Oracle ASM 详解
来源:互联网 发布:如何优化百度推广排名 编辑:程序博客网 时间:2024/05/16 17:04
ASM:Automatic Storage Management, 是Oracle 主推的一种面向Oracle的存储解决方案, ASM 和 RDBMS 非常相似,ASM 也是由实例和文件组成, 也可以通过sqlplus 工具来维护。
ASM 实例的创建和删除也可以用DBCA 这个命令来操作。在dbca 的第一个界面选择配置自动存储管理就可以了。 ASM 实例需要CSS 进程, 如果是非RAC 环境, 在启动ASM 实例之前会提示用脚本
$ORACLE_HOME/bin/localconfig add 启动CSS。
1. ASM 实例由SGA 和后台进程组成。
1.1 SGA 组成:
ASM 实例的SGA包括Buffer Cache, Share Pool, Large Pool等。 需要注意的是Share Pool, 因为Extent Map 要放在这部分的内存中,需要更具数据量来估计Extent Map 的大小做相应的调整。
Extent Map 的大小可以根据所有文件大小的和来估算,使用下面的语句来计算所有文件和:
Select sum(bytes)/(1024*1024*1024) from v$datafile;
Select sum(bytes)/(1024*1024*1024) from v$logfile a, v$log b where a.Group#=b.Group#;
Select sum(bytes)/(1024*1024*1024) from v$tempfile where status='ONLINE';
这3个sum 的总和对应着数据库存放ASM中所有文件大小总和, 对于使用External Redundancy 的磁盘组, 每100G 需要1MB 的Extent Map, 根据这个比例计算Extent Map 所需要的空间,在加上额外的2MB就可以了。 在实际工作中一般不需要考虑ASM SGA的配置, 使用Oracle 提供的缺省值就可以了。
1.2 后台进程
ASM 实例比RDBMS 实例多2个进程: RBAL 和 ABRn。
RBAL: 这个进程也叫Rebalancer进程, 负责规划ASM 磁盘组的Reblance活动。
ABRn:是RBAL进程的子进程,这个进程在数量上可以有多个, n从1~9, 这组进程负责真正完成Reblance活动。
使用ASM 作为存储的RDBMS 实例也会多出2个进程: RBAL 和 ASMB
RBAL: 这个进程的主要功能是打开每个磁盘的所有磁盘和数据的Rebalance。
ASMB: 这个进程作为ASM 实例和数据库实例之间的信息通道。 这个进程负责与ASM 实例的通信, 它先利用Diskgroup Name 从CSS 获得管理该Diskgroup 的ASM 实例的连接串, 然后建立到ASM 的持久连接, 两个实例之间通过这条连接定期交换信息,同时也是一种心跳机制。
RDBMS 实例要想使用ASM 作为存储, RDBMS 实例必须在启动时从ASM 实例获得Extent Map, 以后发生磁盘组的维护操作, ASM 实例还要把Extent Map的更新信息通知给RDBMS 实例, 这2个实例间的信息交换就是他你哦刚过ASMB 进程完成的。 这也就为什么: ASM 实例必须要先于数据库实例启动,和数据库实例同步运行,迟于数据库实例关闭。
注意: ASM 实例和数据库实例的关系可以是1:1, 也可以是1:n。如果是1:n, 最好为ASM 安装单独的ASM_HOME。
2. ASM 配置
ASM 可以使用裸设备 或者ASMLib 方式, 因为裸设别的维护比较复杂,在此只讲解ASMLib 方式。
对应不同的操作系统, 需要不同的包,下载的时候一定要和操作系统内核一致。 我的操作系统是 Red hat 4 update 7. 内核版本是2.6.9-78.ELSMP。
oracleasmlib-2.0.4-1.el4.i386.rpm
oracleasm-support-2.1.3-1.el4.i386.rpm
oracleasm-2.6.9-78.EL-2.0.5-1.el4.i686.rpm
http://www.oracle.com/technology/tech/linux/asmlib/index.html
该页面有下载地址,注意选择CPU 类型。 asmlib 和 support,在同一个页面下载。
安装包:
#rpm -ivh *.rpm
安装完之后进行配置:
#/etc/init.d/oracleasm configure
会有相应的提示, 回答 oracle , dba, y, y 就可以了
分别对应默认用户, 默认组,随系统自启动, 启动时设置权限。
/etc/init.d/oracleasm createdisk VOL1 /dev/sdc1
/etc/init.d/oracleasm scandisks
/etc/init.d/oracleasm listdisks
关于oracleasm 的更多用法参考help:
[root@node1 ~]# /etc/init.d/oracleasm --help
Usage: /etc/init.d/oracleasm {start|stop|restart|enable|disable|configure
|createdisk|deletedisk|querydisk|listdisks|scandisks|status}
3. ASM 实例配置
3.1 初始化参数
[oracle@node1 bin]$ export ORACLE_SID=+ASM1
[oracle@node1 bin]$ sqlplus / as sysdba
SQL*Plus: Release 10.2.0.1.0 - Production on Sun Feb 21 19:10:51 2010
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
With the Partitioning, Real Application Clusters, OLAP and Data Mining options
SQL> create pfile from spfile;
File created.
SQL> show parameter asm
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
asm_diskgroups string FLASH_RECOVERY_AREA, DATA
asm_diskstring string
asm_power_limit integer 1
[oracle@node2 dbs]$ pwd
/u01/app/oracle/product/10.2.0/db_1/dbs
[oracle@node2 dbs]$ ls
ab_+ASM2.dat hc_rac2.dat initrac2.ora orapwrac2
hc_+ASM2.dat init+ASM2.ora orapw+ASM2
[oracle@node2 dbs]$ more init+ASM1.ora
+ASM2.asm_diskgroups='FLASH_RECOVERY_AREA'#Manual Dismount
+ASM1.asm_diskgroups='FLASH_RECOVERY_AREA','DATA'#Manual Mount
*.asm_diskgroups='FLASH_RECOVERY_AREA','DATA'
*.background_dump_dest='/u01/app/oracle/admin/+ASM/bdump'
*.cluster_database=true
*.core_dump_dest='/u01/app/oracle/admin/+ASM/cdump'
+ASM2.instance_number=2
+ASM1.instance_number=1
*.instance_type='asm'
*.large_pool_size=12M
*.remote_login_passwordfile='exclusive'
*.user_dump_dest='/u01/app/oracle/admin/+ASM/udump'
相关说明:
ASM 实例的SGA 需要的内存很小, 一般默认值即可, 无需修改。 ASM SGA的默认值如下:
SHARED_POOL_SIZE = 48M
LARGE_POOL_SIZE = 12M
SHARED_POOL_RESERVED_SIZE = 24M
SGA_MAX_SIZE = 88M
这些默认值可以在sqlplus 中通过show parameter 查看。
Instance_type: 对于ASM 实例, 这个应该设置成ASM, 如果是数据库实例,则是RDBMS.
