随机图 & 如何处理Power-law(幂律)分布的数据
来源:互联网 发布:数据魔方下线了吗 编辑:程序博客网 时间:2024/05/22 03:18
在研究复杂网络中,研究者使用的主要工具就是随机图理论。该理论创始于上个世纪40年代。由Erdos等人创立。最早提出的经典随机图模型就是ER模型。在随机图中,边的出现成为概率事件。随机图和经典图之间最大的区别在于引入了随机的方法,使得图的空间变得更大,其数学性质也发生了巨大的变化,在随机图的经典数学模型中,随机图上的结点度数分布服从泊松分布。经过长达60多年的研究,最近由圣塔非的M.E.J Newman等人将随机图中的度数分布扩展到任意度数分布,我们称之为"广义随机图",这使得对复杂网络的研究有了进一步的深入。虽然我觉得广义随机图理论在解决power-law问题上仍然存在这一定的缺陷。但是至少它在仿真上已经被证实了。
在数学中,随机图是指由随机过程产生的图[1]。随机图的理论处于图论和概率论的交叉地带,主要研究各种经典随机图的性质。第一批关于随机图的结果是保罗·埃尔德什和阿尔弗雷德·雷尼在1959年至1966年的一系列论文中提出的[2].
目录
[隐藏]- 1 定义与模型
- 2 性质
- 3 随机树
- 4 参见
- 5 参考来源
[编辑]定义与模型
随机图的“随机”二字体现在边的分布上。一个随机图实际上是将给定的顶点之间随机地连上边。假设将一些纽扣散落在地上,并且不断随机地将两个纽扣之间系上一条线,这样就得到一个随机图的例子[3]。边的产生可以依赖于不同的随机方式,这样就产生了不同的随机图模型。一个典型的模型是埃尔德什和雷尼共同研究的ER模型。ER模型是指在给定 n 个顶点后,规定每两个顶点之间都有 p 的概率连起来(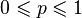 ),而且这些判定之间两两无关。这样得到的随机图一般记作
),而且这些判定之间两两无关。这样得到的随机图一般记作  或 ERn(p)[4]。
或 ERn(p)[4]。
另一种随机图模型叫做内积模型。内积模型的机制是对每一个顶点指定一个实系数的向量,而两个顶点之间是否连接的概率则是它们的向量的内积的函数。
一般来说,可以定义任意两个顶点之间相连的概率,这个概率也被称为边概率。定义更广泛的随即图模型的方法是定义所谓的网络概率矩阵。这个矩阵的系数就是边概率,因此详细刻画了随机图的模型。
随机规则图是随机图中特殊的一类,它的性质可能会与一般的随机图不同。
[编辑]性质
随着边概率的不同,随机图可能会呈现不同的属性。对于最典型的ER模型,埃尔德什与雷尼研究了当顶点数目 n 趋向于正无穷大时,ER随机图的性质与概率 p 之间的关系。他们发现,当 p 的值越过某些门槛时,ER随机图的性质会发生突然的改变[3]。ER随机图的许多性质都是突然涌现的,比如说,当 p 的值小于某个特殊值之前,随机图具有某个性质的可能性等于0,但当 p 的值大于这个特殊值以后,随机图具有这个性质的可能性会突然变成1。
举例来说,当概率 p 大于某个临界值 pc(n) 后,生成的随机图几乎必然是连通的(概率等于1)。也就是说,对于散落在地上的 n 个纽扣,如果你以这样的概率 p 将两个纽扣之间系上线,那么你拿起一颗纽扣时就几乎能带起所有的纽扣了[3]。
[编辑]随机树
随机树是随机图的一类。如同随机图一样,随机树是一个经由随机过程建立的树。随机树的一种生成方法是利用随机置换。首先生成一个  阶随机置换函数,将 个可能连起来的边标上 1 至 的序号。然后按照从小到大的序号排列为原本没有边的图一一添加边。添加第
阶随机置换函数,将 个可能连起来的边标上 1 至 的序号。然后按照从小到大的序号排列为原本没有边的图一一添加边。添加第  条边时,如果发现添加后会导致图中出现一个圈,那么就放弃添加这条边,而开始添加第
条边时,如果发现添加后会导致图中出现一个圈,那么就放弃添加这条边,而开始添加第 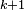 条边。最后得到的就是一个随机树[5]。
条边。最后得到的就是一个随机树[5]。
[编辑]参见
- 玻色-爱因斯坦凝聚
- 腔体法
- 复杂网络
- 小世界网络
- 无尺度网络
[编辑]参考来源
- ^ Béla Bollobás, Random Graphs, 2nd Edition, 2001, Cambridge University Press
- ^ 第一篇论文发表于1959年,标题为“On Random Graphs I”(《论随机图 I》),Publ. Math. Debrecen 6, p290.
- ^ 3.0 3.1 3.2 汪小帆,李翔,陈关荣. 《复杂网络理论及其应用》. 清华大学出版社. 2006. ISBN 9787302125051 (中文).
- ^ Romeo Van Der Hofstad. Random Graphs and Complex Networks. Eindhoven University of Technology. 2011年2月25日 (英文).
- ^ Alexandr Kazda. The Random Tree Process. Center for Discrete Mathematics and Theoretical Computer Science [2011-04-24].
如何处理Power-law(幂律)分布的数据?
[大] [中] [小]

- 随机图 & 如何处理Power-law(幂律)分布的数据
- 图的幂律度分布 power-law degree distributios
- 图的幂律度分布 power-law degree distributios
- 幂律分布现象-power-law
- 幂律power-law
- power law
- 如何平均得到圆内点的随机分布
- 如何平均得到圆内点的随机分布
- 淺談網路世界的Power Law現象
- 浅谈网络世界中的Power Law现象(一) 什么是Power Law
- 幂定律power-law
- Power law distribution
- power law幂次法则
- 幂次法则power law
- [python数据分析] 简述幂率定律及绘制Power-law函数
- 如何高效的提取随机数据
- mysql如何随机获取数据的方法
- R语言 生成符合特定分布的随机数据并写入文件
- ROOT android 原理。 基于(zergRush)
- Qt for Embedded Linux Environment Variables
- android 状态栏实例
- CentOS在Shell中修改IP地址
- java.lang.OutOfMemoryError: PermGen space
- 随机图 & 如何处理Power-law(幂律)分布的数据
- Android多媒体学习一:Android中Image的简单实例。
- Qt for Embedded Linux Display Management
- meanShift算法介绍
- sh: ./hello: not executable: magic 7F45
- GXT(Ext-Gwt)例子的创建、配置、部署心得
- java.ByteArrayInputStream-ByteArrayOutputStream
- NOIP2004 合唱队形
- Linux解压命令


