正则表达式实例
来源:互联网 发布:淘宝开店诈骗 编辑:程序博客网 时间:2024/05/22 05:01
From: http://www.usidcbbs.com/read-htm-tid-1457.html
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]\d{5}(?!\d)
评注:中国邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
评注:中国的身份证为15位或18位
匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
评注:最基本也是最常用的一些表达式
许多包含一定特性的工具使阅读和编写正则表达式变得容易了,但是它们又很不符合习惯。对于很多程序员来说,书写正则表达式就是一种魔法艺术。他们坚持自己所知道的特征并持有绝对乐观的态度。如果你愿意采用本文所探讨的五个习惯,你将可以让你设计的正则表达式经受的住反复试验。
本文将使用Perl、PHP和Python语言作为代码示例,但是本文的建议几乎适用于任何替换表达式(regex)的执行。
一、使用空格和注释
对于大部分程序员来说,在一个正则表达式环境里使用空格和缩进排列都不成问题,如果他们没有这么做一定会被同行甚至外行人士看笑话。几乎每个人都知道把代码挤在一行会难于阅读、书写和维护。对于正则表达式又有什么不同呢?
大部分替换表达式工具都具有扩展的空格特性,这允许程序员把他们的正则表达式扩展为多行,并在每一行结尾加上注释。为什么只有少部分程序员利用这个特性呢?Perl 6的正则表达式默认就是扩展空格的模式。不要再让语言替你默认扩展空格了,自己主动利用吧。
记住扩展空格的窍门之一就是让正则表达式引擎忽略扩展空格。这样如果你需要匹配空格,你就不得不明确说明。
在Perl语言里面,在正则表达式的结尾加上x,这样“m/foo bar/”变为如下形式:
m/
foo
bar
/x
在PHP语言里面,在正则表达式的结尾加上x,这样“"/foo bar/"”变为如下形式:
"/
foo
bar
/x"
在Python语言里面,传递模式修饰参数“re.VERBOSE”得到编译函数如下:
pattern = r'''
foo
bar
'''
regex = re.compile(pattern, re.VERBOSE)
处理更加复杂的正则表达式时,空格和注释就更能体现出其重要性。假设下面的正则表达式用于匹配美国的电话号码:
\(?\d{3}\)? ?\d{3}[-.]\d{4}
这个正则表达式匹配电话号码如“(314)555-4000”的形式,你认为这个正则表达式是否匹配“314-555-4000”或者“555- 4000”呢?答案是两种都不匹配。写上这么一行代码隐蔽了缺点和设计结果本身,电话区号是需要的,但是正则表达式在区号和前缀之间缺少一个分隔符号的说明。
把这一行代码分成几行并加上注释将把缺点暴露无疑,修改起来显然更容易一些。
在Perl语言里面应该是如下形式:
/
\(? # 可选圆括号
\d{3} # 必须的电话区号
\)? # 可选圆括号
[-\s.]? # 分隔符号可以是破折号、空格或者句点
\d{3} # 三位数前缀
[-.] # 另一个分隔符号
\d{4} # 四位数电话号码
/x
改写过的正则表达式现在在电话区号后有一个可选择的分隔符号,这样它应该是匹配“314-555-4000”的,然而电话区号还是必须的。另一个程序员如果需要把电话区号变为可选项则可以迅速看出它现在不是可选的,一个小小的改动就可以解决这个问题。
二、书写测试
一共有三个层次的测试,每一层为你的代码加上一层可靠性。首先,你需要认真想想你需要匹配什么代码以及你是否能够处理错误匹配。其次,你需要利用数据实例来测试正则表达式。最后,你需要正式通过一个测试小组的测试。
决定匹配什么其实就是在匹配错误结果和错过正确结果之间寻求一个平衡点。如果你的正则表达式过于严格,它将会错过一些正确匹配;如果它过于宽松,它将会产生一个错误匹配。一旦某个正则表达式发放到实际代码当中,你可能不会两者都注意到。考虑一下上面电话号码的例子,它将会匹配“800-555-4000 = -5355”。错误的匹配其实很难发现,所以提前规划做好测试是很重要的。
还是使用电话号码的例子,如果你在Web表单里面确认一个电话号码,你可能只要满足于任何格式的十位数字。但是,如果你想从大量文本里面分离电话号码,你可能需要很认证的排除不符合要求的错误匹配。
在考虑你想匹配的数据的时候,写下一些案例情况。针对案例情况写下一些代码来测试你的正则表达式。任何复杂的正则表达式都最好写个小程序测试一下,可以采用下面的具体形式。
在Perl语言里面:
#!/usr/bin/perl
my @tests = ( "314-555-4000",
