原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 、作者信息和本声明。否则将追究法律责任。http://zgwangbo.blog.51cto.com/4977613/849529
【 前一段时间写了关于架构的总结,一共十篇,放在新浪博客上 :http://blog.sina.com.cn/zgwangbo001 ,今天放到51cto上】
话说今天是清明节假期第一天,早上早早的和朋友开车逃离了帝都。现在正在G104上缓慢的爬行。
言归正传,计划了很久写这篇文章,不过心里还是比较忐忑,担心自己在技术上的深度和沉淀还是不够。不过,最后想起某老师说的:follow my heart! 想想,人生就这么些年,想做啥就做啥吧,不用想的太多。
――――――――――――― 技术开始的分割线 ―――――――――――――
2005年,我开始和朋友们开始拉活儿做网站,当时第一个网站是在linux上用jsp搭建的,到后来逐步的引入了多种框架,如webwork、hibernate等。在到后来,进入公司,开始用c/c++,做分布式计算和存储。(到那时才解开了我的一个疑惑:C语言除了用来写HelloWorld,还能干嘛?^_^)。
总而言之,网站根据不同的需求,不同的请求压力,不同的业务模型,需要不同的架构来给予支持。我从我的一些经历和感受出发,大体上总结了一下的一些阶段。详情容我慢慢道来。
【第一阶段 : 搭建属于自己的网站】
我们最先开始的网站可能是长成这个样子的:
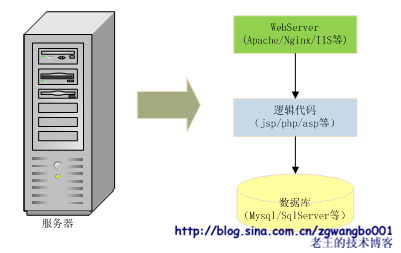
我们用jsp、asp、php等页面语言搭建最简单的业务逻辑,将数据存放在通用关系数据库中,如果有必要还搭建一个WebServer(如果偷懒的话,jsp直接使用tomcat或resin当服务器,连apache都省了)。所有的东西都放在一台服务器上(实际可能是买一个空间或者托管服务器)。这里有一个经典的单词:LAMP。
这个时候,我们的业务可能比较简单,往往是做一个×××Management Information System;数据量也比较小,通常都是几千,最多也就几万条记录;压力也比较小,估计也就每天几千,最多几万次请求。
这样做的好处就是简单,入门快。所有的代码都写在Server Page中,看起来就像是HTML中增加了很多怪异的非HTML标签和代码。根据不同的逻辑和机器性能,单机性能从几十到几千QPS(一般能到100就不错了,^_^)。
不过问题也很明显,就是页面集成了各种代码,既要负责处理请求参数,又要处理各种逻辑,还要负责连接数据库,最后输出显示…… 可想而知,代码的可重用性和可维护性是不太好的。而且,还有一个问题,像JSP这样的语言,必须在请求时才能编译,生成class代码,调试上很难受。
嗯,于是呢,我们考虑代码的可重用性和可维护性了。
【第二阶段 : 增强代码可重用性和可维护性】
我们引入了很多框架,来帮我们解决重用性问题和可维护性问题。
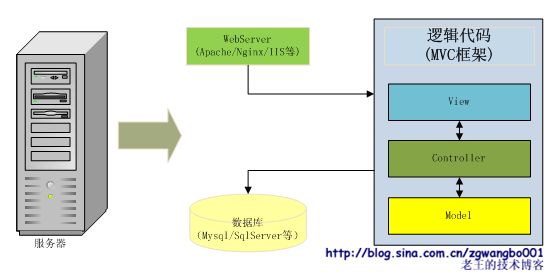
拿Java做例子,我们可能会引入struts、spring、hibernate等框架,用来做URL分流,C、V、M隔离,数据的ORM等。这样,我们的系统中,数据访问层可以抽取出很多公用的类,业务逻辑层也可以抽取出很多公用的业务类,同一个业务逻辑可以对应多个展示页面,可复用性得到极大的增强。
不过,从性能上看,引入框架后,效率并不见得比第一种架构高,有可能还有降低。因为框架可能会大量引入“反射”的机制,来创建对应的业务对象;同时,也可能增加额外的框架逻辑,来增强隔离性。从而使得整体服务能力下降。幸好,在这个阶段,业务请求量不大,性能不是我们太care的事情。J
【第三阶段 :降低磁盘压力 】
可能随着业务的持续发展,或者是网站关注度逐步提升(也有可能是搜索引擎的爬虫关注度逐步提升。我之前有一个网站,每天有超过1/3的访问量,就是各种爬虫贡献的),我们的请求量逐步变大,这个时候,往往出现瓶颈的就是磁盘性能。在linux下,用vmstat、iostat等命令,可以看到磁盘的bi、bo、wait、util等值持续高位运行。怎么办呢?
