zero copy architecture of my video process application on TI 8168 using C6runLib
来源:互联网 发布:对徐贲的评价知乎 编辑:程序博客网 时间:2024/04/27 23:05
1 my design using c6runlib
Following is my design based on TI c6runlib compiler. Core structure is a "working item line", which contains a queue made of pointers pointing to buffers allocated from heap, and a lock used whenever the queue need to be modified. All accessing to the queue would be limited to functions where locking, dequeueing are implemented. What the design want is, locking the queue instead of locking the buffers, so a buffer need to be processed, lock the structure, dequeue the buffer and then unlock the structure, so this would reduce conflict chances between threads.
There are 3 threads running: thread Capture running on ARM with "working item line" resCap, thread VideoProcess running on ARM and DSP, thread PostProcess running on ARM with resPost.
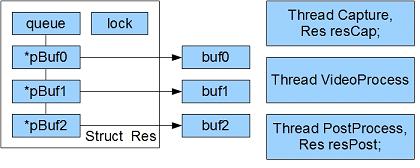
graph 1: static model
At runtime, the queue in resCap running as a ring buffer, the Capture thread would using the oldest buffer to do video capture, and then put it to the head of the list, so the head is always the latest frame. The VideoProcess thread would dequeue the latest frame from resCap, and then look at the time stamp on it to see if it need to be processed. If it is, process it, and then put it to queue resPost. The PostProcess thread do further works such as saving, sending, and it pulls working item on queue resPost. When work is done it will put the buffer back to resCap, which belongs to thread Capture.
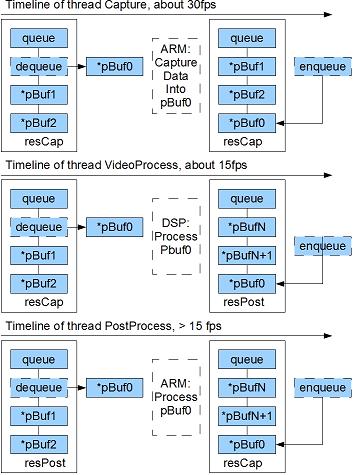
graph 2, runtime model
The design is based on following conditions: thread VideoProcess is much slower than other threads, so the input and output queue of VideoProcess are saved. The total speed depends on the slowest one thread: VideoProcess, but this design have saved frame copy and some queue accessing with locking.
- zero copy architecture of my video process application on TI 8168 using C6runLib
- zero copy architecture in RDK of TI 8168 EVM
- Boot Process of C Program on TI C55x DSP
- The Creation of Process 0 & 1 on ARM Architecture
- General overview of architecture of TI's Davinci 8168 SoC
- Why my application crashes on process termination when file sinks are used?
- Patterns Of Enterprise Application Architecture
- Patterns of enterprise application architecture
- Video Transmit on Linux Using JMF
- Get Process list & info & copy process memory on macosx
- Zero Copy
- zero copy
- zero copy
- zero-copy
- Zero Copy
- zero copy
- Zero-Copy
- 读 Patterns of Enterprise Application Architecture 1
- Greensock平台
- 非官网下载的android 源码编译问题 及解决方法
- 电脑连接PPC软件..PocketController-v6.01注册码
- Ubuntu 安装漂亮的 Screenlets 小工具
- 使用POI生成Excel文件,可以自动调整excel列宽 .
- zero copy architecture of my video process application on TI 8168 using C6runLib
- MES入门.预备知识.设备维护
- 第四周任务三选作
- LINUX下SVN命令大全
- 第四周任务二(多文件组织项目)
- ubuntu 相关配置
- linux grep命令参数及 用法详解---linux管道命令grep
- 浅析起始来源数据
- 身份证验证JS代码(可用于游戏防沉迷)!