"800-555-4400",
"(314)555-4000",
"314.555.4000",
"555-4000",
"aasdklfjklas",
"1234-123-12345"
);
foreach my $test (@tests) {
if ( $test =~ m/
\(? # 可选圆括号
\d{3} # 必须的电话区号
\)? # 可选圆括号
[-\s.]? # 分隔符号可以是破折号、空格或者句点
\d{3} # 三位数前缀
[-\s.] # 另一个分隔符号
\d{4} # 四位数电话号码
/x ) {
print "Matched on $test\n";
}
else {
print "Failed match on $test\n";
}
}
在PHP语言里面:
<?php
$tests = array( "314-555-4000",
"800-555-4400",
"(314)555-4000",
"314.555.4000",
"555-4000",
"aasdklfjklas",
"1234-123-12345" );
$regex = "/
\(? # 可选圆括号
\d{3} # 必须的电话区号
\)? # 可选圆括号
[-\s.]? # 分隔符号可以是破折号、空格或者句点
\d{3} # 三位数前缀
[-\s.] # 另一个分隔符号
\d{4} # 四位数电话号码
/x";
foreach ($tests as $test) {
if (preg_match($regex, $test)) {
echo "Matched on $test
;";
}
else {
echo "Failed match on $test
;";
}
}
?>;
在Python语言里面:
import re
tests = ["314-555-4000",
"800-555-4400",
"(314)555-4000",
"314.555.4000",
"555-4000",
"aasdklfjklas",
"1234-123-12345"
]
pattern = r'''
\(? # 可选圆括号
\d{3} # 必须的电话区号
\)? # 可选圆括号
[-\s.]? # 分隔符号可以是破折号、空格或者句点
\d{3} # 三位数前缀
[-\s.] # 另一个分隔符号
\d{4} # 四位数电话号码
'''
regex = re.compile( pattern, re.VERBOSE ) for test in tests:
if regex.match(test):
print "Matched on", test, "\n"
else:
print "Failed match on", test, "\n"
运行测试代码将会发现另一个问题:它匹配“1234-123-12345”。
理论上,你需要整合整个程序所有的测试到一个测试小组里面。即使你现在还没有测试小组,你的正则表达式测试也会是一个小组的良好基础,现在正是开始创建的好机会。即使现在还不是创建的合适时间,你也应该在每次修改以后运行测试一下正则表达式。这里花费一小段时间将会减少你很多麻烦事。
三、为交替操作分组
交替操作符号( )的优先级很低,这意味着它经常交替超过程序员所设计的那样。比如,从文本里面抽取Email地址的正则表达式可能如下:
^CC: To:(.*)
上面的尝试是不正确的,但是这个bug往往不被注意。上面代码的意图是找到“CC:”或者“To:”开始的文本,然后在这一行的后面部分提取Email地址。
不幸的是,如果某一行中间出现“To:”,那么这个正则表达式将捕获不到任何以“CC:”开始的一行,而是抽取几个随机的文本。坦白的说,正则表达式匹配 “CC:”开始的一行,但是什么都捕获不到;或者匹配任何包含“To:”的一行,但是把这行的剩余文本都捕获了。通常情况下,这个正则表达式会捕获大量 Email地址,所有没有人会注意这个bug。
如果要符合实际意图,那么你应该加入括号说明清楚,正则表达式如下:
(^CC:) (To:(.*))
如果真正意图是捕获以“CC:”或者“To:”开始的文本行的剩余部分,那么正确的正则表达式如下:
^(CC: To:)(.*)
这是一个普遍的不完全匹配的bug,如果你养成为交替操作分组的习惯,你就会避免这个错误。
四、使用宽松数量词
很多程序员避免使用宽松数量词比如“*?”、“+?”和“??”,即使它们会使这个表达式易于书写和理解。
宽松数量词可以尽可能少的匹配文本,这样有助于完全匹配的成功。如果你写了“foo(.*?)bar”,那么数量词将在第一次遇到“bar”时就停止匹配,而不是在最后一次。如果你希望从“foo###bar+++bar”中捕获“###”,这一点就很重要。一个严格数量词将捕获“###bar++ +”。;),这将会带来很大麻烦。如果你使用了宽松数量词,你只要花上很少的时间组装字符种类就能产生新的正则表达式。
