笔试面试中C/C++重要知识点整理(不定期更新)
来源:互联网 发布:8月份上海房产成交数据 编辑:程序博客网 时间:2024/05/01 00:54
1. C和C++语言中的优先级规则
C语言中语言声明的优先级规则如下(以后分析的基础):
A 声明从它的第一个名字开始读取,然后按照优先级顺序依次读取
B 优先级从高到低依次是
B. 1 声明中被括号括起来的那部分
B. 2 后缀操作符:
括号()表示这是一个函数
方括号[]表示这是一个数组
B. 3 前缀操作符:星号*表示“指向……的指针”
下面我们使用上述规则来分析以下例子
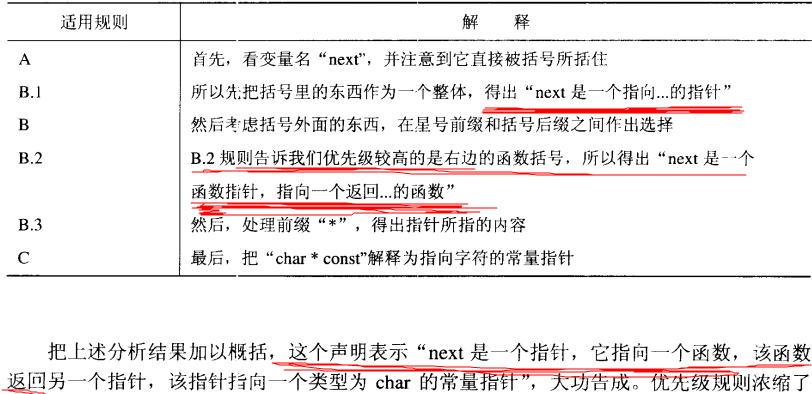
(1) char * const *(*next)();
(2) char* (*c[10])(int **p)
一步步分析:先分析括号里面的内容,我们知道C是一个数组,保存的是“…..的指针”然后根据规则B,要先分析后缀,得到指针是一个函数指针。该函数参数为P返回值为char*。最后得到:C是一个数组元素,它的元素类型是函数指针,其所指向的函数的返回值是一个指向char的指针。
(3) void(*signal(int sig,void(*func)(int)))(int);
从signal所在的括号开始提取:void(*signal( ) )(int); 首先signal后缀跟的是括号,我们得到signal是一个函数, 然后得到前缀为* 表示此函数返回的是一个”……指针”…………最后得到signal是一个函数,返回函数指针,函数所指向的指针接受一个int类型的参数并且返回void。
然后我们看signal函数参数本身: void(*func)(int) 表示func是一个函数指针,此指针指向的函数接收一个int参数,返回值是void。
如果我们定义typedef void(*ptr_to_func)(int)则表示 ptr_to_func是一个函数指针,该函数接受一个int参数,返回值为void 那么上述函数可以写为
ptr_to_funcsignal(int sig, ptr_to_func); 表示 signal 是一个函数 ,接收参数为int和 ptr_to_func,返回ptr_to_func ;
2. typedef int x[10]与 #define x int[10]的区别
typedef与宏文本替换之间存在关键性的区别。如下:
第一: 可以用其他类型说明符对宏名进行扩展,但对typedef所定义的类型名却不能这样做。 如下:
#define peach int
unsigned peach i ; // 可以
typedef int banana;
unsigned banana i ; // 错误
第二:在连续声明的变量中用typedef定义的类型能够保证声明中所有变量均同一种类型,而用#define定义的类型却无法保证。 如下:
#define int_ptr int*
int_ptr chalk, cheese;
经过宏扩展,第二行变为:
int *chalk, cheese; 这使得chalk 与cheese为不同的类型。chalk为int类型的指针,而cheese只是int类型变量。
typedef char * char_ptr;
char_ptr Benley, Royce ; Benley,和Royce类型是相同的。都是指向char的指针
原因: #define在编译时仅仅是名称替换而typedef可以被看成一个彻底封装的“类型”。在了解typedef 中变量具体表达什么意思的时候可以按照前面说的优先级规则进行解析。
3. 指针与typedef
typedef中使用指针往往带来意外的结果。例:
typedef string *pstring;
const pstring cstr;
c_str究竟代表什么类型。我们知道pstring是指向string的指针很多人都会误认为真正的类型是const string* cstr。错误原因是将typedef当成#define 直接进行文本扩展了,其实const修饰的是 pstring 而pstring是一个指针,因此,正确的等价形式应该是
string *const cstr;
4. 类与面向对象编程
4.1 类接口与实现的概念:
每个类都定义了一个接口(可以不是很确切的理解为类中访问级别为public的函数为接口)和一个实现。接口由使用该类的代码需要执行的操作组成。实现一般包括该类所需要的数据。实现还包括定义该类需要的但又不供一般性使用的函数。
定义类时,通常先要定义该类的接口,即该类所提供的操作。通过这些操作,可以决定该类完成其功能所需要的数据,以及是否需要定义一些函数来支持该类的实现。
public派生类继承基类的接口,它具有与基类相同的接口。设计良好的类层次中,public派生类的对象可以用在任何需要基类对象的地方。
4.2 用struct关键字与class关键定义类以及继承的区别
(1)定义类差别
struct关键字也可以实现类,用class和struct关键字定义类的唯一差别在于默认访问级别:默认情况下,struct成员的访问级别为public,而class成员的为private。语法使用也相同,直接将class改为struct即可。
(2)继承差别
使用class保留字的派生类默认具有private继承,而用struct保留字定义的类某人具有public继承。其它则没有任何区别。
class Base{ /*....*/};
struct D1: Base{ /*......*/} ; // 默认是public继承
class D2: Base{/*.......*/}; // 默认是private继承
4.3 类设计与protected成员
可以认为protected访问标号是private和public的混合:
(1)像private成员一样,protected成员不能被类的用户访问
(2)像public成员一样,protected成员可以被该类的派生类访问。
例如:
class Base
{
.........