DB_UNIQUE_NAME: 这个参数使用缺省值+ASM即可
SQL> show parameter asm_power_limit
NAME TYPE VALUE
----------------------- --------- ---------------
asm_power_limit integer 1
ASM_POWER_LIMIT: 当在磁盘组中添加删除磁盘时,磁盘组会自动对数据在新旧磁盘间重新分配, 从而实现分散IO, 这个过程就叫再平衡(Rebalance);
这个动作会在磁盘间移动数据,因此虽然是联机操作,仍然会影响部分性能,所以要在系统空闲的时候进行。 该参数控制Rebalance速度, 取值范围0-11. 最小值0 代表不做Rebalance, 最大值11 代表最快的速度,也意味着严重影响性能, 1 代表最慢的速度和最小的性能影响。 除了在初始化参数中定义该参数, 也可以在操作时指定。
比如:
SQL> alter diskgroup DATA rebalance power 5;
Disk groups can be rebalanced manually using the REBALANCE clause of the ALTER DISKGROUP statement. If the POWER clause is omitted the ASM_POWER_LIMIT parameter value is used. Rebalancing is only needed when the speed of the automatic rebalancing is not appropriate.
ASM_DISKSTRING: 定义哪些磁盘可以被ASM 使用, ASM 实例启动时就根据这个参数值扫描发现ASM磁盘,配置了这个参数以后,还必须确认ORACLE 用户对这些磁盘有操作的权限
1. 如果使用裸设备, 用逗号分隔每个设备名:
Asm_diskstring='/dev/raw/raw1','/dev/raw/raw2','/dev/raw/raw3'
2. 如果使用ASMLib时,就需要使用"ORCL:磁盘名"
Asm_diskstring='ORCL:VOL1'
3. 使用ASMLib 时, 也可以使用通配符
Asm_diskstring='ORCL:VOL*'
ASM_DISKGROUPS: 这个参数用于定义ASM 实例启动后自动挂载的磁盘组, 如果不自动挂载, 也可以使用命令挂载。
注意: ASM 实例启动即可以通过pfile, 也可以通过spfile,如果使用spfile启动,那么如果创建新的磁盘组, 这个参数会被自动修改, 下次启动时会自动挂载这个新建的磁盘组,如果是使用pfile, 这个参数不会自动更新, 需要手工的更新。
3.2 CSS 进程
无论是否在RAC 环境下, ASM 实例都是需要CSS 进程的, 所以,如果是非RAC 环境, 在启动ASM 实例之前用脚本
$ORACLE_HOME/bin/localconfig add 启动CSS, 否则ASM 实例启动时会报ORA-29701: unable to connect to Cluster Manager, 并提示执行该脚本
3.3 ASM 实例的相关操作
ASM 管理 登录,启动,关闭:
[oracle@node2 dbs]$ export ORACLE_SID=+ASM2
[oracle@node2 dbs]$ sqlplus / as sysdba
SQL> startup
SQL> shutdown immediate;
检查disk group信息的SQL:
SQL> col state format a10
SQL> col name format a15
SQL> col failgroup format a20
SQL> set line 200
SQL> select STATE,REDUNDANCY,TOTAL_MB,FREE_MB,NAME,FAILGROUP
from v$asm_disk;
SQL>select GROUP_NUMBER,NAME,STATE,TYPE,TOTAL_MB,FREE_MB,
UNBALANCED from v$asm_diskgroup;
创建新的diskgroup
SQL> create diskgroup dgtest normal redundancy
2 failgroup DATA1 disk '/dev/oracleasm/VOL5' name DATA1
3 failgroup DATA2 disk '/dev/oracleasm/VOL6' name DATA2;
删除diskgroup
SQL> drop diskgroup DATA including contents;
-- 对于多结点的diskgroup, 只能有在一个asm实例上挂载之后才能被dorp, 其他结点必须dismount。
手动mount命令
ALTER DISKGROUP ALL DISMOUNT;
ALTER DISKGROUP ALL MOUNT;
ALTER DISKGROUP DATA DISMOUNT;
ALTER DISKGROUP DATA MOUNT;
为diskgroup增加disk
SQL> alter diskgroup DATA add disk '/dev/oracleasm/VOL5' name
VOL5,'/dev/oracleasm/VOL6' name VOL6;
从diskgroup删除disk
SQL> alter diskgroup DATA drop disk VOL5;
取消删除disk的命令,只能在上述命令没执行完成的时候有效
ALTER DISKGROUP DATA UNDROP DISKS;
The UNDROP DISKS clause of the ALTER DISKGROUP statement allows pending disk drops to be undone. It will not revert drops that have completed, or disk drops associated with the
dropping of a disk group.
数据文件的管理
Aliases allow you to reference ASM files using user-friendly names, rather than the fully
qualified ASM filenames.
-- Create an alias using the fully qualified filename.
ALTER DISKGROUP disk_group_1 ADD ALIAS '+disk_group_1/my_dir/my_file.dbf'
FOR '+disk_group_1/mydb/datafile/my_ts.342.3';
-- Create an alias using the numeric form filename.
ALTER DISKGROUP disk_group_1 ADD ALIAS '+disk_group_1/my_dir/my_file.dbf'
FOR '+disk_group_1.342.3';
-- Rename an alias.
ALTER DISKGROUP disk_group_1 RENAME ALIAS '+disk_group_1/my_dir/my_file.dbf'
TO '+disk_group_1/my_dir/my_file2.dbf';
-- Delete an alias.
ALTER DISKGROUP disk_group_1 DELETE ALIAS '+disk_group_1/my_dir/my_file.dbf';
-- Drop file using an alias.
ALTER DISKGROUP disk_group_1 DROP FILE '+disk_group_1/my_dir/my_file.dbf';
-- Drop file using a numeric form filename.
ALTER DISKGROUP disk_group_1 DROP FILE '+disk_group_1.342.3';
-- Drop file using a fully qualified filename.
ALTER DISKGROUP disk_group_1 DROP FILE '+disk_group_1/mydb/datafile/my_ts.342.3';
-- create datafile
SQL> create tablespace users2 datafile '+TESTDB_DATA1' size 100m;
注意事项:
1. ASM 实例在配置好并且创建了ASM磁盘组之后,还必须保证已经注册到Listener中后才能在数据库实例中使用,否则就需要手工注册ASM 实例:
SQL>alter system register;
2. 一旦数据库实例使用ASM 作为存储, 那么在数据库实例运行时是无法关闭ASM实例的。 否则会报 ORA-15097:cannot SHUTDOWN ASM instance with connected RDBMS instance. 错误。
4. Oracle 中删除 ASM 实例
删除自动存储管理实例+ASM实例+ASM的删除是在数据库被卸载之后完成的,并删除/ORACLE_HOME/dbs目录下的所有文件(除了与ASM相关的)。因此必须完成下列步骤:
4.1在命令提示符中,设置oracle_sid环境变量为+ASM实例:
# export oracle_sid=+ASM
4.2启动SQL*Plus并以sys用户连接到自动存储管理+ASM实例:
# sqlplus / as sysdba
4.3使用下列命令来确定是否有数据库实例正在使用自动存储管理实例+ASM:
SQL>select instance_name from v$asm_client;
该命令结果列出所有正在运行并使用+ASM实例的数据库实例。只要+ASM包含正在支持的数据库实例,就不能删除该+ASM实例。(其实可以先shutdown对应的数据库实例,然后从asmcmd进入磁盘组所在目录,删掉对应的数据库目录和文件就可以了)。
4.4 如果没有与+ASM相关联的数据库实例,则删除与该实例相关联的磁盘组。
首先,识别与+ASM相关联的磁盘组:
SQL>select name from v$asm_diskgroup;
其次,用下列命令删除每个要删除的磁盘组:
SQL>drop diskgroup<disk_group_name>including contents;
4.5 关闭+ASM实例并退出SQL*Plus:
SQL>shutdown
SQL>exit
4.6 在命令提示符中输入下列命令,删除+ASM服务(我没找到这个命令,所以没有运行):
oradim -delete -asmsid +ASM
5. ASMCMD 工具
ASM 实例的管理除了sqlplus, Oracle 还提供了asmcmd 命令, 具体参考help。
[oracle@node1 bin]$ which asmcmd
/u01/app/oracle/product/10.2.0/db_1/bin/asmcmd
[oracle@node1 bin]$ cd /u01/app/oracle/product/10.2.0/db_1/bin/
[oracle@node1 bin]$ ./asmcmd
ASMCMD> ls
DATA/
FLASH_RECOVERY_AREA/
ASMCMD> help
asmcmd [-p] [command]
The environment variables ORACLE_HOME and ORACLE_SID determine the
instance to which the program connects, and ASMCMD establishes a
bequeath connection to it, in the same manner as a SQLPLUS / AS
SYSDBA. The user must be a member of the SYSDBA group.
