算法系列之六:快速排序
来源:互联网 发布:淘宝导航条代码生成器 编辑:程序博客网 时间:2024/04/30 05:12
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,再加上快速排序思想----分治法也确实实用,因此很多软件公司的笔试面试,包括像腾讯,微软等知名IT公司都喜欢考这个,还有大大小的程序方面的考试如软考,考研中也常常出现快速排序的身影。
总的说来,要直接默写出快速排序还是有一定难度的,因为本人就自己的理解对快速排序作了下白话解释,希望对大家理解有帮助,达到快速排序,快速搞定。
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数。
0
1
2
3
4
5
6
7
8
9
72
6
57
88
60
42
83
73
48
85
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j--;
数组变为:
0
1
2
3
4
5
6
7
8
9
48
6
57
88
60
42
83
73
88
85
i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
0
1
2
3
4
5
6
7
8
9
48
6
57
42
60
72
83
73
88
85
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结
1.i =L; j = R; 将基准数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
照着这个总结很容易实现挖坑填数的代码:
int AdjustArray(ints[], intl, int r) //返回调整后基准数的位置
{
int i = l,j =r;
int x = s[l];//s[l]即s[i]就是第一个坑
while (i < j)
{
//从右向左找小于x的数来填s[i]
while(i <j &&s[j] >=x)
j--;
if(i <j)
{
s[i] =s[j];//将s[j]填到s[i]中,s[j]就形成了一个新的坑
i++;
}
//从左向右找大于或等于x的数来填s[j]
while(i <j &&s[i] <x)
i++;
if(i <j)
{
s[j] =s[i];//将s[i]填到s[j]中,s[i]就形成了一个新的坑
j--;
}
}
//退出时,i等于j。将x填到这个坑中。
s[i] =x;
return i;
}
再写分治法的代码:
void quick_sort1(ints[], intl, int r)
{
if (l < r)
{
inti = AdjustArray(s,l,r);//先成挖坑填数法调整s[]
quick_sort1(s,l,i - 1);//递归调用
quick_sort1(s,i + 1,r);
}
}
这样的代码显然不够简洁,对其组合整理下:
//快速排序
void quick_sort(ints[], intl, int r)
{
if (l < r)
{
//Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换参见注1
int i = l,j =r,x =s[l];
while (i < j)
{
while(i <j &&s[j] >=x)//从右向左找第一个小于x的数
j--;
if(i <j)
s[i++] =s[j];
while(i <j &&s[i] <x)//从左向右找第一个大于等于x的数
i++;
if(i <j)
s[j--] =s[i];
}
s[i] =x;
quick_sort(s, l, i - 1);//递归调用
quick_sort(s, i + 1, r);
}
}
快速排序还有很多改进版本,如随机选择基准数,区间内数据较少时直接用另的方法排序以减小递归深度。有兴趣的筒子可以再深入的研究下。
注1,有的书上是以中间的数作为基准数的,要实现这个方便非常方便,直接将中间的数和第一个数进行交换就可以了。
转载请标明出处,原文地址:http://www.cnblogs.com/morewindows/archive/2011/08/13/2137415.html
最长公共子序列(LCS)问题有两种方式定义子序列,一种是子序列不要求不连续,一种是子序列必须连续。上一章介绍了用两种算法解决子序列不要求连续的最终公共子序列问题,本章将介绍要求子序列必须是连续的情况下如何用算法解决最长公共子序列问题。
仍以上一章的两个字符串 “abcdea”和“aebcda”为例,如果子序列不要求连续,其最长公共子序列为“abcda”,如果子序列要求是连续,则其最长公共子序列应为“bcd”。在这种情况下,有可能两个字符串出现多个长度相同的公共子串,比如“askdfiryetd”和“trkdffirey”两个字符串就存在两个长度为3的公共子串,分别是“kdf”和“fir”,因此问题的性质发生了变化,需要找出两个字符串所有可能存在公共子串的情况,然后取最长的一个,如果有多个最长的公共子串,只取其中一个即可。
