EXCEL IDA数据挖掘技术
来源:互联网 发布:软件许可使用授权书 编辑:程序博客网 时间:2024/05/01 19:43
一、无指导聚类
1. 选择算法
这里我们选择ESX,他具有三层结构,能够适应无指导和有指导的数据挖掘分析。

2. 设置instance similarity相似指数
越趋近于0,实例所能举出来的类就愈少。通过这个参数的控制我们能够得到想要数量的类。另一个参数real-valuedtolerance还不太清楚其中的含义。

3. 观察类数
设定参数后会出现聚类所得的类的个数,我们可以作为参考。不合适我们可以重新设置参数。

4. 数据挖掘过程
其中的算法不可见。
5. 规则产生器,能够产生相关的规则。
Minimum correctness value是指设置准确率下限,例如:准确率表示符合(Income Range = "30-40,000",则为Class 2)的概率为100%。(符合条件和结论的事件数/符合条件的事件数)
Minimum rule coverage是指覆盖率下限,例如:覆盖率是指符合Income Range = "30-40,000"的实例在Class2中有4条,Class2有5条实例,所以,覆盖率为80%。(符合条件和结论的事件数/事件总数)
Attribute significance 是选择具有较高的Predictiveness的属性进行规则生成。一般会先设置一个比较高的值,如果没有理想的结果,就放宽条件。

Scope:
1) all rules

2) covering set rules 覆盖集规则 为什么只出现了关于Income Range的规则,而没有其他 Instancesource

1) all class instance
2) most typical class instance 不太明白有什么区别,使显示典型实例,还是只用典型事例
6. Sheet1 RES SUM
1)第一部分
主要表示了分出的类的总体信息。
Res.score表示的是类内的实例间的相似度,是聚类是否好的的重要指标,一般情况下ClassN的数值要大于domain的数值,domain表示的是整体的相似度。
No. of Inst.表示类中实例的数量。
Cluster Quality:表示分类的质量

2)第二部分
分类数据汇总
Number of Classes:表示分类的个数
Domain Res. Score:表示所有实例之间的相似度
Categorical Attribute Summary:是说明分类数据的总结
Predictability = Frequency / Numberof instance 能够表示这个属性值出现的频率,值越大越能够表明,这个属性值经常出现。这里主要是表示域级预测能力得分。例如:80%信用卡持有者没有信用卡保险,60%的信用卡持有者利用了寿险促销。如果域级预测能力指标接近于100%,说明这个属性不可能对有指导和无指导的学习有效,因为大部分实例中属性值相同。但在决定孤立点的时候要谨慎处理。

3)第三部分
DOMAIN STATISTICS FOR NUMERICAL ATTRIBUTES是对数值型数据的汇总,这里给出了每个数据的中值和标准差。
Domain表示总体的均值和标准差
Attribute Significance = 最大类平均值– 最小类平均值 / 域标准偏差值。说明的属性的重要性,数值越高说明对于分类越有利。通常低于0.25的属性在区分两个类的时候没有很大价值

4)第四部分
这里说明了每个类中最典型的数据,这些数据一定是包含在数据集中的
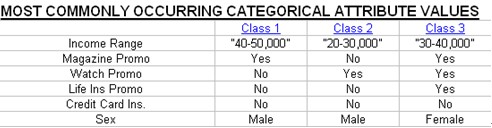
7. Sheet1 RES CLS
这张表对于每个类的具体信息进行了描述,这里仅举一个类的例子。
Class: 是说明类的标号
Total Number ofInstances:说明类中实例的个数
ClassResemblance Score:类内部的相似性指数,指数越大,分类效果越好。
Most TypicalInstances:举例了类内部最典型的实例,这些实例必定在实例集中
Least TypicalInstances: 举例了类内部最不典型的实例,这些实例必定在实例集中
Typicality说明典型事例和非典型实例的典型指数,指数越大,越典型
CategoricalAttribute Summary:分类数据汇总
Predictability= 该类内具有该属性的实例个数/ 该类内实例的总数,越大表明在类内部这个属性值经常出现
Predictability= 该类内具有该属性的实例个数/ 举有该属性值的所有实例个数,表明这个属性值,落在这个类中的概率,但是有什么意义呢
Predictability,Predictiveness都等于1,则属性值被认为是类成员资格的充分必要条件。Predictability等于1,Predictiveness不等于1,则类中所有属性值都为特定值,而别的类中同样存在这样的属性值。Predictability不等于1,Predictiveness等于1,则等于特定属性值的实例都在类中,二类中可能存在其他的属性值。
通常至少应该有一个Predictiveness较高的分类属性作为输入属性,具有较低预测性值的分类指标标为不适用。这里应该是指每一类中的Predictiveness都较低的吧,那高如何衡量呢。
AttributeValues Necessary and Sufficient for Class Membership:表明了该类的充分必要属性,即Predictability,Predictability都大于0.8的属性值
AttributeValues Highly Sufficient for Class Membership:充分条件,Predictiveness>0.8
AttributeValues Highly Necessary for Class Membership:必要条件,Predictability>0.8