protected:
int price;
};
class Item_Base :public Base
{
......................
};
Base b;
Item_Base d;
b.price; // error
d.price: // OK
小结(帮助理解为什么设置protected类型): 如果没有继承,类只有两种用户:类本身的成员以及该类的用户,将类划分为private和public访问级别反映了用户类型的这一分割:用户只能访问public接口,类成员和友元既能访问public成员也能访问private成员。
有了继承,就有了第三种用户:从派生类定义新类的程序员。派生类提供者通常(但不总是)需要访问(类型为private的)基类实现(见4.1实现概念)。为了允许这种访问而仍然禁止对实现的一般访问。所以提供了附加的protected访问标号。类的protected部分仍然不能被一般程序访问,但可以被派生类访问。
定义基类时,将成员设置为public的标准并没有改变:仍然是接口函数应该为public而数据一般不应为public。被继承的类必须决定实现那些部分为protected哪些部分为private。希望禁止派生类访问的成员应该设为private,提供派生类实现所需操作或数据的成员设为protected。换句话说,提供给派生类的接口是protected成员和public成员的组合。
4.4 派生类与虚函数概述
(1)定义为virtual的函数是希望派生类重新定义。希望派生类继承的函数不能定义为虚函数。如果派生类没有重新定义某个虚函数,则在调用的时候会使用基类中定义的版本。
(2)派生类中函数的声明必须与基类中定义的方式完全匹配,但有一个例外:返回对基类类型的引用(或指针)的虚函数。派生类中的虚函数可以返回基类函数所返回类型的派生类的引用(或指针)。比如:Item_base类可以定义返回Item_base*的函数。如果这样,派生类Bulk_item类中定义的实例可以定义返回为Item_base*或者Bulk_item*
(3) 一旦函数在基类中声明为虚函数,它就一直为虚函数,派生类无法改变该函数为虚函数这一事实。派生类重新定义虚函数时,可以使用virtual保留字,也可以省略。
4.5 virtual 函数详解(待更新)
要触发动态绑定,必须满足两个条件:第一:只有指定为虚函数的成员函数才能进行动态绑定。第二,必须通过基类类型的引用或者指针进行函数调用。下面重点讲下第二个条件。
由于每个派生类都包含基类部分,所以可将基类对象引用或者指针绑定到派生类对象的基类部分(派生类对象本身不会改变)。如下:
double print_total(const Item_base&, size_t);
Item_base item;
print_total(item, 10); // OK
Bulk_item bulk;
print_total(bulk, 10); // OK 引用bulk中Item_base的部分。
Item_base *item = &bulk; // OK , 指针指向bulk 的Item_base部分。
通过引用或者指针调用虚函数时,编译器将生成代码,在运行时确定调用哪个函数。比如:
假定print_total 为虚函数,在基类Item_base 和派生类Bulk_item中都有定义。
函数原型:void print_total(ostream& os, const Item_base &item, size_t n);
Item_base base;
Bulk_item derived;
print_total(count, base, 10); // 将调用基类Item_base中的print_total函数
print_total(count, derivede,10); // 将调用派生类中的print_total 函数。
在某些情况下,希望覆盖虚函数的机制并强制函数使用虚函数的特定版本,这时可以使用作用域操作符。
Item_base *baseP = &derived;
double d = baseP->Item_base::net_price(42);
这段代码将强制把net_price调用确定为Item_base中版本(在编译时确定)。
小结:引用和指针的静态类型与动态类型可以不同,这是C++支持多态性的基石。当通过基类引用或者指针滴哦啊用基类中定义的函数时,我们并不知道执行函数的对象的确切类型,执行函数的对象可能是基类类型的,也可能是派生类类型的。
如果调用非虚函数,则无论实际对象是什么类型,都执行基类中所定义的哦函数。如果调用虚函数,则直到运行时才能确定调用哪个函数。
4.5 派生类到基类的转换 : C++ primer 488 没有想好怎么整理
4.6 基类与派生类中构造函数和复制控制:
构造函数和复制控制成员不能被继承,每个类定义自己的构造函数和复制控制成员,如果不定义,则编译器将合成一个。
继承对基类中构造函数的唯一影响是,某些类需要只希望派生类使用的特殊构造函数,这样的构造函数应该定义为protected。
4.6.1 派生类构造函数
派生类构造函数受继承关系的影响,每个派生类构造函数除了初始化自己的数据成员之外,还要初始化基类。对于合成的派生类默认构造函数,先调用基类的默认构造函数初始化(问题,如果基类没有定义默认构造函数咋整,要试验下) 再默认初始化自己的对象成员。。。。。
具体语法参见P491 c++ primer
4.6.2 派生类析构函数
派生类析构函数不负责撤销基类对象的成员。编译器总是显式调用派生类对象基类部分的析构函数。每个析构函数只负责清除自己的成员:
class Derived: public Base
{
// Base::~Base()函数会自动被调用
~Derived();
}
对象的撤销顺序与构造顺序相反:首先运行派生类析构函数,然后按照继承层次依次向上调用各基类的析构函数。
4.6.3 虚析构函数
当阐述指向动态分配对象的指针时,需要运行析构函数在释放对象之前清除对象。如果把析构函数设置为虚函数,运行哪个析构函数将因指针所指向对象类型的不同而不同:
Item_base *itemP = new Item_base;
delete itemP; // 基类的析构函数被调用
itemP = new Bulk_item;
delete itemP; // 派生类的析构函数被调用
如果不把析构函数定义为虚函数,则会一直调用基类的析构函数,从而引发程序异常。
像其他虚函数一样,析构函数的虚函数性质将继承,因此,如果层次中根类的析构函数为虚函数,则派生类析构函数也将是虚函数,无论派生类显式定义析构函数还是使用合成析构函数,派生类析构函数都是虚函数。
构造函数不是虚函数: 构造函数实在对象完全构造之前运行的,在构造函数运行的时候,对象的动态类型还不够完整(待理解),所以构造函数不是虚函数。
4.7 继承情况下的类的作用域
继承层次中函数调用遵循以下四个步骤:
(1)首先确定进行函数调用的对象,引用或者指针的静态类型。
(2)在该类中查找函数,如果找不到,就直接在基类中查找,如此循环着类的继承链往上找,直到找到该函数或者查找完最后一个类。如果不能再类或者相关基类中找到该名字,则调用是错误的。
(3)一旦找到了该名字,进行常规类型检查(参数类型检查等),查看该函数调用是否合法
(4) 假定函数调用合法,编译器就生成代码,如果函数是虚函数并且通过引用或者指针调用,则编译器生成代码以确定根据对象的动态类型运行哪个函数版本,否则,编译器生成代码直接调用函数。
举例1:
Bulk_item bulk;
cout << bulk.book();
book 的使用将这样确定:
(1) bulk 是Bulk_item 类对象,在Bulk类中查找,找不到名字book ( 根据上面第一步,确定静态类型为Bulk_item, 然后进入第二步)
(2)因为从Item_base派生Bulk_item, 所以接着在Item_base类中查找,找到book ,名字成功确定。
举例2:
struct Base
{
int menfcn();
};
struct Derived: Base
{
int menfcn(int);
};
Derived d; Base b;
b.memfcn(); // 调用基类的函数
d.menfcn(10); // 调用派生类函数
d.menfcn(); // 错误:
d.Base::menfcn(); // 调用基类函数
第三个调用中出现错误,原因是,Derived中的么么fcn声明隐藏了Base中的声明。 原因是,根据上面规则,一旦找到了名字,编译器就不会再继续查找了。而是进行常规检查,由于调用与Derived中的memfcn不匹配,该定义希望接受int实参,而这个函数调用没有提供那样的实参,所以错误
如果派生类重新定义了重载成员,则通过派生类行只能访问派生类中重新定义的那些成员。
举例3: 通过基类指针或者引用调用
假定print_total 为虚函数,在基类Item_base 和派生类Bulk_item中都有定义。
函数原型:void print_total(ostream& os, const Item_base &item, size_t n);
Item_base base;
Bulk_item derived;
print_total(count, base, 10); // 将调用基类Item_base中的print_total函数
print_total(count, derivede,10); // 将调用派生类中的print_total 函数。
如果print_total 不是虚函数,根据上面的步骤,将直接调用基类Item_base中的print_total 版本