Specifying the -p option allows the current directory to be displayed
in the command prompt, like so:
ASMCMD [+DATAFILE/ORCL/CONTROLFILE] >
[command] specifies one of the following commands, along with its
parameters.
Type "help [command]" to get help on a specific ASMCMD command.
commands:
--------
cd
du
find
help
ls
lsct
lsdg
mkalias
mkdir
pwd
rm
rmalias
ASMCMD>
----- 2010年9月23日补充--------
里面有删除别名的语法, 现在已经不支持了。 之前没有测试,写文章不严禁。 在google上搜这个问题的时候,发现有人转载了我的文章,但是这个错误还是没有发现。
刚查阅了一下Oracle 的联机文档, 删除别名用的也是drop。
Example 7-5 Dropping an alias name for an Oracle ASM filename
ALTER DISKGROUP data DROP ALIAS '+data/payroll/compensation.dbf';
地址:
http://download.oracle.com/docs/cd/E11882_01/server.112/e16102/asmfiles.htm#CHDDHIGG
这里面有对ASM 有详细的说明。 可以参考。
顺便补充一点知识:
C:/Users/Administrator.DavidDai>sqlplus /nolog
SQL*Plus: Release 11.2.0.1.0 Production on 星期四 9月
Copyright (c) 1982, 2010, Oracle. All rights reserved
SQL> conn sys/oracle@rac2 as sysdba;
已连接。
SQL> select file_name from dba_data_files;
FILE_NAME
------------------------------------------------------
+DATA/orcl/datafile/users.279.730181053
+DATA/orcl/datafile/sysaux.277.730181053
+DATA/orcl/datafile/undotbs1.278.730181053
+DATA/orcl/datafile/system.276.730181051
+DATA/orcl/datafile/undotbs2.284.730181347
ASM文件名字的格式是固定的:+group/dbname/file type/tag.file.incarnation
在创建db时系统自动创建的几个表空间(system,undotbs,sysaux,users)对应的都是真实的数据文件,即ASM 文件默认的命名格式。而且这个信息都写到了控制文件里。 如果我们使用别名的话,会方便很多。 对于这些创建数据库时自动创建的表空间,我们要他们使用别名,除了手工创建对应别名外,还需要重建控制文件,并且在重建时,datafile 里写别名的信息。 这样数据库也就使用别名了。
http://blog.csdn.net/tianlesoftware/article/details/5314541
Initializing the Oracle ASMLib driver: [FAILED]
上一篇 /下一篇 2010-05-12 15:59:16 / 个人分类:Oracle
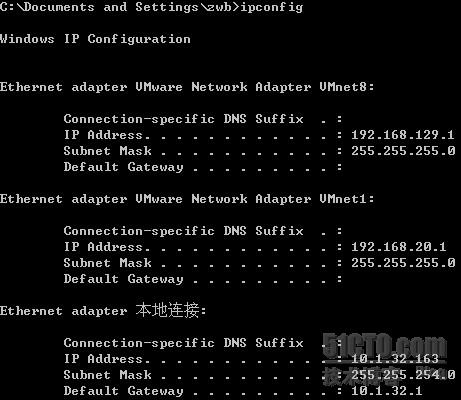
所有节点的时间必须同步,这通常是通过配置NTP服务器实现的。如果用户的网络中已经有一台时间服务器,那么可以所有节点都指向它,否则可以从集群中挑选一个节点作为时间服务器,让其他节点与它同步。下面分别演示这两种方法:
(1)如果公司网络中已经有一台时间服务器
如:192.168.11.10是一台ntp时间服务器
此时NTP服务器的配置文件是/etc/ntp.conf,在每个节点编辑这个文件。
[root@cc-svr-a ~]# vi /etc/ntp.conf
编辑后的内容如下,首选公司的时间服务器。
server 192.168.11.10 prefer
driftfile /var/lib/ntp/drift
broadcastdelay 0.008
(2)如果没有外部时间服务器
这时公司选择集群中某个节点作为时间服务器,NTP服务只需要很少的系统资源。假设选择主节点作为时间服务器,从节点向它同步,其配置方法如下。
编辑主节点的/etc/ntp.conf文件,编辑后的内容如下:
server 127.127.1.0
fudge 127.127.1.0 stratum 11
driftfile /var/lib/ntp/drift
broadcastdelay 0.008
编辑从节点的/etc/ntp.conf文件,编辑后的内容如下:
server 192.168.11.12 prefer #注意192.168.11.12为主节点的IP地址
driftfile /var/lib/ntp/drift
broadcastdelay 0.008
配置完成后,启动NTP服务。
[root@cc-svr-a ~]# /etc/init.d/ntpd start
[root@cc-svr-a ~]# chkconfig –level 345 ntpd on
(3)查看执行情况(主从)
[root@cc-svr-a ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*CC-Node-02 LOCAL(0) 12 u 58 64 17 0.226 -22.698 29.261
创建ASM磁盘组时报错:
Marking disk "ASM1" as an ASM disk: [FAILED]
连着几次失败.不解.
http://xin23.blog.51cto.com/1827266/515388
http://oracle.chinaitlab.com/install/766590.html
后无意中查看参数
[root@RAC-1 /]# /etc/init.d/oracleasm status
Checking if ASM is loaded: no
Checking if /dev/oracleasm is mounted: no
[root@RAC-1 /]# /etc/init.d/oracleasm enable
Writing Oracle ASM library driver configuration: done
Initializing the Oracle ASMLib driver: [ OK ]
Scanning the system for Oracle ASMLib disks: [ OK ]
[root@RAC-1 /]# /etc/init.d/oracleasm createdisk ASM1 /dev/sde1
Marking disk "ASM1" as an ASM disk: [ OK ]
[root@RAC-1 /]# /etc/init.d/oracleasm createdisk ASM3 /dev/sde3
Marking disk "ASM3" as an ASM disk: [ OK ]
[root@RAC-1 /]#
Oracle CRS简介
从Oracle 10gR1 RAC 开始,Oracle推出了自身的集群软件,这个软件的名称叫做Oracle Cluster Ready Service(Oracle集群就绪服务),简称CRS。从Oracle 10gR2开始,包括最新的11g,Oracle将其更名为Clusterware(集群件),但通常意义上我们认为CRS = Clusterware = Oracle Cluster Ready Service = Oracle Cluster Software.