8. Sheet1 RUL TYP
将各个实例进行了分类,并将每一类放在一起,给出了每个实例的典型性数值作为分类好坏的标准。实例典型性指标表示了与其他实例的平均相似度。

9. Sheet1 RES RUL
Accuracy:表示对于这个规则百分之多少是正确的,有百分之多少被正确分类。
Coverage:表示规则有百分之多少适用于该类,类中百分之多少是该属性值
Scope;Instance Source;MinimumCorrectness;Percent Covered;Attribute Significance都不太明白什么意思。

二、有指导学习
1. 选择算法
数据集中必须有一个数据项被设置为O,才能够进行有指导的学习,输出分类按照O的属性值进行分类。
2. 设置训练实例数
设置合理的训练实例数,能够有效地训练模型,使得模型适应输入信息,为预测做准备。另一个参数real-valuedtolerance还不太清楚其中的含义。

3. 数据挖掘过程
其中的算法不可见。
4. 规则产生器,能够产生相关的规则。
具体形势与无指导的聚类相同

5. Sheet1 RES MTX
计算矩阵能够表示测试实例集中实际的分类状况和计算的分类状况之间的差距,并能够计算总体的正确率,正确率越高模型越准确。Error: Upper Bound;Error: Lower Bound的具体含义还不是特别明白

6. Sheet1 RES TST
实例集分类情况,但是比原始表格多了两列,一个是实际值,一个是计算值。带星号的表示正确分类的实例。

7. 其他表格同无指导聚类
三、有指导的神经网络
1. 选择算法
神经网络分析必须全部转化为数值型数据,并且有O型数据。这里我们选择反向传播神经网络。具体算法不可见。
2. 设置参数
Hidden layer是指隐藏层的节点数目。这里默认有两个隐藏层。
Learning rate:学习效率,设定了每次学习的步伐。
Ecochs:设置学习周期,若在高设置周期中没有找到符合条件的模型,则停止学习。
Convergence:设置的误差参数,一旦误差小于这个值,则停止学习。
Traininginstance:设置了训练继的实例个数,剩下的就为检验集。

3. 数据挖掘过程

4. Sheet1 RES NN
1)第一部分
对于各属性的最大值、最小值、均值、方差进行了整理。
2)第二部分
对于每一个测试集中的实例进行整理,对比实际数值和计算出的数值之间的差距。
首先,对于每一个输入值,都需要进过规范化,才能在最终的模型中使用。
RMS = (∑|C-R|2)-2,C是实际值,R是计算值
MAS = ∑|C-R|
上面两者都表示了测试集实例实际值与计算值之间的误差和。误差越大预测越不准。

二、 无指导的神经网络
1. 选择算法
神经网络输入数据必须为数值型,这里利用了无指导神经网络聚类。

2. 设置参数
Output layer指的是输出层网络的大小。具体行列表示什么不清楚。
Clusters:说明想要聚成类的个数。
其他参数与神经网络的参数相同。

3. 数据挖掘

4. Sheet1 RES NN
对于所有输入属性的汇总,输出了最大值、最小值、均值、标准差。
Root meansquared error:表示根节点的均值平方误差,越大越不好。

5. Sheet1 RES NN DET
对所有数据的分类,最后一列标出了属于的类。

- EXCEL IDA数据挖掘技术
- 数据挖掘 -- Web挖掘技术
- Excel数据挖掘插件
- 数据挖掘技术
- 数据挖掘技术简介
- 数据挖掘技术
- 数据挖掘技术
- 数据挖掘技术简介
- 数据挖掘技术简介
- 《数据挖掘技术》试题
- 数据挖掘技术简介
- 数据挖掘技术浅析
- 数据挖掘技术简介
- 浅析数据挖掘技术
- 数据挖掘分类技术
- 数据挖掘技术简介
- 数据挖掘分类技术
- 数据挖掘分类技术
- MyEclipse8.5 和 Eclipse中安装findbugs插件
- Linux-world-2012-January->13(error: 'S3C24X0_GPIO' has no member named 'GPACON')
- git 小记
- VmWare下安装RHEL 5.4(配置Oracle安装环境)
- hdoj 2571 命运 【DP】【水】
- EXCEL IDA数据挖掘技术
- 如何截取home key及截取后的显示问题
- JS获取当前对象大小以及屏幕分辨率等
- oracle的锁与并发机制
- windows open command here
- 文件被数字签名策略拒绝
- 鼓之反击评测:休闲为主,音乐为辅
- html5-如何加载资源,在canvas上drawimage?
- c格式符


