协同过滤之Slope One算法
来源:互联网 发布:vue.js中自定义指令 编辑:程序博客网 时间:2024/05/17 03:41
纯笔记,直接从维基百科上翻译过来的:http://en.wikipedia.org/wiki/Slope_One
slope-one算法是基于评分的item-based算法中最简单的一种了,它的思想非常简单,但在很多场合却有很好的效果。但是slope one只适用于有评分的情况,对于二值评分,如商品的有无购买,这种算法是不适用的。
通常的item-based算法是基于用户的评分历史及其他用户对item的评分来预测用户对item的评分的。举个例子,如果一个用户给重塑的专辑评了5分,那么他会不会对PK14同样也评5分呢?
处理这种问题时,我们通常是根据用户的历史评分记录,使用线性回归 f(x) = ax + b来拟合。因此,如果item的数量为1000,那么可能导致有1000000种回归方式,2000000个回归变量。这种方法会造成严重的过度拟合(因为回归是基于用户自身的),除非我们选择那些许多用户有共同评分的item来进行计算(即协同过滤)。
另外一种方法是,我们把回归直线简化成 f(x) = x + b。这样就只剩一个回归变量了(slope one)。
slope one算法解释:
假设有A,B两位用户,他们对item I,J的评分如下:
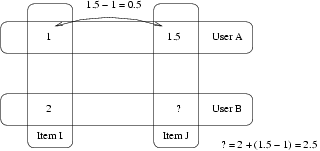
用户A对I和J均有评分,用户B只对I有评分,现在需要预测用户B对J的评分。
使用slope-one算法,结果很简单:用户A对I和J的评分差为:1.5 - 1 = 0.5,因此用户B对J的评分 = 2 + 0.5 = 2.5
再看另一个例子:
在这种情况下,用户对多个item都有评分历史,我们只需要简单地根据对同一个item共同评分的用户数做一个加权平均即可。这里总共有2位用户同时对item1和item2做过评分,有一位用户同时对item2和item3做过评分,因此C对item 1的评分为:
(2 * 2.5 + 1 * 8) / (2 + 1) = 4.33
给定n个item,slope one在实现上只需要计算和存储item间的平均分差以及共同评分的用户数,总共有n*n对item。
算法复杂度:
若有n个item,m个用户,以及N个评分,则每两个item之间的平均分差,需要n*(n-1)/2的单位存储,以及最多m*n*n次计算。若用户最多对y个item有评分,则计算平均分差的时间复杂度为 n*n + m*y*y。若一个用户有x个评分,则预测一次评分需要x次计算,预测用户的所有评分需要(n-x)*x次计算。
一种精简空间的方法是划分数据(个人理解是,将评分数据根据item进行存储)或使用稀疏存储,即忽略没有共同评分的数据。
- 协同过滤之Slope One算法
- 协同过滤推荐之slope one算法
- Slope One 协同过滤算法
- 协同过滤算法-slope one
- 推荐算法之协同过滤算法之Slope one
- 协同过滤推荐算法之Slope One的介绍
- Collaborative filtering 协同过滤算法 Slope One
- Slope One 协同过滤 推荐算法
- Slope one简单的协同过滤算法
- 基于在线评分的协同过滤算法---Slope One算法
- Slope One :简单高效的协同过滤算法(Collaborative Filtering)
- Slope One简单高效的协同过滤算法
- 协同推荐Slope One算法
- 协同推荐算法实践之Slope One的介绍
- Slope One协同推荐算法php代码
- Slope one—个性化推荐中最简洁的协同过滤算法
- 推荐算法之 slope one 算法
- 推荐算法之 slope one 算法
- Linux下重置密码(忘记密码)的方法
- iphone图片等比缩放
- http://acm.nyist.net/JudgeOnline/problem.php?pid=409&&中缀转化为前缀和后缀并求值
- javascript逐渐变大的跳转窗口
- JavaScript父、子页面间互传值
- 协同过滤之Slope One算法
- FTP的传输的两种方式和工作方式比较,二进制数据传输和ASCII传输区别
- window.open打开的窗体和父窗体之间互传参数
- 对新类的(>>)(<<)即输入和提取方法进行的重载
- MyEclipse/Eclipse 常用快捷键
- ffmpeg开发指南
- SQL Server 2008中的hierarchyid
- lzo的安装及在hadoop中的配置 .
- VAX.Visual.Assist.X.V10.6.1862.0 破解补丁