CRS一般用来搭建Oracle的并行数据库,即RAC,但除了与RAC的接口之外,CRS还提供了一组高可用性的应用程序接口(API),用来搭建一般应用程序的高可用集群,即一般我们常说的双机热备,比如使用CRS实现MySQL的双机热备。
Oracle10g New Feature:CRS(Cluster Ready Services)
作者:eygle |English Version 【转载时请以超链接形式标明文章出处和作者信息及本声明】
链接:http://www.eygle.com/archives/2005/10/oracle10g_new_feature_crs.html
Oracle10g CRS(Cluster Ready Services)是Oracle10g RAC的一个新特性,用以提供标准的群集服务接口。
在以前的版本中,Oracle RAC必须借助第三方Cluster软件,但是从Oracle10g开始,我们有了新的选择。
CRS就是这样一个替代产品,用以提供RAC环境中的群集服务。
CRS是一个单独的产品,在构建RAC环境中,需要单独安装。
(在Oracle刚推出CRS时,Oracle还没发明ClusterWare这个词。
所以最初的CRS就是指现在的Clusterware,如果你注意过的话最初Oracle的安装盘上装Clusterware的时候,都说的是CRS。
所以提到Cluster Ready Services,大家都知道指的是Oracle的Clusterware而不是crs daemon.
只不过从10gR2开始,ClusterWare被引入,CRS这个词的含义被Oracle偷偷的缩小了。)
系统启动以后,CRS会自动启动,启动主要由/etc/init.d中的几个脚本完成:
[eygle@raclinux1 init.d]$ ll init*-r-xr-xr-x 1 root root 1951 Jun 27 13:27 init.crs-r-xr-xr-x 1 root root 4735 Jun 27 20:32 init.crsd-r-xr-xr-x 1 root root 35401 Jun 27 13:27 init.cssd-r-xr-xr-x 1 root root 3197 Jun 27 13:27 init.evmd
CRS启动的三个主要的后台进程为:
[oracle@raclinux1 bin]$ ps -ef|grep d.binroot 3140 1 0 23:13 00:00:00 /u01/app/oracle/product/10.2.0/crs/bin/crsd.binoracle 3884 3062 0 23:14 00:00:00 /u01/app/oracle/product/10.2.0/crs/bin/evmd.binoracle 4017 3983 0 23:14 00:00:00 /u01/app/oracle/product/10.2.0/crs/bin/ocssd.binoracle 21117 13799 0 23:29 pts/1 00:00:00 grep d.bin
这几个进程的主要作用如下:
CRSD:- Engine for HA operation - Manages 'application resources'- Starts, stops, and fails 'application resources' over- Spawns separate 'actions' to start/stop/check application resources- Maintains configuration profiles in the OCR (Oracle Configuration Repository)- Stores current known state in the OCR.- Runs as root- Is restarted automatically on failureOCSSD:- OCSSD is part of RAC and Single Instance with ASM- Provides access to node membership- Provides group services- Provides basic cluster locking- Integrates with existing vendor clusteware, when present- Can also runs without integration to vendor clustware- Runs as Oracle.- Failure exit causes machine reboot. --- This is a feature to prevent data corruption in event of a split brain.
注意,ocssd进程在单实例ASM系统中也可以见到,以下是我的一个单实例ASM系统,ocssd进程同样存在:
bash-2.03# ps -ef|grep _+ASM oracle 3264 1 0 Aug 25 ? 0:01 asm_lgwr_+ASM root 12669 8167 0 11:58:56 pts/1 0:00 grep _+ASM oracle 3270 1 0 Aug 25 ? 0:00 asm_rbal_+ASM oracle 3266 1 0 Aug 25 ? 0:05 asm_ckpt_+ASM oracle 3268 1 0 Aug 25 ? 0:00 asm_smon_+ASM oracle 3262 1 0 Aug 25 ? 0:00 asm_dbw0_+ASM oracle 3258 1 0 Aug 25 ? 0:00 asm_pmon_+ASM oracle 3260 1 0 Aug 25 ? 0:00 asm_mman_+ASMbash-2.03# ps -ef|grep ocssd root 12672 8167 0 11:59:01 pts/1 0:00 grep ocssd oracle 5374 1 0 Apr 07 ? 0:01 /opt/oracle/product/10.1.0/bin/ocssd.binbash-2.03#
ocssd进程非常重要,如果该进程异常中止,会导致系统crash。
在某些极端情况下,如果ocssd无法正常启动,会导致操作系统循环重启。这时候需要DBA介入进行一些特殊处理。(解决循环重启的问题是修改/etc/init.d/init.cssd文件,注释掉其中FAST_REBOOT语句)
EVMD:- Generates events when things happen- Spawns a permanent child evmlogger- Evmlogger, on demand, spawns children- Scans callout directory and invokes callouts.- Runs as Oracle.- Restarted automatically on failure
[oracle@raclinux1 ~]$ cd $ORA_CRS_HOME/bin[oracle@raclinux1 bin]$ pwd/u01/app/oracle/product/10.2.0/crs/bin[oracle@raclinux1 bin]$ ./crs_statNAME=ora.RACDB.RACDB1.instTYPE=applicationTARGET=ONLINESTATE=ON LINE on raclinux1NAME=ora.RACDB.RACDB2.instTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.RACDB.dbTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.ASM1.asmTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.LISTENER2_RACLINUX1.lsnrTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.LISTENER_RACLINUX1.lsnrTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.gsdTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.on sTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.vipTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1[oracle@raclinux1 bin]$
1) Linux:
To verify service as root user issue,
# /sbin/service ntpd status
ntpd (pid 4423) is running...
Check process is running or not by.
