Linux开发心得总结15 - Learning about Linux Processes
来源:互联网 发布:人类与人工智能 编辑:程序博客网 时间:2024/05/08 14:10
So, What Is A Process?
Quoting from Robert Love's book Linux Kernel Development, "The Process is one of the fundamental abstractions in Unix Operating Systems, the other fundamental abstraction being files." Aprocess is a program in execution. It consists of the executing program code, a set of resources such as open files, internal kernel data, an address space, one or more threads of execution and a data section containing global variables.
Process Descriptors
Each process has process descriptors associated with it. These hold the information used to keep track of a process in memory. Among the various pieces of information stored about a process are its PID, state, parent process, children, siblings, processor registers, list of open files and address space information.
The Linux kernel uses a circular doubly-linked list of struct task_structs to store these process descriptors. This structure is declared inlinux/sched.h. Here are a few fields from kernel 2.6.15-1.2054_FC5, starting at line 701:
701 struct task_struct { 702 volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ 703 struct thread_info *thread_info; . . 767 /* PID/PID hash table linkage. */ 768 struct pid pids[PIDTYPE_MAX]; . . 798 char comm[TASK_COMM_LEN]; /* executable name excluding pathThe first line of the structure defines the field state as volatile long. This variable is used to keep track of the execution state of the process, defined by the following macros:
#define TASK_RUNNING 0#define TASK_INTERRUPTIBLE 1#define TASK_UNINTERRUPTIBLE 2#define TASK_STOPPED 4#define TASK_TRACED 8/* in tsk->exit_state */#define EXIT_ZOMBIE 16#define EXIT_DEAD 32/* in tsk->state again */#define TASK_NONINTERACTIVE 64
The volatile keyword is worth noting - see http://www.kcomputing.com/volatile.html for more information.
Linked Lists
Before we look at how tasks/processes (we will use the two words as synonyms) are stored by the kernel, we need to understand how the kernel implements circular linked lists. The implementation that follows is a standard that is used across all the kernel sources. The linked list is declared in linux/list.h and the data structure is simple:
struct list_head { struct list_head *next, *prev; };This file also defines several ready-made macros and functions which you can use to manipulate linked lists. This standardizes the linked list implementation to prevent people "reinventing the wheel" and introducing new bugs.
Here are some kernel linked list references:
- Suman Adak has an excellent entry in his blog at this link
- Linux kernel source: <include/linux/list.h>, <include/linux/sched.h>
- "Linux Kernel Development", by Robert Love (Appendix A)
- http://www.win.tue.nl/~aeb/linux/lk/lk-2.html
The Kernel Task List
Let us now see how the linux kernel uses circular doubly-linked lists to store the records of processes. Searching forstruct list_head inside the definition of struct task_struct gives us:
struct list_head tasks;
This line shows us that the kernel is using a circular linked list to store the tasks. Thsi means we can use the standard kernel linked list macros and functions to traverse through the complete task list.
init is the "mother of all processes" on a Linux system. Thus it is represented at the beginning of the list, although strictly speaking there is no head since this is acircular list. The init task's process descriptor is statically allocated:
extern struct task_struct init_task;
The following shows the linked list representation of processes in memory:
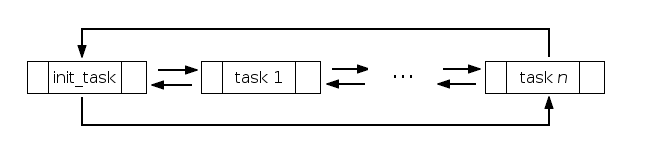
Several other macros and functions are available to help us traverse this list:
for_each_process() is a macro which iterates over the entire task list. It is defined as follows in linux/sched.h:
#define for_each_process(p) \ for (p = &init_task ; (p = next_task(p)) != &init_task ; )
next_task() is a macro defined in linux/sched.h which returns the next task in the list:
#define next_task(p) list_entry((p)->tasks.next, struct task_struct, tasks)
list_entry() is a macro defined in linux/list.h:
/* * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_struct within the struct. */#define list_entry(ptr, type, member) \ container_of(ptr, type, member)
The macro container_of() is defined as follows:
#define container_of(ptr, type, member) ({ \ const typeof( ((type *)0)->member ) *__mptr = (ptr); \ (type *)( (char *)__mptr - offsetof(type,member) );})<!--
The purpose of this macro is that it returns the inode number ofthe node.
