java集合类总结
来源:互联网 发布:哈雷尔体测数据 编辑:程序博客网 时间:2024/05/22 02:31
集合框架中的接口
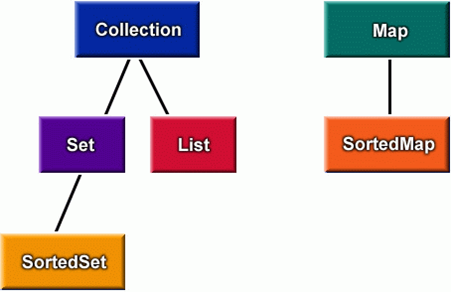
Collection:集合层次中的根接口,JDK没有提供这个接口直接的实现类。
Set:不能包含重复的元素。SortedSet是一个按照升序排列元素的Set。
List:是一个有序的集合,可以包含重复的元素。提供了按索引访问的方式。
Map:包含了key-value对。Map不能包含重复的key。SortedMap是一个按照升序排列key的Map。

ArrayList
ArrayList:我们可以将其看作是能够自动增长容量的数组。
利用ArrayList的toArray()返回一个数组。
Arrays.asList()返回一个列表。
迭代器(Iterator)给我们提供了一种通用的方式来访问集合中的元素。
import java.util.*;class ArrayListTest{public static void printElements(Collection c){Iterator it=c.iterator();while(it.hasNext()){System.out.println(it.next());}}public static void main(String[] args){//ArrayList al=new ArrayList();/*al.add("winsun");al.add("weixin");al.add("mybole");*//*al.add(new Point(3,3));al.add(new Point(2,2));al.add(new Point(4,4));*//*for(int i=0;i<al.size();i++){System.out.println(al.get(i));}*//*System.out.println(al);Object[] objs=al.toArray();for(int i=0;i<objs.length;i++){System.out.println(objs[i]);}List l=Arrays.asList(objs);System.out.println(l);printElements(al);*///l.add("zhangsan");//Iterator it=al.iterator();/*Iterator it=l.iterator();it.next();it.remove();while(it.hasNext()){System.out.println(it.next());}*/Student s1=new Student(2,"zhangsan");Student s2=new Student(1,"lisi");Student s3=new Student(3,"wangwu");Student s4=new Student(2,"mybole");ArrayList al=new ArrayList();al.add(s1);al.add(s2);al.add(s3);al.add(s4);Collections.sort(al,Collections.reverseOrder());//new Student.StudentComparator());printElements(al);}}class Point{int x,y;Point(int x,int y){this.x=x;this.y=y;}public String toString(){return "x="+x+","+"y="+y;}}class Student implements Comparable{int num;String name;static class StudentComparator implements Comparator{public int compare(Object o1,Object o2){Student s1=(Student)o1;Student s2=(Student)o2;int result=s1.num > s2.num ? 1 : (s1.num==s2.num ? 0 : -1);if(result==0){result=s1.name.compareTo(s2.name);}return result;}}Student(int num,String name){this.num=num;this.name=name;}public int compareTo(Object o){Student s=(Student)o;return num > s.num ? 1 : (num==s.num ? 0 : -1);}public String toString(){return num+":"+name;}}Collections类
排序:Collections.sort()
(1)自然排寻(naturalordering );
(2)实现比较器(Comparator)接口。
取最大和最小的元素:Collections.max()、Collections.min()。
在已排序的List中搜索指定的元素:Collectons.binarySearch()。
LinkedList
LinkedList是采用双向循环链表实现的。
利用LinkedList实现栈(stack)、队列(queue)、双向队列(double-endedqueue )。
import java.util.*;class MyStack{private LinkedList ll=new LinkedList();public void push(Object o){ll.addFirst(o);}public Object pop(){return ll.removeFirst();}public Object peek(){return ll.getFirst();}public boolean empty(){return ll.isEmpty();}public static void main(String[] args){MyStack ms=new MyStack();ms.push("one");ms.push("two");ms.push("three");System.out.println(ms.pop());System.out.println(ms.peek());System.out.println(ms.pop());System.out.println(ms.empty());}}import java.util.*;class MyQueue{private LinkedList ll=new LinkedList();public void put(Object o){ll.addLast(o);}public Object get(){return ll.removeFirst();}public boolean empty(){return ll.isEmpty();}public static void main(String[] args){MyQueue mq=new MyQueue();mq.put("one");mq.put("two");mq.put("three");System.out.println(mq.get());System.out.println(mq.get());System.out.println(mq.get());System.out.println(mq.empty());}}双向循环链表

队列
队列(Queue)是限定所有的插入只能在表的一端进行,而所有的删除都在表的另一端进行的线性表。
表中允许插入的一端称为队尾(Rear),允许删除的一端称为队头(Front)。
队列的操作是按先进先出(FIFO)的原则进行的。
队列的物理存储可以用顺序存储结构,也可以用链式存储结构。