# ps -ef|grep ntp
ntp 4209 1 0 Mar10 ? 00:00:00 ntpd -u ntp:ntp -p /var/run/ntpd.pid -x
# grep OPTIONS /etc/sysconfig/ntpd
OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -x"
If NTP service is not started then to start the service issue,
To start the service issue,
# /sbin/service ntpd start
2) Solaris:
To verify the service issue,
# /usr/bin/svcs ntp
STATE STIME FMRI
online 3:29:11 svc:/network/ntp:default
# ps -ef|grep ntp
root 21223 1 0 Mar 10 ? 0:21 /usr/lib/inet/xntpd
# grep slewalways /etc/inet/ntp.conf
slewalways yes
To start the NTP service issue,
# /usr/sbin/svcadm enable ntp
3) HP-UX:
To verify the service issue,
# ps -ef|grep ntp
root 6022 1 0 14:23:42 ? 0:01 /usr/sbin/xntpd -x
# grep XNTPD_ARGS /etc/rc.config.d/netdaemons
export XNTPD_ARGS="-x"
To start the service issue,
# /sbin/init.d/xntpd start
4) AIX:
To verify the service issue,
# /usr/bin/lssrc -ls xntpd
xntpd tcpip 368754 active
# ps -ef|grep ntp
root 786614 151686 0 08:02:32 - 0:00 /usr/sbin/xntpd -x
# grep xntpd /etc/rc.tcpip
start /usr/sbin/xntpd "$src_running" -a "-x"
To start the service issue,
# /usr/bin/startsrc -s xntpd -a "-x"
http://hi.baidu.com/javenzhen/blog/item/48ef842edda797221e308938.htm
http://www.dbasky.net/archives/2009/01/linuxntp.html
Linux 时间同步配置
一. 使用ntpdate 命令
1.1 服务器可链接外网时
# crontab -e
加入一行:
*/1 * * * * ntpdate 210.72.145.44
210.72.145.44 为中国国家授时中心服务器地址,这样该机每隔1分重就可以与国家授时中心进行同步了。
注意: 在使用ntpdate 命令时, ntpd 服务必须是关闭的, 否则会报the NTP socket is in use, exiting 错误。
关闭 ntpd 服务命令如下:
[root@node2 init.d]# /etc/init.d/ntpd stop
Shutting down ntpd: [ OK ]
1.2. 架设本地时间服务器
需要修改 /etc/ntp.conf文件里的几个配置就可以了,比如本地时间服务器IP 为 10.85.10.119, 配置如下:
server 210.72.145.44 prefer (中国国家授时中心服务器地址 prefer表示优先 注意把默认的server更改成这样)
server 127.127.1.0 (本地时间)
restrict 10.85.10.0 mask 255.255.255.0 nomodify (允许10..85.10.* 的IP 使用该时间服务器)
restrict 0.0.0.0 mask 0.0.0.0 nomodify notrap noquery notrust (屏蔽其他IP过来更新时间)
其他的保持默认不动。
使NTP服务可以在系统引导的时候自动启动,执行:
# chkconfig ntpd on
启动/关闭/重启NTP的命令:
# /etc/init.d/ntpd start
# /etc/init.d/ntpd stop
# /etc/init.d/ntpd restart
#service ntpd restart
将同步好的时间写到CMOS里
vi /etc/sysconfig/ntpd
SYNC_HWCLOCK=yes
每次修改了配置文件后都需要重新启动服务来使配置生效。
可以使用下面的命令来检查NTP服务是否启动,你应该可以得到一个进程ID号:
# pgrep ntpd
使用下面的命令检查时间服务器同步的状态:
# ntpq -p
用ntpstat 也可以查看一些同步状态,用netstat -ntlup查看端口使用情况!
安装完毕客户端需过5-10分钟才能从服务器端更新时间!
客户端设置:
# crontab -e
加入一行:
*/1 * * * * ntpdate 10.85.10.119。
相关配置参数说明
# restrict权限控制语法为:
# restrict IP mask netmask_IP parameter
# 其中 IP 可以是软件地址,也可以是 default ,default 就类似 0.0.0.0 咯!
# 至于 paramter 则有:
# ignore :关闭所有的 NTP 联机服务
# nomodify:表示 Client 端不能更改 Server 端的时间参数,不过,
# Client 端仍然可以透过 Server 端来进行网络校时。
# notrust :该 Client 除非通过认证,否则该 Client 来源将被视为不信任网域
# noquery :不提供 Client 端的时间查询
# 如果 paramter 完全没有设定,那就表示该 IP (或网域) 『没有任何限制!』
# 设定上层主机主要以 server这个参数来设定,语法为:
# server [IP|FQDN] [prefer]
# Server 后面接的就是我们上层 Time Server 啰!而如果 Server 参数
# 后面加上 perfer 的话,那表示我们的 NTP 主机主要以该部主机来作为
# 时间校正的对应。另外,为了解决更新时间封包的传送延迟动作,
二、使用rdate同步时间
如果要用vmware安装RAC,则各个几点间时间必须一致,可以以一个节点作为标准,其他节点与该节点进行时间同步。
假如有两个节点:
A: 10.85.10.119
B: 10.85.10.121
以A作为时间标准,B节点用A节点时间进行同步。
1、在A节点开放37端口
最简单,但也最不安全的方法是关闭防火墙:iptables -F
2. 在A节点启动时间服务
#chkconfig time on #在系统引导的时候自动启动
如果不启动该服务,则其他节点与该节点同步时间时会报错:Connect Refused
注意:要用root 用户
3、在B节点与A节点同步时间
rdate -s 10.85.10.119
可以在crontab 中做执行计划, 每分钟执行一次,这样保证时间的同步。
[root@node2 ~]# crontab -l
*/1 * * * * rdate -s 10.85.10.119
[root@node2 ~]#
关于crontab 的介绍参考blog:
Unix crontab 命令详解
http://blog.csdn.net/tianlesoftware/archive/2010/02/21/5315039.aspx
三. 使用 Network Time Protocol (NTP) 服务器
1. 假如公司网络里有一个时间服务器: 10.85.10.80, 此时只需要在每个结点上修改NTP 服务配置文件,让每个结点和时间服务器进行同步即可。
# vi /etc/ntp.conf
Server 10.85.10.80 prefer
Driftfile /var/lib/ntp/drift
Broadcastdelay 0.008
修改完后在重启一下 ntp 服务
#/etc/init.d/ntpd restart
2. 如果没有时间服务,则可以用RAC 2个结点中一个做为服务器。另一个与此服务器同步即可。
加入用node1 做服务器, 其IP 为: 10.85.10.119, 修改配置文件
#vi /etc/ntp.conf
Server 127.127.1.0 -- 本地时钟
Fudge 127.127.1.0 stratum 11
Broadcastdelay 0.008
Node2 与node1 同步。 修改node2的ntp 配置文件
# vi /etc/ntp.conf
Server 10.85.10.119 prefer
Driftfile /var/lib/ntp/drift
Broadcastdelay 0.008
修改完后在重启一下 ntp 服务
#/etc/init.d/ntpd restart
http://www.diybl.com/course/7_databases/oracle/oraclejs/20110923/560905.html
http://rocolex.blog.163.com/blog/static/68446410201082184625277/
所有节点的时间必须同步,这通常是通过配置NTP服务器实现的。如果用户的网络中已经有一台时间服务器,那么可以所有节点都指向它,否则可以从集群中挑选一个节点作为时间服务器,让其他节点与它同步。下面分别演示这两种方法:
(1)如果公司网络中已经有一台时间服务器
如:192.168.11.10是一台ntp时间服务器
此时NTP服务器的配置文件是/etc/ntp.conf,在每个节点编辑这个文件。
[root@cc-svr-a ~]# vi /etc/ntp.conf
编辑后的内容如下,首选公司的时间服务器。
server 192.168.11.10 prefer
driftfile /var/lib/ntp/drift
broadcastdelay 0.008
(2)如果没有外部时间服务器
这时公司选择集群中某个节点作为时间服务器,NTP服务只需要很少的系统资源。假设选择主节点作为时间服务器,从节点向它同步,其配置方法如下。
编辑主节点的/etc/ntp.conf文件,编辑后的内容如下:
server 127.127.1.0
fudge 127.127.1.0 stratum 11
driftfile /var/lib/ntp/drift
broadcastdelay 0.008
编辑从节点的/etc/ntp.conf文件,编辑后的内容如下:
server 192.168.11.12 prefer #注意192.168.11.12为主节点的IP地址
driftfile /var/lib/ntp/drift
broadcastdelay 0.008
配置完成后,启动NTP服务。
[root@cc-svr-a ~]# /etc/init.d/ntpd start
[root@cc-svr-a ~]# chkconfig –level 345 ntpd on
(3)查看执行情况(主从)
[root@cc-svr-a ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*CC-Node-02 LOCAL(0) 12 u 58 64 17 0.226 -22.698 29.261
创建ASM磁盘组时报错:
Marking disk "ASM1" as an ASM disk: [FAILED]
连着几次失败.不解.