-->
Thus if we can traverse through the entire task list we can have all the processes running on the system. This can be done with the macro for_each_process(task) , where task is a pointer of struct task_struct type. Here is an example kernel module, fromLinux Kernel Development:
/* ProcessList.c Robert Love Chapter 3 */ #include < linux/kernel.h > #include < linux/sched.h > #include < linux/module.h > int init_module(void) { struct task_struct *task; for_each_process(task) { printk("%s [%d]\n",task->comm , task->pid); } return 0; } void cleanup_module(void) { printk(KERN_INFO "Cleaning Up.\n"); }The current macro is a link to the process descriptor (a pointer to atask_struct)of the currently executing process. How current achieves its task is architecture dependent. On an x86 this is done by the functioncurrent_thread_info() in asm/thread_info.h
/* how to get the thread information struct from C */ static inline struct thread_info *current_thread_info(void) { struct thread_info *ti; __asm__("andl %%esp,%0; ":"=r" (ti) : "0" (~(THREAD_SIZE - 1))); return ti; }Finally current dereferences the task member of the thread_info structure which is reproduced below fromasm/thread_info.h by current_thread_info()->task;
struct thread_info { struct task_struct *task; /* main task structure */ struct exec_domain *exec_domain; /* execution domain */ unsigned long flags; /* low level flags */ unsigned long status; /* thread-synchronous flags */ __u32 cpu; /* current CPU */ int preempt_count; /* 0 => preemptable, <0 => BUG */ mm_segment_t addr_limit; /* thread address space: 0-0xBFFFFFFF for user-thread 0-0xFFFFFFFF for kernel-thread */ void *sysenter_return; struct restart_block restart_block; unsigned long previous_esp; /* ESP of the previous stack in case of nested (IRQ) stacks */ __u8 supervisor_stack[0]; };<!--
I did wonder a bit about why the current processdescriptor is obtained from thethread_info structure and Ireasoned to myself that since a thread is a unit of dispatch so thecurrent process information is obviously going to be obtained fromthe currently executing thread.
-->
Using the current macro and init_task we can write a kernel module to trace from the current process back toinit.
/*Traceroute to init traceinit.cRobert Love Chapter 3*/ #include < linux/kernel.h > #include < linux/sched.h > #include < linux/module.h > int init_module(void) { struct task_struct *task; for(task=current;task!=&init_task;task=task->parent) //current is a macro which points to the current task / process { printk("%s [%d]\n",task->comm , task->pid); } return 0; } void cleanup_module(void) { printk(KERN_INFO "Cleaning up 1.\n"); }Well, we have just started in our quest to learn about one of the fundamental abstractions of a linux system — the process. In (possible) future extensions of this, we shall take a look at several others.
'Till then, Happy hacking!
Other Resources:
- The Linux Kernel Module Programming Guide for 2.6.x kernels
- Makefile used to compile the kernel modules:
obj-m +=ProcessList.o obj-m +=traceinit.o all: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
- Linux开发心得总结15 - Learning about Linux Processes
- Linux开发心得总结11 - Page table
- Linux开发心得总结14 - linux情景分析--存储管理
- Linux开发心得总结14 - Red Hat Linux Deployment Guide
- Linux开发心得总结16 - linux 程序加载过程
- Linux开发心得总结18 - Linux内存管理
- 【Linux】Linux Kernel-Processes(一)
- Linux开发心得总结8 - 虚地址转换为物理地址
- Linux开发心得总结10 - MIPS TLB 的结构(translated)
- Linux开发心得总结19 - 进程的虚拟空间
- About Linux
- About Linux
- An overview of Linux processes
- linux分布式系统开发心得
- Linux开发心得总结1 - Linux内核分析之缺页中断
- Linux开发心得总结5 - Linux下OOM Killer机制详解
- Linux开发心得总结6 - When Linux Runs Out of Memory
- Linux开发心得总结7 - linux内核空间与用户空间信息交互方法
- 新的生活却没有新的觉悟
- 企业级服务器设计与实现经验之开篇
- 来美35天
- 企业级服务器设计与实现经验之系统框架(一)
- poj 2893 hdu 3600 M*N数码问题
- Linux开发心得总结15 - Learning about Linux Processes
- 企业级服务器设计与实现经验之系统框架(二)
- JavaBean 的事件
- 贫血模型与充血模型
- 你不适合创业
- vmware 问题集集
- vmware esxi 5.0更新说明
- 事件驱动的单线程模型 VS 多线程模型
- What is Port-Forwarding ?