其实,在我们刚刚踏进大学校门的时候,第一门计算机课程——《计算机导论》里面就给出了解决方案。依稀记得下面这个图:
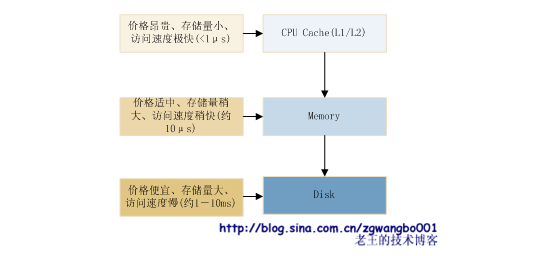
在我们的存储体系里面,磁盘一般是机械的(现在Flash、SSD等开始逐步大规模使用了),读取速度最慢,而内存访问速度较快(读取一个字节约10μs,速度较磁盘能高几百倍),速度最快的是CPU的cache。不过价格和存储空间却递减。
话题切换回来,当我们的磁盘出现性能瓶颈的时候,我们这个时候,就要考虑其他的存储介质,那么我们是用cpu cache还是内存呢,或是其他形态的磁盘?综合性价比来看,到这个阶段,我个人还是推荐使用内存。现在内存真是白菜价,而且容量持续增长(我现在就看到64G内存的机器[截止2012-4-3])。
但是问题来了,磁盘是持久化存储的,断电后。数据不会丢失,而内存却是易失性存储介质,断电后内容会丢失。因此,内存只能用来保存临时性数据,持久性数据还是需要放到磁盘等持久化介质上。因此,内存可以有多种设计,其中最常见的就是cache(其他的设计方式会在后面提及)。这种数据结构通常利用LRU算法(现在还有结合队列、集合等多种数据结构,以及排序等多种算法的cache),用于记录一段时间的临时性数据,在必要的时候可以淘汰或定期删除,以保证数据的有效性。cache通常以Key-Value形式来存储数据(也有Key-SubKey-Value,或者是Key-List,以及Key-Set等形式的)。因为数据存放在内存,所以访问速度会提高上百倍,并且极大的减少磁盘IO压力。
Cache有多种架构设计,最常见的就是穿透式和旁路式。穿透式通常是程序本身使用对应的cache代码库,将cache编译进程序,通过函数直接访问。旁路式则是以服务的方式提供查询和更新。在此阶段,我们通常使用旁路式cache,这种cache往往利用开源的服务程序直接搭建就可以使用(如MemCache)。旁路式结构如下图:
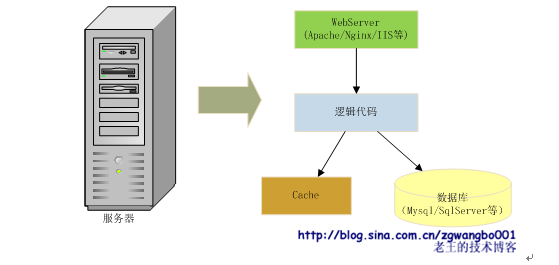
请求来临的时候,我们的程序先从cache里面取数据,如果数据存在并且有效,就直接返回结果;如果数据不存在,则从数据库里面获取,经过逻辑处理后,先写入到cache,然后再返回给用户数据。这样,我们下次再访问的时候,就可以从cache中获取数据。
Cache引入以后,最重要的就是调整内存的大小,以保证有足够的命中率。根据经验,好的内存设置,可以极大的提升命中率,从而提升服务的响应速度。如果原来IO有瓶颈的网站,经过引入内存cache以后,性能提升10倍应该是没有问题的。
不过,有一个问题就是:cache依赖。如果cache出问题(比如挂了,或是命中率下降),那就杯具了L。这个时候,服务就会直接将大的压力压向数据库,造成服务响应慢,或者是直接500。
另外,服务如果重新启动时,也会出现慢启动,即:给cache充数据的阶段。对于这种情况,可以采取回放日志,或是从数据库抽取最新数据等方式,在服务启动前,提前将一部分数据放入到cache中,保证有一定命中率。
本文出自 “老王的技术博客” 博客,请务必保留此出处http://zgwangbo.blog.51cto.com/4977613/849529


