP平台化:不可阻挡的趋势
- 不可阻挡的谷歌拼音
- 不可阻挡的谷歌拼音
- 不可阻挡的谷歌拼音
- HTML5 未来不可阻挡的力量
- HTML5 未来不可阻挡的力量
- Linux基金会负责人称MeeGo为不可阻挡的力量
- 移动电竞即将成为不可阻挡的大趋势
- 再告菲氏微积分的徒子徒孙,无穷小放飞互联网不可阻挡
- 拨开浮云见月明 详解手机双核处理器
- 什么是双核处理器
- 什么是双核处理器
- 双核处理器
- 双核处理器介绍
- 什么是双核处理器
- 双处理器和双核处理器,谁强?
- [USB] VBUS
- 软件设计原则----依赖倒置原则(DIP)
- MySQL DELAY_KEY_WRITE
- 取模与取余的区别
- myapps平台中对于外部映射表,如何插入一条记录?
- 双核不可阻挡!首款双核处理器Tegra2详解
- 眼睛直观感受几种常用排序算法
- 单元测试实践的主要问题与解决(8)
- 重写"Hello world!"
- Hibernate -annotation 学习笔记
- 如何开发出成功的iPhone游戏
- 软件设计原则----接口隔离原则(ISP)
- 16.4.1 安全地处理状态
- 如何查看和启动oracle监听