http://xin23.blog.51cto.com/1827266/515388
http://oracle.chinaitlab.com/install/766590.html
后无意中查看参数
[root@RAC-1 /]# /etc/init.d/oracleasm status
Checking if ASM is loaded: no
Checking if /dev/oracleasm is mounted: no
[root@RAC-1 /]# /etc/init.d/oracleasm enable
Writing Oracle ASM library driver configuration: done
Initializing the Oracle ASMLib driver: [ OK ]
Scanning the system for Oracle ASMLib disks: [ OK ]
[root@RAC-1 /]# /etc/init.d/oracleasm createdisk ASM1 /dev/sde1
Marking disk "ASM1" as an ASM disk: [ OK ]
[root@RAC-1 /]# /etc/init.d/oracleasm createdisk ASM3 /dev/sde3
Marking disk "ASM3" as an ASM disk: [ OK ]
[root@RAC-1 /]#
Oracle CRS简介
从Oracle 10gR1 RAC 开始,Oracle推出了自身的集群软件,这个软件的名称叫做Oracle Cluster Ready Service(Oracle集群就绪服务),简称CRS。从Oracle 10gR2开始,包括最新的11g,Oracle将其更名为Clusterware(集群件),但通常意义上我们认为CRS = Clusterware = Oracle Cluster Ready Service = Oracle Cluster Software.
CRS一般用来搭建Oracle的并行数据库,即RAC,但除了与RAC的接口之外,CRS还提供了一组高可用性的应用程序接口(API),用来搭建一般应用程序的高可用集群,即一般我们常说的双机热备,比如使用CRS实现MySQL的双机热备。
Oracle10g New Feature:CRS(Cluster Ready Services)
作者:eygle |English Version 【转载时请以超链接形式标明文章出处和作者信息及本声明】
链接:http://www.eygle.com/archives/2005/10/oracle10g_new_feature_crs.html
Oracle10g CRS(Cluster Ready Services)是Oracle10g RAC的一个新特性,用以提供标准的群集服务接口。
在以前的版本中,Oracle RAC必须借助第三方Cluster软件,但是从Oracle10g开始,我们有了新的选择。
CRS就是这样一个替代产品,用以提供RAC环境中的群集服务。
CRS是一个单独的产品,在构建RAC环境中,需要单独安装。
(在Oracle刚推出CRS时,Oracle还没发明ClusterWare这个词。
所以最初的CRS就是指现在的Clusterware,如果你注意过的话最初Oracle的安装盘上装Clusterware的时候,都说的是CRS。
所以提到Cluster Ready Services,大家都知道指的是Oracle的Clusterware而不是crs daemon.
只不过从10gR2开始,ClusterWare被引入,CRS这个词的含义被Oracle偷偷的缩小了。)
系统启动以后,CRS会自动启动,启动主要由/etc/init.d中的几个脚本完成:
[eygle@raclinux1 init.d]$ ll init*-r-xr-xr-x 1 root root 1951 Jun 27 13:27 init.crs-r-xr-xr-x 1 root root 4735 Jun 27 20:32 init.crsd-r-xr-xr-x 1 root root 35401 Jun 27 13:27 init.cssd-r-xr-xr-x 1 root root 3197 Jun 27 13:27 init.evmd
CRS启动的三个主要的后台进程为:
[oracle@raclinux1 bin]$ ps -ef|grep d.binroot 3140 1 0 23:13 00:00:00 /u01/app/oracle/product/10.2.0/crs/bin/crsd.binoracle 3884 3062 0 23:14 00:00:00 /u01/app/oracle/product/10.2.0/crs/bin/evmd.binoracle 4017 3983 0 23:14 00:00:00 /u01/app/oracle/product/10.2.0/crs/bin/ocssd.binoracle 21117 13799 0 23:29 pts/1 00:00:00 grep d.bin
这几个进程的主要作用如下:
CRSD:- Engine for HA operation - Manages 'application resources'- Starts, stops, and fails 'application resources' over- Spawns separate 'actions' to start/stop/check application resources- Maintains configuration profiles in the OCR (Oracle Configuration Repository)- Stores current known state in the OCR.- Runs as root- Is restarted automatically on failureOCSSD:- OCSSD is part of RAC and Single Instance with ASM- Provides access to node membership- Provides group services- Provides basic cluster locking- Integrates with existing vendor clusteware, when present- Can also runs without integration to vendor clustware- Runs as Oracle.- Failure exit causes machine reboot. --- This is a feature to prevent data corruption in event of a split brain.
注意,ocssd进程在单实例ASM系统中也可以见到,以下是我的一个单实例ASM系统,ocssd进程同样存在:
bash-2.03# ps -ef|grep _+ASM oracle 3264 1 0 Aug 25 ? 0:01 asm_lgwr_+ASM root 12669 8167 0 11:58:56 pts/1 0:00 grep _+ASM oracle 3270 1 0 Aug 25 ? 0:00 asm_rbal_+ASM oracle 3266 1 0 Aug 25 ? 0:05 asm_ckpt_+ASM oracle 3268 1 0 Aug 25 ? 0:00 asm_smon_+ASM oracle 3262 1 0 Aug 25 ? 0:00 asm_dbw0_+ASM oracle 3258 1 0 Aug 25 ? 0:00 asm_pmon_+ASM oracle 3260 1 0 Aug 25 ? 0:00 asm_mman_+ASMbash-2.03# ps -ef|grep ocssd root 12672 8167 0 11:59:01 pts/1 0:00 grep ocssd oracle 5374 1 0 Apr 07 ? 0:01 /opt/oracle/product/10.1.0/bin/ocssd.binbash-2.03#
ocssd进程非常重要,如果该进程异常中止,会导致系统crash。
在某些极端情况下,如果ocssd无法正常启动,会导致操作系统循环重启。这时候需要DBA介入进行一些特殊处理。(解决循环重启的问题是修改/etc/init.d/init.cssd文件,注释掉其中FAST_REBOOT语句)
EVMD:- Generates events when things happen- Spawns a permanent child evmlogger- Evmlogger, on demand, spawns children- Scans callout directory and invokes callouts.- Runs as Oracle.- Restarted automatically on failure
[oracle@raclinux1 ~]$ cd $ORA_CRS_HOME/bin[oracle@raclinux1 bin]$ pwd/u01/app/oracle/product/10.2.0/crs/bin[oracle@raclinux1 bin]$ ./crs_statNAME=ora.RACDB.RACDB1.instTYPE=applicationTARGET=ONLINESTATE=ON LINE on raclinux1NAME=ora.RACDB.RACDB2.instTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.RACDB.dbTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.ASM1.asmTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.LISTENER2_RACLINUX1.lsnrTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.LISTENER_RACLINUX1.lsnrTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.gsdTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.on sTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1NAME=ora.raclinux1.vipTYPE=applicationTARGET=ON LINESTATE=ON LINE on raclinux1[oracle@raclinux1 bin]$
1) Linux:
To verify service as root user issue,
# /sbin/service ntpd status
ntpd (pid 4423) is running...
Check process is running or not by.