由于print_total中 第二个参数的静态类型为Item_base 所以根据规则(1),先Item_base 中查找print_total , 然后进行常规检查,参数没有错,由于函数是虚函数之后根据规则(4), print_total(count, base, 10);用基类Item_base中的print_total函数,print_total(count, derivede,10);,调用派生类中的print_total 函数。
现在可以理解为什么虚函数在基类和派生类中拥有同一原型了,如果没有同一原型,比如基类与派生类中参数不同,根据规则3,确定基类中参数没有问题时,如果根据规则4 实际调用的是派生类中的函数时由于参数不同就会出现错误。
4.8 细节知识点
4.8.1 explicit关键字
我们可以将构造函数声明为explicit,来防止在需要隐式转换的上下文中使用构造函数。例如
class Sales_item
{
public:
Sales_item(const string &book = ""):isbn(book),units_sold(0){}
bool same_isbn(const Sales_item &rhs) const;
};
每个构造函数都定义了一个隐式转换。因此,在期待一个Sales_item类型对象的地方,可以使用一个string或者istream:如下
string null_book = "9-1111-1111";
item.same_isbn(null_book);
以上程序中,本来程序期待一个Sales_item对象作为实参,编译器使用接受一个string的Sales_item构造函数从null_book生成一个新的Sales_item对象,新生成的临时的Sales_item对象被传递给same_isbn。
如果我们不想要编译器隐式的转换,可以将构造函数声明为explicit。 注意的是explicit关键字只能用于类内部的构造函数声明上。在类定义外部所作的定义中不再重复它。 比如以下是错误的.
explicit Sales_item:: sales_item(istream& is) // 错误,explicit只在类内构造函数的声明上
{
。。。。。。
}
加上explicit关键字后,以下就不能编译通过
item.same_isbn(null_book); // error:string constructor is explicit
当然我们可以显式的使用构造函数来生成转换,如下
item.same_isbn(Sales_item(null_book)); // OK
总结:通常,除非有明显的理由需要隐式转换,否则,构造函数应该为explicit。 将构造函数设置为explicit可以避免错误,并且当转换有用时用户可以显式的构造对象
4. 9 虚函数与纯虚函数区别
(1)虚函数在子类里面也可以不重载的;但纯虚必须在子类去实现
(2)带纯虚函数的类叫虚基类,这种基类不能直接生成对象,而只有被继承,并重写其虚函数后,才能使用。这样的类也叫抽象类。虚函数是为了继承接口和默认行为
5. C++内存分配与释放浅析(以后会深入讲解更新)
我们一般以一下的形式对C++进行内存配置和释放。
class Foo{ };
Foo *pf = new Foo; // 配置内存,然后构造对象
delete pf; //将对象析构,然后释放对象
其中 new算式内含两个阶段操作 :
(1)调用::operator new操作符配置内存
(2)调用Foo::Foo()构造对象内容
delete算式也包含两个阶段操作:
(1)调用Foo::~Foo()将对象析构
(2)调用::operator delete释放内存
如果我们想要创建对象的时候初始化可以用如下形式:
string *ps = new string("Hello"); // *ps is "Hello"
与malloc和free的区别
(1)new/delete调用 constructor/destructor.Malloc/free 不会
(2)new 不需要类型强制转换。.Malloc 要对放回的指针强制类型转换.
(3)new/delete操作符可以被重载, malloc/free 不会
(4)new 并不会强制要求你计算所需要的内存 ( 不像malloc)
6. C语言数组与字符串
1. 数组的定义与初始化
在数组定义时,如果没有显式提供元素初值,则数组元素会像普通变量一样初始化:
在函数体外定义的内置数组,其元素均初始化为0;
在函数体内定义的内置数组,其元素无初始化
不管数组在哪里定义,如果元素为类类型,则自动调用该类的默认构造函数进行初始化;如果该类没有默认构造函数,则必须为该数组的元素提供显式初始化.