ArrayList和LinkedList的比较
ArrayList底层采用数组完成,而LinkedList则是以一般的双向链表(double-linked list)完成,其内每个对象除了数据本身外,还有两个引用,分别指向前一个元素和后一个元素。
如果我们经常在List的开始处增加元素,或者在List中进行插入和删除操作,我们应该使用LinkedList,否则的话,使用ArrayList将更加快速。
HashSet
实现Set接口的hashtable(哈希表),依靠HashMap来实现的。
我们应该为要存放到散列表的各个对象定义hashCode()和equals()。
import java.util.*;class HashSetTest{public static void main(String[] args){HashSet hs=new HashSet();/*hs.add("one");hs.add("two");hs.add("three");hs.add("one");*/hs.add(new Student(1,"zhangsan"));hs.add(new Student(2,"lisi"));hs.add(new Student(3,"wangwu"));hs.add(new Student(1,"zhangsan"));Iterator it=hs.iterator();while(it.hasNext()){System.out.println(it.next());}}}class Student{int num;String name;Student(int num,String name){this.num=num;this.name=name;}public int hashCode(){return num*name.hashCode();} public boolean equals(Object o){Student s=(Student)o;return num==s.num && name.equals(s.name);}public String toString(){return num+":"+name;}}散列表
散列表又称为哈希表。散列表算法的基本思想是:
以结点的关键字为自变量,通过一定的函数关系(散列函数)计算出对应的函数值,以这个值作为该结点存储在散列表中的地址。
当散列表中的元素存放太满,就必须进行再散列,将产生一个新的散列表,所有元素存放到新的散列表中,原先的散列表将被删除。在Java语言中,通过负载因子(load factor)来决定何时对散列表进行再散列。例如:如果负载因子是0.75,当散列表中已经有75%的位置已经放满,那么将进行再散列。
负载因子越高(越接近1.0),内存的使用效率越高,元素的寻找时间越长。负载因子越低(越接近0.0),元素的寻找时间越短,内存浪费越多。
HashSet类的缺省负载因子是0.75TreeSet
TreeSet是依靠TreeMap来实现的。
TreeSet是一个有序集合,TreeSet中元素将按照升序排列,缺省是按照自然顺序进行排列,意味着TreeSet中元素要实现Comparable接口。
我们可以在构造TreeSet对象时,传递实现了Comparator接口的比较器对象。
import java.util.*;class TreeSetTest{public static void main(String[] args){TreeSet ts=new TreeSet(new Student.StudentComparator());/*ts.add("winsun");ts.add("weixin");ts.add("mybole");*/ts.add(new Student(2,"lisi"));ts.add(new Student(1,"wangwu"));ts.add(new Student(3,"zhangsan"));ts.add(new Student(3,"mybole"));Iterator it=ts.iterator();while(it.hasNext()){System.out.println(it.next());}}}class Student implements Comparable{int num;String name;static class StudentComparator implements Comparator{public int compare(Object o1,Object o2){Student s1=(Student)o1;Student s2=(Student)o2;int result=s1.num > s2.num ? 1 : (s1.num==s2.num ? 0 : -1);if(result==0){result=s1.name.compareTo(s2.name);}return result;}}Student(int num,String name){this.num=num;this.name=name;}public int compareTo(Object o){Student s=(Student)o;return num > s.num ? 1 : (num==s.num ? 0 : -1);}public String toString(){return num+":"+name;}}HashSet和TreeSet的比较
HashSet是基于Hash算法实现的,其性能通常都优于TreeSet。我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSet。
基于Hash算法实现的,其性能通常都优于TreeSet。我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSeHashSet是基于Hash算法实现的,其性能通常都优于TreeSet。我们通常都应该使用HashSet,在我们需要排序的功能时,我们才使用TreeSetHashMap
HashMap对key进行散列。
keySet()、values()、entrySet()。
import java.util.*;class HashMapTest{public static void printElements(Collection c){Iterator it=c.iterator();while(it.hasNext()){System.out.println(it.next());}}public static void main(String[] args){HashMap hm=new HashMap();hm.put("one","zhangsan");hm.put("two","lisi");hm.put("three","wangwu");System.out.println(hm.get("one"));System.out.println(hm.get("two"));System.out.println(hm.get("three"));Set keys=hm.keySet();System.out.println("Key:");printElements(keys);Collection values=hm.values();System.out.println("Value:");printElements(values);Set entry=hm.entrySet();//printElements(entry);Iterator it=entry.iterator();while(it.hasNext()){Map.Entry me=(Map.Entry)it.next();System.out.println(me.getKey()+":"+me.getValue());}}}TreeMap
nTreeMap按照key进行排序。
HashMap和TreeMap的比较
和Set类似,HashMap的速度通常都比TreeMap快,只有在需要排序的功能的时候,才使用TreeMap。
Java1.0/1.1的集合类
Vector:用ArrayList代替Vector。
Hashtable:用HashMap代替Hashtable。
Satck:用LinkedList代替Stack。
Properties
import java.util.*;import java.io.*;class PropTest{public static void main(String[] args){/*Properties pps=System.getProperties();pps.list(System.out);*/Properties pps=new Properties();try{pps.load(new FileInputStream("winsun.ini"));Enumeration enum=pps.propertyNames();while(enum.hasMoreElements()){String strKey=(String)enum.nextElement();String strValue=pps.getProperty(strKey);System.out.println(strKey+"="+strValue);}}catch(Exception e){e.printStackTrace();}}}- java集合类总结
- java集合类总结
- JAVA集合类总结
- java集合类总结
- java集合类总结
- java集合类总结
- JAVA集合类总结
- java集合类总结
- JAVA集合类总结
- java集合类总结
- java集合类总结
- java集合类总结
- java集合类总结
- java集合类总结
- JAVA集合类总结
- java集合类总结
- Java集合类总结
- java集合类总结
- Python:桌面气泡提示功能实现
- 学习笔记2012 4 10
- android平台下使用点九PNG技术
- 写一个寻找数组中第二大的数的程序
- php入门之九九乘法表代码
- java集合类总结
- 视频转码
- 经典排序算法3(选择排序)
- C++ 对象指针(函数指针)
- linux下mysql配置文件my.cnf详解
- C++第12周报告(一)用循环控制语句编写程序,完成表达式的计算
- java学习笔记之Arrays.asList
- POJ 2455 网络流英文阅读题
- 如何计算空间复杂度