# ps -ef|grep ntp
ntp 4209 1 0 Mar10 ? 00:00:00 ntpd -u ntp:ntp -p /var/run/ntpd.pid -x
# grep OPTIONS /etc/sysconfig/ntpd
OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -x"
If NTP service is not started then to start the service issue,
To start the service issue,
# /sbin/service ntpd start
2) Solaris:
To verify the service issue,
# /usr/bin/svcs ntp
STATE STIME FMRI
online 3:29:11 svc:/network/ntp:default
# ps -ef|grep ntp
root 21223 1 0 Mar 10 ? 0:21 /usr/lib/inet/xntpd
# grep slewalways /etc/inet/ntp.conf
slewalways yes
To start the NTP service issue,
# /usr/sbin/svcadm enable ntp
3) HP-UX:
To verify the service issue,
# ps -ef|grep ntp
root 6022 1 0 14:23:42 ? 0:01 /usr/sbin/xntpd -x
# grep XNTPD_ARGS /etc/rc.config.d/netdaemons
export XNTPD_ARGS="-x"
To start the service issue,
# /sbin/init.d/xntpd start
4) AIX:
To verify the service issue,
# /usr/bin/lssrc -ls xntpd
xntpd tcpip 368754 active
# ps -ef|grep ntp
root 786614 151686 0 08:02:32 - 0:00 /usr/sbin/xntpd -x
# grep xntpd /etc/rc.tcpip
start /usr/sbin/xntpd "$src_running" -a "-x"
To start the service issue,
# /usr/bin/startsrc -s xntpd -a "-x"
http://hi.baidu.com/javenzhen/blog/item/48ef842edda797221e308938.htm
http://www.dbasky.net/archives/2009/01/linuxntp.html
Linux 时间同步配置
一. 使用ntpdate 命令
1.1 服务器可链接外网时
# crontab -e
加入一行:
*/1 * * * * ntpdate 210.72.145.44
210.72.145.44 为中国国家授时中心服务器地址,这样该机每隔1分重就可以与国家授时中心进行同步了。
注意: 在使用ntpdate 命令时, ntpd 服务必须是关闭的, 否则会报the NTP socket is in use, exiting 错误。
关闭 ntpd 服务命令如下:
[root@node2 init.d]# /etc/init.d/ntpd stop
Shutting down ntpd: [ OK ]
1.2. 架设本地时间服务器
需要修改 /etc/ntp.conf文件里的几个配置就可以了,比如本地时间服务器IP 为 10.85.10.119, 配置如下:
server 210.72.145.44 prefer (中国国家授时中心服务器地址 prefer表示优先 注意把默认的server更改成这样)
server 127.127.1.0 (本地时间)
restrict 10.85.10.0 mask 255.255.255.0 nomodify (允许10..85.10.* 的IP 使用该时间服务器)
restrict 0.0.0.0 mask 0.0.0.0 nomodify notrap noquery notrust (屏蔽其他IP过来更新时间)
其他的保持默认不动。
使NTP服务可以在系统引导的时候自动启动,执行:
# chkconfig ntpd on
启动/关闭/重启NTP的命令:
# /etc/init.d/ntpd start
# /etc/init.d/ntpd stop
# /etc/init.d/ntpd restart
#service ntpd restart
将同步好的时间写到CMOS里
vi /etc/sysconfig/ntpd
SYNC_HWCLOCK=yes
每次修改了配置文件后都需要重新启动服务来使配置生效。
可以使用下面的命令来检查NTP服务是否启动,你应该可以得到一个进程ID号:
# pgrep ntpd
使用下面的命令检查时间服务器同步的状态:
# ntpq -p
用ntpstat 也可以查看一些同步状态,用netstat -ntlup查看端口使用情况!
安装完毕客户端需过5-10分钟才能从服务器端更新时间!
客户端设置:
# crontab -e
加入一行:
*/1 * * * * ntpdate 10.85.10.119。
相关配置参数说明
# restrict权限控制语法为:
# restrict IP mask netmask_IP parameter
# 其中 IP 可以是软件地址,也可以是 default ,default 就类似 0.0.0.0 咯!
# 至于 paramter 则有:
# ignore :关闭所有的 NTP 联机服务
# nomodify:表示 Client 端不能更改 Server 端的时间参数,不过,
# Client 端仍然可以透过 Server 端来进行网络校时。
# notrust :该 Client 除非通过认证,否则该 Client 来源将被视为不信任网域
# noquery :不提供 Client 端的时间查询
# 如果 paramter 完全没有设定,那就表示该 IP (或网域) 『没有任何限制!』
# 设定上层主机主要以 server这个参数来设定,语法为:
# server [IP|FQDN] [prefer]
# Server 后面接的就是我们上层 Time Server 啰!而如果 Server 参数
# 后面加上 perfer 的话,那表示我们的 NTP 主机主要以该部主机来作为
# 时间校正的对应。另外,为了解决更新时间封包的传送延迟动作,
二、使用rdate同步时间
如果要用vmware安装RAC,则各个几点间时间必须一致,可以以一个节点作为标准,其他节点与该节点进行时间同步。
假如有两个节点:
A: 10.85.10.119
B: 10.85.10.121
以A作为时间标准,B节点用A节点时间进行同步。
1、在A节点开放37端口
最简单,但也最不安全的方法是关闭防火墙:iptables -F
2. 在A节点启动时间服务
#chkconfig time on #在系统引导的时候自动启动
如果不启动该服务,则其他节点与该节点同步时间时会报错:Connect Refused
注意:要用root 用户
3、在B节点与A节点同步时间
rdate -s 10.85.10.119
可以在crontab 中做执行计划, 每分钟执行一次,这样保证时间的同步。
[root@node2 ~]# crontab -l
*/1 * * * * rdate -s 10.85.10.119
[root@node2 ~]#
关于crontab 的介绍参考blog:
Unix crontab 命令详解
http://blog.csdn.net/tianlesoftware/archive/2010/02/21/5315039.aspx
三. 使用 Network Time Protocol (NTP) 服务器
1. 假如公司网络里有一个时间服务器: 10.85.10.80, 此时只需要在每个结点上修改NTP 服务配置文件,让每个结点和时间服务器进行同步即可。