在你知道你要捕获文本的环境结构时,宽松数量词是具有很大价值的。
五、利用可用分界符
Perl 和PHP语言常常使用左斜线(/)来标志一个正则表达式的开头和结尾,Python语言使用一组引号来标志开头和结尾。如果在Perl和PHP中坚持使用左斜线,你将要避免表达式中的任何斜线;如果在Python中使用引号,你将要避免使用反斜线(\)。选择不同的分界符或引号可以允许你避免一半的正则表达式。这将使得表达式易于阅读,减少由于忘记避免符号而潜在的bug。
Perl和PHP语言允许使用任何非数字和空格字符作为分界符。如果你切换到一个新的分界符,在匹配URL或HTML标志(如“[url]http://
昨天Snopo问我如何写一段正则表达式,来提取sql的条件语句。解答之余,想写一篇文章介绍一下经验。文题本来是《如何构造复杂的正则表达式》,但是觉得有些歧义,就感觉正则式本来很简单,我在教人如何将它小事化大一样。正好相反,我的本意是说,即使复杂的正则式也不怕,找出合适的方法,将其构造出来。
避重就轻
Snopo给出的文本是这样的:
or and name='zhangsan' and id=001 or age>20 or area='%renmin%' and like,问,如何提取其中正确的SQL查询语句。简要分析可知,中间部分是合乎要求的,只是两端的有若干个
like, or, and。构造能够解析合乎SQL语法的查询语句的正则表达式,应该是比较复杂的。可是,对于具体的问题,也可以更简单。上述的不良构的SQL语句,应该是使用程序自动生成的,它的两端会有一些不符合题意的文本。只要将这些文本去除就可以了。于是,我写出了正则表达式:
s/^(?:(?:or|and|like)\s*)+|\s*(?:(?:or|and|like)\s*)+$//mi;,这样就把多行字串首尾的like, or, and以及可能的空白字符全部去掉了,剩下的内容即为所求。
分而治之
答案发过去之后,Snopo显然不是很满意这种“偷懒”的办法。他继续问道,能否写出正则式,用来匹配合符SQL语法要求的条件查询语句?(只考虑where部分即可,不必写完整的select。)
的确,从快速解决问题的角度来说,只要能够行之有效地解决,用什么办法都可以;不过从学习知识的角度来说,不避重就轻,而是刨根问底,才是正途。既如此,就看一下如何使用正则,将该SQL查询语句解决掉。
最简单的查询语句,应该是真假判断,即
where 1; where True; where false,等等。 这样的语句使用正则式,直接/(?:-?\d+|True|False)/i。稍复杂些的单条语句,可以是左右比较,即
1name like 'zhang%', 或 age>25 ,或 work in ('it', 'hr', 'R&D')。将其简单化,结构就变为
A OP B。其中A代表变量,OP代表比较操作符,B代表值。
- A: 最简单的A,应该是
\w+。考虑到实际情况,变量包含点号或脱字符,例如`table.salary`,可以记为/[\w.`]+/。这是比较笼统的细化。如果要求比较苛刻,还可以做到让脱字符同时在左右两边出现(条件判断)。- OP: Where 常用的几种关系比较为:
=, <>, >, <, >=, <=, Between, Like, in。使用简单的正则描述之,成为:/(?:[<>=]{1,2}|Between|Like|In)/i。- B: B 的情况又可分为3种:变量,数字,字符串,列表。为简单起见,这里就不考虑算术表达式了。
- 变量的话,直接延用A的定义即可。不赘述。
- 数字:使用
/\d+/来定义。不考虑小数和负数了。- 字符串:包括单引号字串和双引号字串。中间可以包括被转义的引号。我写了一个符合这一要求的引号字串正则表达式,形如:
/(['"])(?:\\['"]|[^\\1])*?\1/。不过,由于它只是庞大机器的一个零件,这样写的风险是极其大的。首先,它使用了反向引用;其次,该反向引用使用了全局的反向引用编号。我写了自动生成全局编号的函数,来解决这一问题。不过,这里谈细节是不是太深入了。应该先谈框架,再说细节才对。不应该一入手就陷进细节的汪洋大海。- 列表:列表是形如
(1, 3 , 4) 或 ("it","hr", "r&d")之类的东东,它由简单变量以逗号相连,两边加上括号组成。列表的单项以I表示,它代表 数字|字符串。此时,列表就变为:/\(I(?:,I)*?\)/。它表示,左括号,一个I,一系列由逗号、I组成的其它列表项(0个或多个),右括号。简单起见没有考虑空白字符。- 至此,可以总结出单条语句的正则框架:
S =~ /A OP B/i。S在此代表单条语句。更为复杂的是多条语句,可以由单条语句组成,中间使用 and 或 or 连接。合理地构造单条语句,将其稳定地编制为多条语句,任务就完成了。
沿用上面的示例,以S代表单条语句,那么复合语句C就是
C =~S(?:(?:or|and) S)*?/。至此,一个初具规模的条件语句解析器就诞生了。下面以python为例,一步一步实现出来。
Python实现
重申一句:虽然给出了实现,但是仍请注重思路,忽略代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65#!/usr/bin/python
# -*- coding: utf-8 -*-
#
#author: rex
#blog: http://iregex.org
#filename test.py
#created: 2010-08-06 17:12
#generage quoted string;
#including ' and " string
#allow \' and \" inside
index=0
def gen_quote_str():
global index
index+=1
char=chr(96+index)
return r"""(?P['"])(?:\\['"]|[^'"])*?(?P=quote_%s)"""% (char, char)
#simple variable
def a():
return r'[\w.`]+'
#operators
def op():
return r'(?:[<>=]{1,2}|Between|Like|In)'
#list item within (,)
#eg: 'a', 23, a.b, "asdfasdf\"aasdf"
def item():
return r"(?:%s|%s)" % (a(), gen_quote_str())
#a complite list, like
#eg: (23, 24, 44), ("regex", "is", "good")
def items():
return r"""\( \s*
%s
(?:,\s* %s)* \s*
\)""" % (item(), item())
#simple comparison
#eg: a=15 , b>23
def s():
return r"""%s \s* %s \s* (?:\w+| %s | %s )""" % (a(), op(), gen_quote_str(), items())
#complex comparison
# name like 'zhang%' and age>23 and work in ("hr", "it", 'r&d')
def c():
return r"""
(?ix) %s
(?:\s*
(?:and|or)\s*
%s \s*
)*
""" % (s(), s())
print "A:\t", a()
print "OP:\t", op()
print "ITEM:\t", item()
print "ITEMS:\t", items()
print "S:\t", s()
print "C:\t", c()该代码在我的机器上(Ubuntu 10.04, Python 2.6.5)运行的结果是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23A: [\w.`]+
OP: (?:[<>=]{1,2}|Between|Like|In)
ITEM: (?:[\w.`]+|(?P<quote_a>['"])(?:\\['"]|[^'"])*?(?P=quote_a))
ITEMS: \( \s*
(?:[\w.`]+|(?P<quote_b>['"])(?:\\['"]|[^'"])*?(?P=quote_b))
(?:,\s* (?:[\w.`]+|(?P<quote_c>['"])(?:\\['"]|[^'"])*?(?P=quote_c)))* \s*
\)
S: [\w.`]+ \s* (?:[<>=]{1,2}|Between|Like|In) \s* (?:\w+| (?P<quote_d>['"])(?:\\['"]|[^'"])*?(?P=quote_d) | \( \s*
(?:[\w.`]+|(?P<quote_e>['"])(?:\\['"]|[^'"])*?(?P=quote_e))
(?:,\s* (?:[\w.`]+|(?P<quote_f>['"])(?:\\['"]|[^'"])*?(?P=quote_f)))* \s*
\) )
C:
(?ix) [\w.`]+ \s* (?:[<>=]{1,2}|Between|Like|In) \s* (?:\w+| (?P<quote_g>['"])(?:\\['"]|[^'"])*?(?P=quote_g) | \( \s*