字符串 “abcdea”和“aebcda”如果都以最左端的a字符对齐,则能够匹配的最长公共子串就是“a”。但是如果用第二个字符串的e字符对齐第一个字符串的a字符,则能够匹配的最长公共子串就是“bcd”。可见,从两个字符串的不同位置开始对齐匹配,可以得到不同的结果,因此,本文采用的算法就是穷举两个字符串所有可能的对齐方式,对每种对齐方式进行字符的逐个匹配,找出最长的匹配子串。
一、 递归方法
首先看看递归方法。递归的方法比较简单,就是比较两个字符串的首字符是否相等,如果相等则将其添加到已知的公共子串结尾,然后对两个字符串去掉首字符后剩下的子串继续递归匹配。如果两个字符串的首字符不相等,则用三种对齐策略分别计算可能的最长公共子串,然后取最长的一个与当前已知的最长公共子串比较,如果比当前已知的最长公共子串长就用计算出的最长公共子串代替当前已知的最长公共子串。第一种策略是将第一个字符串的首字符删除,将剩下的子串与第二个字符串继续匹配;第二种策略是将第二个字符串的首字符删除,将剩下的子串与第一个字符串继续匹配;第三种策略是将两个字符串的首字符都删除,然后继续匹配两个字符串剩下的子串。删除首字符相当于字符对齐移位,整个算法实现如下:
180 void RecursionLCS(const std::string& str1,const std::string& str2, std::string& lcs)
181 {
182 if(str1.length()==0 || str2.length()==0)
183 return;
184
185 if(str1[0]== str2[0])
186 {
187 lcs += str1[0];
188 RecursionLCS(str1.substr(1), str2.substr(1), lcs);
189 }
190 else
191 {
192 std::string strTmp1,strTmp2,strTmp3;
193
194 RecursionLCS(str1.substr(1), str2, strTmp1);
195 RecursionLCS(str1, str2.substr(1), strTmp2);
196 RecursionLCS(str1.substr(1), str2.substr(1), strTmp3);
197 std::string strLongest= GetLongestString(strTmp1, strTmp2, strTmp3);
198 if(lcs.length()< strLongest.length())
199 lcs = strLongest;
200 }
201 }
二、 两重循环方法
使用两重循环进行字符串的对齐匹配过程如下图所示:
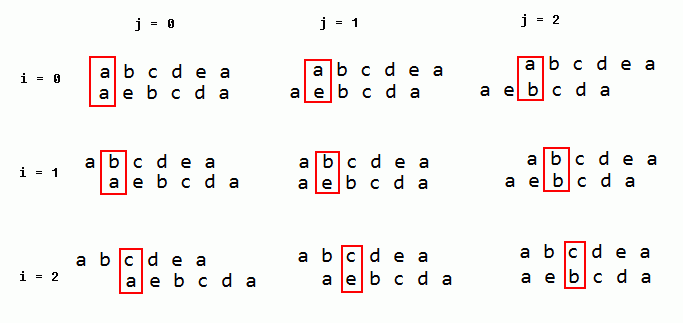
图(1)两重循环字符串对齐匹配示意图
第一重循环确定第一个字符串的对齐位置,第二重循环确定第二个字符串的对齐位置,每次循环确定一组两个字符串的对齐位置,并从此对齐位置开始匹配两个字符串的最长子串,如果匹配到的最长子串比已知的(由前面的匹配过程找到的)最长子串长,则更新已知最长子串的内容。两重循环的实现算法如下:
153 void LoopLCS(const std::string& str1,const std::string& str2, std::string& lcs)
154 {
155 std::string::size_type i,j;
156
157 for(i = 0; i < str1.length(); i++)
158 {
159 for(j = 0; j < str2.length(); j++)
160 {
161 std::string lstr= LeftAllignLongestSubString(str1.substr(i), str2.substr(j));
162 if(lstr.length()> lcs.length())
163 lcs = lstr;
164 }
165 }
166 }
其中LeftAllignLongestSubString()函数的作用就是从某个对齐位置开始匹配最长公共子串,其实现过程就是逐个比较字符,并记录最长子串的位置信息。
三、 改进后的算法
使用两重循环的算法原理简单,LoopLCS()函数的实现也简单,时间复杂度为O(n2)(或O(mn)),比前一个递归算法的时间复杂度O(3n)要好很多。但是如果仔细观察图(1)所示的匹配示意图,就会发现这个算法在m x n次循环的过程中对同一位置的字符进行多次重复的比较。比如i=1,j=0的时候,从对齐位置开始第二次比较会比较第一个字符串的第三个字符“c”与第二个字符串的第二个字符“e”,而在i=1,j=0的时候,这个比较又进行了一次。全部比较的次数可以近似计算为mn(n-1)/2(其中m和n分别为两个字符串的长度),也就是说比较次数是O(n3)数量级的。而理论上两个字符串的不同位置都进行一次比较只需要mn次比较即可,也就是说比较次数的理论值应该是O(n2)数量级。
考虑对上述算法优化,可以将两个字符串每个位置上的字符的比较结果保存到一张二维表中,这张表中的[i,j]位置就表示第一个字符串的第i个字符与第二个字符串的第j个字符的比较结果,1表示字符相同,0表示字符不相同。在匹配最长子串的过程中,不必多次重复判断两个字符是否相等,只需从表中的[i,j]位置直接得到结果即可。