# vi /etc/ntp.conf
Server 10.85.10.80 prefer
Driftfile /var/lib/ntp/drift
Broadcastdelay 0.008
修改完后在重启一下 ntp 服务
#/etc/init.d/ntpd restart
2. 如果没有时间服务,则可以用RAC 2个结点中一个做为服务器。另一个与此服务器同步即可。
加入用node1 做服务器, 其IP 为: 10.85.10.119, 修改配置文件
#vi /etc/ntp.conf
Server 127.127.1.0 -- 本地时钟
Fudge 127.127.1.0 stratum 11
Broadcastdelay 0.008
Node2 与node1 同步。 修改node2的ntp 配置文件
# vi /etc/ntp.conf
Server 10.85.10.119 prefer
Driftfile /var/lib/ntp/drift
Broadcastdelay 0.008
修改完后在重启一下 ntp 服务
#/etc/init.d/ntpd restart
http://www.diybl.com/course/7_databases/oracle/oraclejs/20110923/560905.html
http://rocolex.blog.163.com/blog/static/68446410201082184625277/
Network Time Protocol(NTP,网络时间协议)用于同步它所有客户端时钟的服务。NTP服务器将本地系统的时钟与一个公共的NTP服务器同步然后作为时间主机提供服务,使本地网络的所有客户端能同步时钟。
同步时钟最大的好处就是相关系统上日志文件中的数据,如果网络中使用中央日志主机集中管理日志,得到的日志结果就更能反映真实情况。在同步了时钟的网络中,集中式的性能监控、服务监控系统能实时的反应系统信息,系统管理员可以快速的检测和解决系统错误。
安装配置NTP服务
下面将介绍NTP服务器的简单配置:
第一步,安装NTP服务
一般的Linux发行版都会带ntp软件包,如果你的系统中还没有安装,就使用rpm命令安装此包
,以下以centos系统为例配置一台时间服务器:
查找当前系统是否已安装ntp
[root@localhost ~]# rpm -qa | grep ntp
chkfontpath-1.10.1-1.1
ntp-4.2.2p1-8.el5.centos.1 (这个就是已经安装的RPM包)
如果没有安装,可用下例命令安装:
[root@localhost ~]# rpm -ivh ntp-4.2.2p1-8.el5.centos.1.rpm
第二步,配置NTP服务器
NTP服务器配置如下:
编辑配置文件/etc/ntp.conf
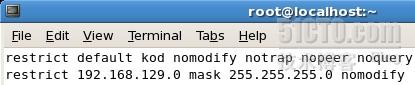
restrict default kod nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
restrict 127.0.0.1
restrict -6 ::1
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
server 192.168.146.225
server 0.centos.pool.ntp.org
server 1.centos.pool.ntp.org
server 2.centos.pool.ntp.org
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
配置文件说明如下:
第一行restrict、default定义默认访问规则,nomodify禁止远程主机修改本地服务器配置,notrap拒绝特殊的ntpdq捕获消息,noquery拒绝btodq/ntpdc查询(这里的查询是服务器本身状态查询)。
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
这句是手动增加的,意思是从192.168.1.1-192.168.1.254的服务器都可以使用我们的NTP服务器来同步时间。
server 192.168.146.225
这句也是手动增加的,指明局域网中作为NTP服务器的IP;
配置文件的最后两行作用是当服务器与公用的时间服务器失去联系时以本地时间为客户端提供时间服务。
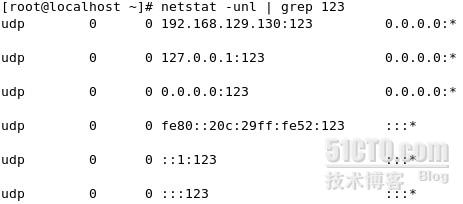
端口
ntp使用udp协议,记得开放其123端口。
启动NTPD
为了使NTP服务可以在系统引导的时候自动启动,执行:
#chkconfig ntpd on
启动ntpd:
service ntpd start
NTP客户端配置:
在客户端手动执行“ntpdate 服务器IP”来同步时间;
另可以使用crond来定时同步时间:
以root身份运行周期性任务:
[root@supersun root]# crontab -e
添加以下内容,每15分钟更新一下时间:
15 * * * * ntpdate 服务器IP
此处的ntpdate命令包含在ntp软件包中,记得确认系统中是否已安装。
第三步,检查时间服务器是否正确同步
使用下面的命令检查时间服务器同步的状态:
#ntpq -p
一个可以证明同步有问题的证据是:所有远程服务器的jitter值是4000并且delay和reach的值是0。
可能的原因有:
有防火墙阻断了与server之间的通讯,即123端口是否正常开放;
此外每次重启NTP服务器之后大约要3-5分钟客户端才能与server建立正常的通讯连接,否则你在客户端执行“ntpdate 服务器ip”的时候将返回:
27 Jun 10:20:17 ntpdate[21920]: no server suitable for synchronization found
NTP服务器的配置
2008-01-31 09:51:10
http://blog.csdn.net/clliugw/article/details/5314215



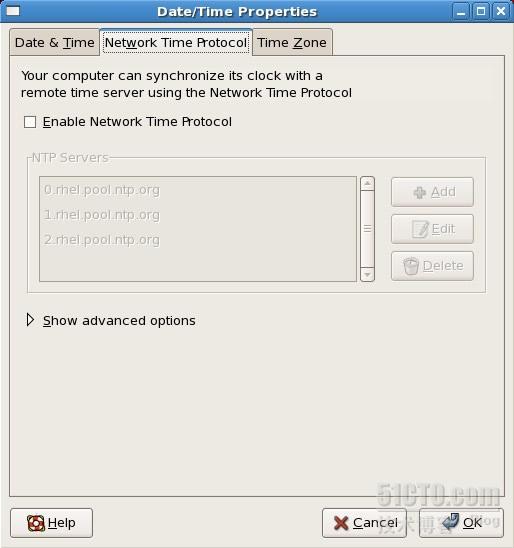
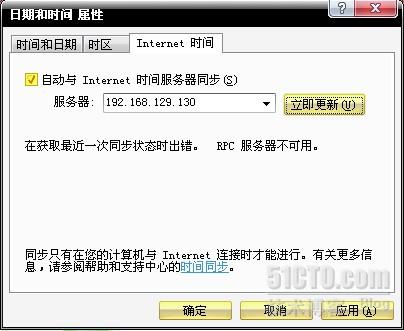
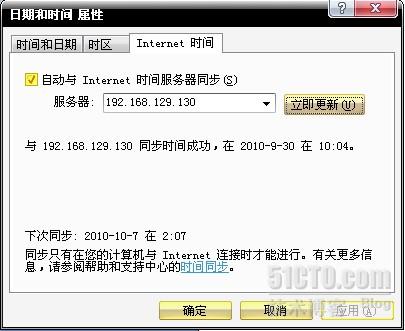
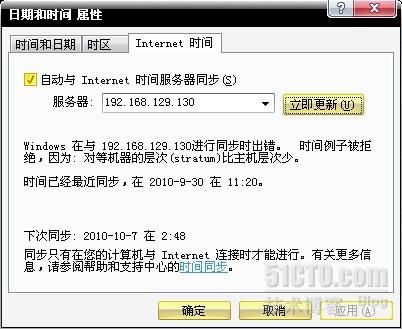
在Network Time Protocol选项卡中把Enable Network Time Protocol前面的勾去掉





u 设置同步









- Oracle ASM 详解
- ORACLE ASM详解
- Oracle ASM 详解
- Oracle ASM 详解
- Oracle ASM 详解 收藏
- Oracle ASM 详解
- Oracle ASM 详解
- Oracle ASM 详解
- Oracle ASM 详解
- 90、Oracle ASM 详解
- ORACLE ASM详解
- Oracle ASM 详解
- Oracle ASM 详解
- Oracle ASM 详解
- Oracle ASM 详解
- Oracle ASM 详解
- Oracle ASM 详解
- Oracle ASM 详解
- c/c++软件开发的注意事项
- Java中堆和栈的区别
- 理论+实践来认识/dev/shm(共享内存目录)
- 二叉树的递归创建&遍历
- java break,continue,return 使用。【借鉴与改编】
- Oracle ASM 详解
- explicit关键字的作用
- 简单实现后台订单页面 上一单,下一单 的按钮
- Javascript之BOM详解
- Android之 MediaPlayer播放一般音频与SoundPool播放短促的音效
- Oracle Database 11g Release 2 RAC On Linux Using VMware Server 2
- hash 函数构造方法
- zencart建站优化必须的十款插件
- Ant