2. 特殊的字符数组
字符数组有两种初始化方式
(1) 用一组由花括号括起来、逗号隔开的字符字面值进行初始化。
(2) 用一个字符串字面值进行初始化。
两种初始化形式有所不同。第(2)种初始化方式包含一个额外的空字符(null)用于结束字符串。举例如下:
char ca1[ ] = {‘C’, ‘+’, ‘+’}; // no null
char ca2[ ] = {‘C’, ‘+’, ‘+’, ‘\0’}; // explicit null(也可以写为{‘C’, ’+’, ‘+’, 0 })
char ca3[ ] = “C++”; // null added automatically
上例中ca1的维数为3, ca2和ca3的维数为4
注: strlen计算字符串的大小时从字符串开头直到遇到null为止,在计算strlen(ca1)时结果是未知的。原因是不知道何时会遇到null 而strlen(ca2)与strlen(ca3)的结果都将是3
3. string s(n, ‘c’) // 将s4初始化为字符 ’c’的n个副本
vector<T> v(n, i); // v 包含n个值为i的元素
vector和string中计算大小建议使用size_type类型,因为它与机器无关,不建议使用int类型。
4. vector类型的值初始化
vector中如果没有指定元素的初始化式,那么标准库将自行提供一个元素初始值进行值初始化。例如:
l 如果vector保存内置类型(如int)的元素,那么标准库将用0值创建元素初始化式:
vector<int> fvec(10); // 10 elements, each initialized to 0
l 如果vector保存的是含有构造函数的类类型的元素,标准库将用该类型的默认构造函数创建元素初始化式:
vector<string> sevc(10); // 10 elements , each an empty string
5. vector 下标操作不添加元素
vector<int> ivec ; // empty vector
for(vector<int>::size_type ix = 0; ix != 10; ++ix)
ivec[ix] = ix; //disaster: ivec has no elements
在上例中ivec是空的vector对象,而下标只能用于获取已经存在的元素。
正确的写法应该是
for(vector<int>::size_type ix = 0; ix != 10; ++ix)
ivec.push_back(ix);
7. volatile变量
volatile变量有两个作用:一个是告诉编译器不要进行优化;另一个是告诉系统始终从内存中取变量的地址,而不是从缓存中取变量的值以免读取脏数据
8. vector和map进行下标操作时的区别
vector下标操作不产生新元素,map进行下标操作的话如果没有新元素会插入到map
9. 深拷贝与浅拷贝
浅拷贝其实只是复制对象,而不复制它引用的对象。即,拷贝对象的所有变量都含有被拷贝对象所含有的值,而且拷贝对象对其他对象的引用仍然指向原来的对象。例如:
char ori[]=“hello”;
char *copy=ori;
这里copy的赋值操作就是浅拷贝;copy的值等于ori的值,并且copy所指向的对象与ori相同,但是copy与ori并不是完全相等,并没有完全复制ori。
char ori[]="hello";
char *copy=new char[];
copy=ori;
深拷贝是把要复制的对象所引用的对象都复制了一遍,也就是复制对象含有了被复制对象相同的值,但是引用的对象是被复制过的新对象,而不再是被复制对象所指的对象。
- 笔试面试中C/C++重要知识点整理(不定期更新)
- c/c++笔试、面试知识点(一)
- c/c++笔试、面试知识点(二)
- C语言笔试面试常见编程题目(更新中)
- C知识点总结(格式以后再整理,近期笔试面试太多)
- 程序员笔试知识点整理(C/C++)
- 程序员笔试知识点整理(C/C++)
- Android面试常见知识点【一】(不定期更新)
- Android面试常见知识点【二】(不定期更新)
- C++所学的相关知识点整理(不定期更新)
- Objective-C知识点整理(常见面试知识点)
- C-Free 问题集(不定期更新)
- c/c++ 面试笔试知识点----牛客网(1)
- c/c++ 面试笔试知识点----牛客网(2)
- c/c++ 面试笔试知识点----牛客网(3)
- c/c++ 面试笔试知识点----牛客网(4)
- c/c++ 面试笔试知识点----牛客网(5)
- C/C++笔试知识点整理 37
- 点击tomcat出现 unable to open service tomcat
- adb shell dumpsys 命令
- 程序设计就跟我们平时头脑想的是一样的[如何按生日的年月日计算年龄(周岁)]
- 基础服务开发实例
- USACO Stringsobits, 还是得搬出动态规划来
- 笔试面试中C/C++重要知识点整理(不定期更新)
- 将整形转化为二进制存放着数组中
- 素数判定
- 分享我用Qt写的游戏组队群聊系统
- ActionServlet类未找到
- JDBC的支持——DataSource的配置
- 应用Python快速实现系统原型
- 通过反射技术创建窗体实例然后给控件赋值(C#)
- 算法导论学习笔记(13)——二项堆


