小玩具——单词词频统计
来源:互联网 发布:苹果电脑安装办公软件 编辑:程序博客网 时间:2024/04/29 10:29
该程序是在我学习JAVA过程中的一个偶然想法,距离现在很久了,现在回顾一下这个程序的编写过程,有一天我正在背CET-4单词,实在是很煎熬啊,看着好厚一本俞敏洪的CET-4,我实在是感到很不开心,背着背着,我在想如果能够找出所有从2000年到本年的卷子中的单词频率,是否会使背单词容易些?我简单在大脑中“验证”了一下设计方法,验证通过,也许是不想背单词,我立刻被这个很好的不背单词“借口”所打动,立刻奔向实验室,开始编码。
最终的编码结果:

处理的源文件截图:
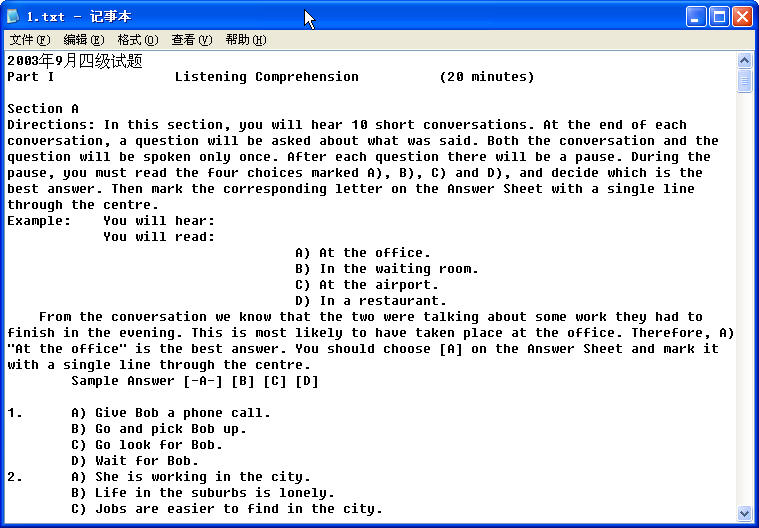
最终的处理结果(2003年9月四级试题):
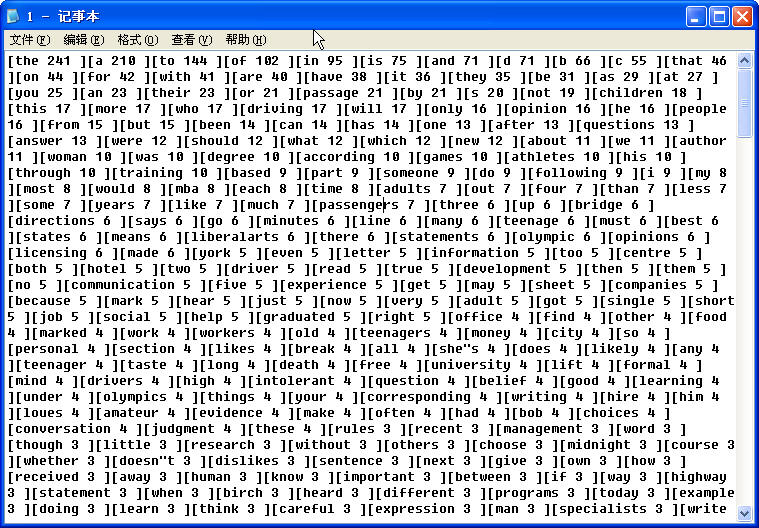
正如大家所看到,输入文件为:从网上下载的不加修改的试题,输出为处理好的,对于每一种出现的英文单词的词频,[单词 该单词词频]
现在我们来回顾一下制作过程,我也是时隔很久之后来回忆,尽力全面,也对该程序做一个反思:
最初的设计,是使用数据库来存储词频的,为什么用数据库呢,因为当时正在学习数据库,我就现学现用,因此我使用了MYSQL数据库来存储每一个单词的词频变化,最终寄希望于在数据库中生成一个每个单词的词频统计数据。
当时我建立了一个表,该表极为简单,只有两列:单词,词频。这样做显然也是很简单的,我只需要做 查找、修改和更新的操作。而大部分的程序就不需要我自己写了,好懒啊~!
