模式识别经常用到的距离测度
来源:互联网 发布:c#书籍推荐知乎 编辑:程序博客网 时间:2024/05/01 07:09
http://repository.cmu.edu/cgi/viewcontent.cgi?article=1447&context=robotics
1. Euclidean distance
2. Mahalanobis distance
Please refer to the following explenation as well as the attached file which is even clearer

Distance is not always what it seems
You can generalize these ideas to the multivariate normal distribution.The following graph shows simulated bivariate normal data that is overlaid withprediction ellipses. The ellipses in the graph are the 10% (innermost), 20%, ..., and 90% (outermost) prediction ellipses for the bivariate normal distribution that generated the data. The prediction ellipses are contours of the bivariate normal density function. The probability density is high for ellipses near the origin, such as the 10% prediction ellipse. The density is low for ellipses are further away, such as the 90% prediction ellipse.
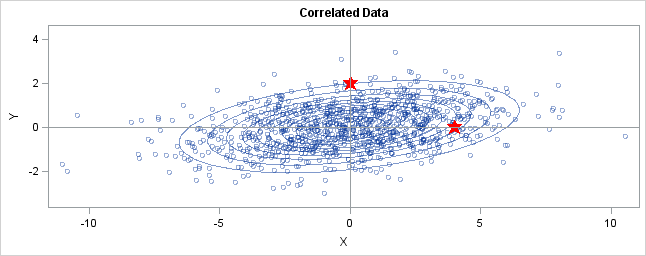
In the graph, two observations are displayed by using red stars as markers. The first observation is at the coordinates (4,0), whereas the second is at (0,2). The question is: which marker is closer to the origin? (The origin is the multivariate center of this distribution.)
The answer is, "It depends how you measure distance." The Euclidean distances are 4 and 2, respectively, so you might conclude that the point at (0,2) is closer to the origin. However, for this distribution, the variance in the Y direction is less than the variance in the X direction, so in some sense the point (0,2) is "more standard deviations" away from the origin than (4,0) is.</p
Notice the position of the two observations relative to the ellipses. The point (0,2) is located at the 90% prediction ellipse, whereas the point at (4,0) is located at about the 75% prediction ellipse. What does this mean? It means that the point at (4,0) is "closer" to the origin in the sense that you are more likely to observe an observation near (4,0) than to observe one near (0,2). The probability density is higher near (4,0) than it is near (0,2).
In this sense, prediction ellipses are a multivariate generalization of "units of standard deviation." You can use the bivariate probability contours to compare distances to the bivariate mean. A pointp is closer than a pointq if the contour that contains p is nested within the contour that containsq.
Defining the Mahalanobis distance
You can use the probability contours to define the Mahalanobis distance.The Mahalanobis distance has the following properties:
- It accounts for the fact that the variances in each direction are different.
- It accounts for the covariance between variables.
- It reduces to the familiar Euclidean distance for uncorrelated variables with unit variance.
For univariate normal data, the univariate z-score standardizes the distribution (so that it has mean 0 and unit variance) and gives a dimensionless quantity that specifies the distance from an observation to the mean in terms of the scale of the data. For multivariate normal data with mean μ and covariance matrix Σ, you can decorrelate the variables and standardize the distribution by applying the Cholesky transformationz = L-1(x - μ), whereL is the Cholesky factor of Σ, Σ=LLT.
After transforming the data, you can compute the standard Euclidian distance from the pointz to the origin. In order to get rid of square roots, I'll compute the square of the Euclidean distance, which is dist2(z,0) = zTz.This measures how far from the origin a point is, and it is the multivariate generalization of a z-score.
You can rewrite zTz in terms of the original correlated variables. The squared distance Mahal2(x,μ) is
= zT z
= (L-1(x - μ))T (L-1(x - μ))
= (x - μ)T (LLT)-1 (x - μ)
= (x - μ)T Σ -1 (x - μ)
The last formula is the definition of the squared Mahalanobis distance. The derivation uses several matrix identities such as (AB)T = BTAT, (AB)-1 = B-1A-1, and (A-1)T = (AT)-1. Notice that if Σ is the identity matrix, then the Mahalanobis distance reduces to the standard Euclidean distance betweenx and μ.
The Mahalanobis distance accounts for the variance of each variable and the covariance between variables. Geometrically, it does this by transforming the data into standardized uncorrelated data and computing the ordinary Euclidean distance for the transformed data. In this way, the Mahalanobis distance is like a univariate z-score: it provides a way to measure distances that takes into account the scale of the data.
--------
Formally, the Mahalanobis distance of a multivariate vector 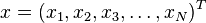 from a group of values with mean
from a group of values with mean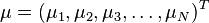 andcovariance matrix
andcovariance matrix is defined as:
is defined as:
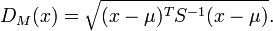 [2]
[2]
Mahalanobis distance (or "generalized squared interpoint distance" for its squared value[3]) can also be defined as a dissimilarity measure between two random vectors  and
and of the samedistribution with thecovariance matrix :
of the samedistribution with thecovariance matrix :
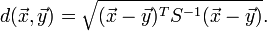
If the covariance matrix is the identity matrix, the Mahalanobis distance reduces to theEuclidean distance. If the covariance matrix isdiagonal, then the resulting distance measure is called thenormalized Euclidean distance:

where 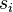 is thestandard deviation of the
is thestandard deviation of the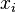 and
and over the sample set.
over the sample set.
Intuitive explanation
Consider the problem of estimating the probability that a test point in N-dimensionalEuclidean space belongs to a set, where we are given sample points that definitely belong to that set. Our first step would be to find the average or center of mass of the sample points. Intuitively, the closer the point in question is to this center of mass, the more likely it is to belong to the set.
However, we also need to know if the set is spread out over a large range or a small range, so that we can decide whether a given distance from the center is noteworthy or not. The simplistic approach is to estimate thestandard deviation of the distances of the sample points from the center of mass. If the distance between the test point and the center of mass is less than one standard deviation, then we might conclude that it is highly probable that the test point belongs to the set. The further away it is, the more likely that the test point should not be classified as belonging to the set.
This intuitive approach can be made quantitative by defining the normalized distance between the test point and the set to be . By plugging this into the normal distribution we can derive the probability of the test point belonging to the set.
. By plugging this into the normal distribution we can derive the probability of the test point belonging to the set.
The drawback of the above approach was that we assumed that the sample points are distributed about the center of mass in a spherical manner. Were the distribution to be decidedly non-spherical, for instance ellipsoidal, then we would expect the probability of the test point belonging to the set to depend not only on the distance from the center of mass, but also on the direction. In those directions where the ellipsoid has a short axis the test point must be closer, while in those where the axis is long the test point can be further away from the center.
Putting this on a mathematical basis, the ellipsoid that best represents the set's probability distribution can be estimated by building the covariance matrix of the samples. The Mahalanobis distance is simply the distance of the test point from the center of mass divided by the width of the ellipsoid in the direction of the test point.
3. Hamming distance
4. Hausdorff distance
Definition

Let X and Y be two non-empty subsets of a metric space (M, d). We define their Hausdorff distanced H(X, Y) by

where sup represents the supremum and inf the infimum.
Equivalently
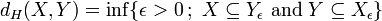 ,[2]
,[2]
where
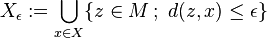 ,
,
that is, the set of all points within  of the set
of the set (sometimes called the-fattening of or a generalized ball of radius around).
(sometimes called the-fattening of or a generalized ball of radius around).
[edit]Remark
It is not true in general that if  , then
, then
 .
.
For instance, consider the metric space of the real numbers  with the usual metric
with the usual metric induced by the absolute value,
induced by the absolute value,
 .
.
Take
 .
.
Then 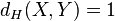 . However
. However because
because , but
, but .
.
[edit]Properties
In general, dH(X,Y) may be infinite. If bothX and Y are bounded, then dH(X,Y) is guaranteed to be finite.
We have dH(X,Y) = 0 if and only if X andY have the same closure.
On the set of all non-empty subsets of M, dH yields an extendedpseudometric.
On the set F(M) of all non-empty compact subsets of M,dH is a metric. If M is complete, then so is F(M).[3] IfM is compact, then so is F(M). The topology of F(M) depends only on the topology of M, not on the metricd.
5. PCA Distance measures based on PCA or
eigenspaces are perhaps the most popular. The underlying
assumption when using PCA is that the measurement
data can be explained (modulo noise) by a small dimensional linear subspace of
6. Discriminative analysis, of which LDA [3, 16]
is the most popular, on the other hand explicitly tries to
find discriminative distance measures that separate the different
classes from each other as much as possible
7. Support Vector Machines that
maximize the margin between different classes
8. Bayesian
approaches to classification estimates probability density
models for each class and classifies an input query using the
Bayes rule. For the two class case, the log-odds ratio can be
considered to be a discriminative distance measure
such approaches typically suffer
from the need to specify an appropriate model for each
class as well as estimating such models reliably from data
- 模式识别经常用到的距离测度
- 模式识别相似性测度距离计算---欧式距离
- 模式识别相似性测度距离计算---tanimoto距离
- 常用的距离测度
- 模式识别相似性测度距离计算---马氏距离
- 模式识别相似性测度距离计算---几种距离对比
- 一种改进的余弦距离测度
- 模式识别相似性测度距离计算---夹角余弦和特征二值得夹角余弦
- 经常用到的SQL
- 经常用到的DML
- CSS 经常用到的
- 经常用到的网址
- 经常用到的sql
- 经常用到的命令
- 经常用到的方法
- 经常用到的快捷键
- 范数、测度和距离.
- 模式相似性测度-距离
- 宏定义读取数据机构偏移量
- arx2010在vs2008中fatal error C1083: Cannot open include file: 'type_traits'
- django网站部署
- 设置Webview的滚动条属性- 滚动条白边解决方法
- 组合
- 模式识别经常用到的距离测度
- 各式各样的正则表达式参考大全
- unix--文件管理01
- 西南/重庆大学2012年 自考本科生申请学士学位通知
- Linux高级文件编程 标准C部分笔记
- 编码和加解密测试小工具
- 使用Automake 创建和使用静态库/动态库
- H3C背靠惠普冲击高端市场 思科面临新挑战
- 胡思乱想