(?:[\w.`]+|(?P<quote_h>['"])(?:\\['"]|[^'"])*?(?P=quote_h))
(?:,\s* (?:[\w.`]+|(?P<quote_i>['"])(?:\\['"]|[^'"])*?(?P=quote_i)))* \s*
\) )
(?:\s*
(?:and|or)\s*
[\w.`]+ \s* (?:[<>=]{1,2}|Between|Like|In) \s* (?:\w+| (?P<quote_j>['"])(?:\\['"]|[^'"])*?(?P=quote_j) | \( \s*
(?:[\w.`]+|(?P<quote_k>['"])(?:\\['"]|[^'"])*?(?P=quote_k))
(?:,\s* (?:[\w.`]+|(?P<quote_l>['"])(?:\\['"]|[^'"])*?(?P=quote_l)))* \s*
\) ) \s*
)*请看匹配效果图:
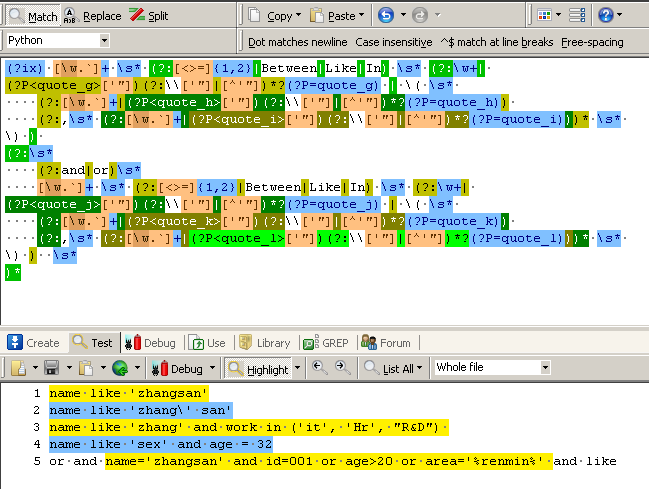
算术表达式
我记得刚才好像提到“为简单起见,这里就不考虑算术表达式了”。不过,解析算术表达式是个非常有趣的话题,只要是算法书,都会提及(中缀表达式转前缀表达式,诸如此类)。当然它也可以使用正则表达式来描述。
其主要思路是:
1
2
3expr -> expr + term | expr - term | term
term -> term * factor | term / factor | factor
factor -> digit | ( expr )以及代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#!/usr/bin/python
# -*- coding: utf-8 -*-
#
#author: rex
#blog: http://iregex.org
#filename math.py
#created: 2010-08-07 00:44
integer=r"\d+"
factor=r"%s (?:\. %s)?" % (integer, integer)
term= "%s(?: \s* [*/] \s* %s)* " % (factor, factor)
expr= "(?x) %s(?: \s* [+-] \s* %s)* " % (term, term)
print expr看一下它的输出和匹配效果图:
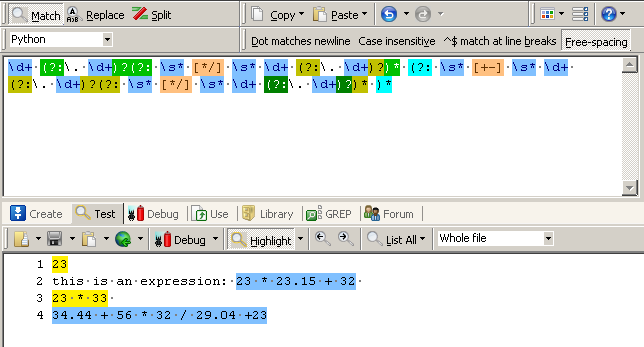
小贴士
- 如果不用复杂的正则式就能解决问题,一定不要用。
- 如果必须写比较复杂的正则式,请参考以下原则。
- 从大处着眼,先理解待解析的文本的整体结构是什么样子,划分为小部件;
- 从细处着手,试图实现每一个小部件,力求每一部分都是完整、坚固的,且放在全局也不会冲突。
- 合理组装这些部件。
- 分而治之的好处:只有某个模块出错,其它部分没错时,可以迅速定位错误,消除BUG。
- 谨慎使用捕获括号,除非你知道自己在做什么,知道它会有什么副作用,以及是否有可行的解决措施。对于短小的正则式来说,一两个多余的括号是无伤大雅的;但是对于复杂的正则式来说,一对多余的括号可能就是致命的错误。
- 尽量使用free-space模式。此时你可以自由地添加注释和空白字符,以便提高正则表达式的可读性。
- 常用正则表达式实例
- 常用正则表达式实例
- 常用正则表达式实例
- php正则表达式实例
- 正则表达式判断实例
- 常用正则表达式实例
- 正则表达式实例
- 【PHP】正则表达式实例
- 常用正则表达式实例
- 正则表达式 实例
- 正则表达式 实例2
- JAVA正则表达式实例
- javascript正则表达式实例
- 正则表达式具体实例:
- 正则表达式,awk实例
- 正则表达式实例
- 正则表达式常用实例
- 正则表达式JAVA实例
- 使用递归方式遍历指定磁盘路径下的文件及文件夹
- POJ 1484 Blowing Fuses(我的水题之路——我必须在心中牢记这次惨痛的教训)
- 学JAVA IO先学装饰模式
- POJ 1504 Adding Reversed Numbers(我的水题之路——逆向数高精度加法)
- C语言复习之结构体和指针
- 正则表达式实例
- java 静态代理与动态代理(代理模式)
- 关于JSF2.0的Resources
- web打印
- Linux中samba配置和windows映射Linux驱动盘
- 写在ACM之路之前
- 设计模式之原则
- 编程学习导图
- 因oracle用户密码包含特殊字符导致sqlplus无法正常登录问题