首先,我来呈现一下当时的想法:
1、对文本中非英语的一切字符进行过滤,只留下英语和必要的空格(标点符号换成空格,空格能够区分不同单词,同时对于英语中特别的字符要加以处理)
2、过滤出单词
3、对单词首先在数据表中“查找”操作,如果存在,则更新值,如果不存在,则插入值。
4、寻找合适的呈现方法,将最终的数据呈现出来,表格、文件等
此想法是非常不错的,但是在实施过程中,遇到了一个棘手的问题,在对单个年份的文档进行处理的时候是可以的,但是对于数十年的文档处理时候,会报一个数据库连接池到达最大连接数的错误。
在该错误出现后,对该错误进行反复测试,发现为可重现错误,首先对自己的程序进行检查,尽量再次优化减少存储数据库的次数(当然想到了再次建立内存中的检索模型,但是一旦这样做,我可不能偷懒了,这又不是商业项目,我只是想要结果而已),我修改了数据库连接池的参数,仍然出现问题,而且出现问题的连接次数我做过统计,似乎浮动于某个固定值(此值目前已忘记),因此可以认为是一个固定限制,而且影响该次数的应该不止有我的程序,否则不会出现浮动的现象。
考虑到win系统看待连接数据库的方式,我认为应该与系统有关,因此查阅网络上有关连接数据库的相关资料,特别是系统方面的相关资料,发现是winxp系统对于连接数据库有上限的,根据我所使用的XP系统的版本,我按照微软官方的方法进行调整,但是调整后没有效果,调整后重新启动,仍然没有效果……,查看网络上有些人遇到了跟我一样的问题,调整后仍然无法解决,所以看来这个懒是没法偷了。
考虑更改软件的设计,不采用数据库来存储了,经历这个事件,对数据库的练习还是实现了其价值的,现在就关心怎么出结果。
不使用数据库,首先我想到了构建一组内存结构,其实也很简单,主要构造一个类,用来存储word和词频,只需要两个变量,由于我只是用于一次,可以不考虑数据封装,只是用public来限制变量,但是我想,更好的方法是不建立类,直接使用Map,在JAVA中这些容器非常好用,而且速度也非常快,我选择HashMap。MAP本身就是“键-值”类型,键用来存储word,值用来存储词频,哈哈偷懒成功。
所以后来程序的设计为:
1、对文本中非英语的一切字符进行过滤,只留下英语和必要的空格(标点符号换成空格,空格能够区分不同单词,同时对于英语中特别的字符要加以处理)
2、过滤出单词
3、对单词首先在MAP中“查找”操作,如果存在,则更新值,如果不存在,则插入值。
4、寻找合适的呈现方法,将最终的数据呈现出来,表格、文件等
其实就是一个小玩具而已,现在给出核心代码(很早前写的代码,不足之处请包涵):
变量设定:
Map map=new HashMap(); File inputStr=new File(from); //打开输入文件 File outputStr=new File(dest); //建立输出文件FileInputStream fi=new FileInputStream(inputStr); //输入流FileWriter fwout=new FileWriter(outputStr); //输出流我很偷懒的占用内存来作恶了,哈哈。现在来看这里不能这样做,我们可以读入一段处理一段,建立两个对称大小的缓冲区,灵活使用,防止由于缓冲区大小不够造成单词被截断的情况发生: byte[] c=new byte[5500000]; //字符集合过滤出单词:for(int i=0;i<c.length;i++){if((65<=c[i]&&c[i]<=90)||(97<=c[i]&&c[i]<=122)||c[i]==32||c[i]==39||c[i]==46||c[i]==44)if(c[i]==32) {String tmp=str.substring(p, i);String retmp=tmp.trim();if(!retmp.equals("")){ frontstr+=retmp;if (map.get(retmp)==null){ map.put(retmp, 1);}else{int old=Integer.parseInt(map.get(retmp).toString());map.put(retmp, old+1);}p=i;}}}输出(包含排序,词频最大在前):Set set=map.keySet();while(!map.isEmpty()){int max=0,point=0;Object[] keySet=set.toArray();for(int i=0;i<keySet.length;i++){if (Integer.parseInt(map.get(keySet[i]).toString())>=max) {max=Integer.parseInt(map.get(keySet[i]).toString());point=i;} }- 小玩具——单词词频统计
- 金典——词频统计
- 使用单词树进行词频统计算法
- 统计大数据中的单词词频
- python 文本单词提取和词频统计
- java进行文本单词的词频统计
- 统计一个英文文本的单词词频
- Java词频统计算法(使用单词树)
- 用Trie树实现词频统计和单词查询
- Java词频统计算法(使用单词树)
- 编程统计一个英文文本文件中单词词频
- Java词频统计算法(使用单词树)
- Java词频统计算法(使用单词树)
- Trie树统计词频和指定前缀的单词个数
- Java词频统计算法(使用单词树)
- 【spark 词频统计】spark单词进行计数升级版
- 单词词频统计程序(map set 应用)
- 单词词频统计降序排序(代码贴)
- Android Permission 中英对照
- 更改centos yum 成中国镜像加快yum速度
- CentOS 5.X 安装 GForge ,安装 postgresql
- soa技术,webservice,soap
- Service组件 startService() bindService()
- 小玩具——单词词频统计
- Android学习第16课—SQLite的简单使用
- Struts2简介
- Hibernate一对一 主键关联映射(one-to-one)
- difference with Macro and Template
- 既有鱼肉又有熊掌——浅尝ListOrderedMap
- rpm安装和卸载
- 动态的启动系统服务
- 搜狗2012校园招聘自测题