改进后的算法分成两个步骤:首先逐个比较两个字符串,建立关系二维表,然后用适当的方法搜索关系二维表,得到最长公共子串。第一个步骤比较简单,算法的改进主要集中在从关系二维表中得到最长公共子串的方法上。根据比较的原则,公共子串都是沿着二维表对角线方向出现的,对角线上连续出现1就表示这个位置是某次比较的公共子串。有上面的分析可知,只需要查找关系二维表中对角线上连续出现的1的个数,找出最长的一串1出现的位置,就可以得到两个字符串的最长公共子串。改进后的算法实现如下:
105 void RelationLCS(const std::string& str1,const std::string& str2, std::string& lcs)
106 {
107 int d[MAX_STRING_LEN][MAX_STRING_LEN]={ 0 };
108 int length = 0;
109
110 InitializeRelation(str1, str2, d);
111 int pos = GetLongestSubStringPosition(d, str1.length(), str2.length(),&length);
112 lcs = str1.substr(pos, length);
113 }
InitializeRelation()函数就是初始化二维关系表,根据字符比较的结果将d[i,j]相应的位置置0或1,本文不再列出。算法改进的关键在GetLongestSubStringPosition()函数中,这个函数负责沿对角线搜索最长公共子串,并返回位置和长度信息。仍然以字符串 “abcdea”和“aebcda”为例,InitializeRelation()函数计算得到的关系表如图(2)所示:

图(2)示例字符串的位置关系示意图
从图(2)中可以看到,最长子串出现在红线标注的对角线上,起始位置在第一个字符串(纵向)中的位置是2,在第二个字符串(横向)中的位置是3,长度是3。搜索对角线从两个方向开始,一个是沿着纵向搜索左下角方向上的半个关系矩阵,另一个是沿着横向搜索右上角方向上的半个关系矩阵。对每个对角线分别查找连续的1出现的次数和位置,并比较得到连续1最多的位置。GetLongestSubStringPosition()函数的代码如下:
63 int GetLongestSubStringPosition(int d[MAX_STRING_LEN][MAX_STRING_LEN],int m, int n,int *length)
64 {
65 int k,longestStart,longs;
66 int longestI = 0;
67 int longi = 0;
68
69 for(k = 0; k < n; k++)
70 {
71 longi = GetLongestPosition(d, m, n,0, k,&longs);
72 if(longi > longestI)
73 {
74 longestI = longi;
75 longestStart= longs;
76 }
77 }
78 for(k = 1; k < m; k++)
79 {
80 longi = GetLongestPosition(d, m, n, k,0,&longs);
81 if(longi > longestI)
82 {
83 longestI = longi;
84 longestStart= longs;
85 }
86 }
87
88 *length = longestI;
89 return longestStart;
90 }
GetLongestPosition()函数就是沿着对角线方向搜索1出现的位置和连续长度,算法简单,本文不再列出。
至此,本文介绍了三种要求子串连续的情况下的求解最长公共子串的方法,都是简单易懂的方法,没有使用复杂的数学原理。第一种递归方法的时间复杂度是O(3n),这个时间复杂度的算法在问题规模比较大的情况下基本不具备可用性, 第三种方法是相对最好的方法,但是仍有改进的余地,比如使用位域数组,可以减少存储空间的使用,同时结合巧妙的位运算技巧,可以极大地提高GetLongestPosition()函数的效率。
- 算法系列之六:快速排序
- 经典算法系列之六 快速排序 快速排序
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 白话经典算法系列之六 快速排序 快速搞定
- 也谈去雾
- 开发人员应具有的产品意识(五) 连载
- js脚本调试方法
- pack函数的作用
- 开发人员应具有的产品意识(六) 连载
- 算法系列之六:快速排序
- secondary sort
- #pragma pack 用法详解
- 负数的二进制表示方法
- 本地yum配置,centos和redhat
- andriod Canvas 和 Paint方法的解释
- eclipse中图标的含义
- 设计模式 一 抽象工厂Abstract Factory(工厂模式)
- FlexiGrid的使用


