大话编译原理---上篇
来源:互联网 发布:京东买淘宝卖 编辑:程序博客网 时间:2024/05/18 00:52
大话编译原理---上篇
前序
记得第一次上编译原理这门课时,老师曾慷慨激昂的说:“学好编译原理能让你们享用一生,你们要好好学啊”。不过学完编译原理也有一段时间了,平时也找一些编译原理方面的资料学习,却始终感受不到学习编译原理的效用。究其原因还是自己学的太单薄了,毕竟像这种“内功”可不是一天两天就能练出来的!只是感觉这门课挺有意思,权当一门兴趣来学了。
正文
本文将介绍六大节的内容,其中每个部分又分为若干小节,如下图描述:

第一节 编译程序概览
1.编译程序的定义:将高级语言编写的源程序翻译成目标语言的程序。
例如用Pascal语言、C语言、C++语言等编写的程序,都是高级语言程序。而这些程序不能直接被计算机理解和执行,必须经过等价的转换,变成机器能理解与执行的机器语言才能执行。
2.编译程序的过程:词法分析、语法分析、语义分析与中间代码生成、代码优化、目标代码生成。
①.词法分析:直白的说,就是识别单词。如关键字、标示符、常数、特殊符号。
②.语法分析:在词法分析的基础上将单词序列组合成各类语法短语。如语句、表达式等等。
③.语义分析和中间代码生成:
语义分析是对源程序进行上下文有关性质的检查,看源程序有无语义错误。例如:变量是否定义、类型是否正确。
中间代码:含义明确、便于处理的记号系统。这种记号系统于源程序和机器语言之间,容易将它翻译成目标代码。如三元式、四元式、逆波兰式等。
④.代码优化:对程序代码进行等价(不改变程序的运行结果)变换。优化的目的是使最终生成的目标代码在时间和空间上效率更高。
⑤.目标代码生成:指把语法分析后或优化后的中间代码变换成目标代码。目标代码有三种形式:
⑴.可以立即执行的机器语言代码,所有地址都重定位;
⑵.待装配的机器语言模块,当需要执行时,由连接装入程序把它们和某些运行程序连接起来,转换成能执行的机器语言代码;
⑶.汇编语言代码,须经过汇编程序汇编后,成为可执行的机器语言代码。
这就是编译过程的一般分法,不过并非所有的编译过程都分为这五个阶段。可将语义分析与中间代码生成、代码优化这两个阶段省去以加快编译速度。
3.编译程序的开发技术:自编译、交叉编译、自展、移植等。
第二节 理论基础
1.文法
①.文法的定义:对语言结构的定义和描述。例如,“The cat ate a house”。
②.文法的组成:
⑴.终结符:用小写字母表示,记为VT。
⑵.非终结符:用大写字母表示,记为VN。
⑶.文法规则集合:规则一般表示为:A->a。
一个形式文法是四元有序组G = (VN, VT, S, P)。其中,S为文法的开始符号,P是规则集。很显然,见下图:

记得第一次上编译原理这门课时,老师曾慷慨激昂的说:“学好编译原理能让你们享用一生,你们要好好学啊”。不过学完编译原理也有一段时间了,平时也找一些编译原理方面的资料学习,却始终感受不到学习编译原理的效用。究其原因还是自己学的太单薄了,毕竟像这种“内功”可不是一天两天就能练出来的!只是感觉这门课挺有意思,权当一门兴趣来学了。
正文
本文将介绍六大节的内容,其中每个部分又分为若干小节,如下图描述:
第一节 编译程序概览
1.编译程序的定义:将高级语言编写的源程序翻译成目标语言的程序。
例如用Pascal语言、C语言、C++语言等编写的程序,都是高级语言程序。而这些程序不能直接被计算机理解和执行,必须经过等价的转换,变成机器能理解与执行的机器语言才能执行。
2.编译程序的过程:词法分析、语法分析、语义分析与中间代码生成、代码优化、目标代码生成。
①.词法分析:直白的说,就是识别单词。如关键字、标示符、常数、特殊符号。
②.语法分析:在词法分析的基础上将单词序列组合成各类语法短语。如语句、表达式等等。
③.语义分析和中间代码生成:
语义分析是对源程序进行上下文有关性质的检查,看源程序有无语义错误。例如:变量是否定义、类型是否正确。
中间代码:含义明确、便于处理的记号系统。这种记号系统于源程序和机器语言之间,容易将它翻译成目标代码。如三元式、四元式、逆波兰式等。
④.代码优化:对程序代码进行等价(不改变程序的运行结果)变换。优化的目的是使最终生成的目标代码在时间和空间上效率更高。
⑤.目标代码生成:指把语法分析后或优化后的中间代码变换成目标代码。目标代码有三种形式:
⑴.可以立即执行的机器语言代码,所有地址都重定位;
⑵.待装配的机器语言模块,当需要执行时,由连接装入程序把它们和某些运行程序连接起来,转换成能执行的机器语言代码;
⑶.汇编语言代码,须经过汇编程序汇编后,成为可执行的机器语言代码。
这就是编译过程的一般分法,不过并非所有的编译过程都分为这五个阶段。可将语义分析与中间代码生成、代码优化这两个阶段省去以加快编译速度。
3.编译程序的开发技术:自编译、交叉编译、自展、移植等。
第二节 理论基础
1.文法
①.文法的定义:对语言结构的定义和描述。例如,“The cat ate a house”。
②.文法的组成:
⑴.终结符:用小写字母表示,记为VT。
⑵.非终结符:用大写字母表示,记为VN。
⑶.文法规则集合:规则一般表示为:A->a。
一个形式文法是四元有序组G = (VN, VT, S, P)。其中,S为文法的开始符号,P是规则集。很显然,见下图:
举个例子,设VN={A},VT={a,b,c},S=A,P={A->aAb, A->c}。这样就构成了文法G = ({A}, {a,b,c}, A, P)。
③.文法的分类:0型文法,1型文法,2型文法,3型文法。
0型文法:也叫短语结构文法。辨别依据:当有α->β时,左边α中必须含有非终结符,形如A->β等。
1型文法:也叫上下文有关文法。辨别依据:在0型文法的基础上,当有α->β时,定有
|α| <= |β|,其中|α| 和|β|分别表示其长度。如有A->Ba,则|α|=1,|β|=2符合1型文法要求。反之,如aA->a,则不符合1型文法。
附注:虽然要求|α| <= |β|,但有一特例:α->ε也满足1型文法。
2型文法:也叫上下文无关文法。辨别依据:在1型文法的基础上,当有α->β时,α必是终结符。如A->Ba,符合2型文法要求。 如果是Aa->Ba这样的形式,那么就不满足了,因为Aa不是一个非终结符。
3型文法:也叫正则文法。辨别依据:在2型文法的基础上需满足:A->a|aB(右线性)或A->a|Ba(左线性)。


③.文法的分类:0型文法,1型文法,2型文法,3型文法。
0型文法:也叫短语结构文法。辨别依据:当有α->β时,左边α中必须含有非终结符,形如A->β等。
1型文法:也叫上下文有关文法。辨别依据:在0型文法的基础上,当有α->β时,定有
|α| <= |β|,其中|α| 和|β|分别表示其长度。如有A->Ba,则|α|=1,|β|=2符合1型文法要求。反之,如aA->a,则不符合1型文法。
附注:虽然要求|α| <= |β|,但有一特例:α->ε也满足1型文法。
2型文法:也叫上下文无关文法。辨别依据:在1型文法的基础上,当有α->β时,α必是终结符。如A->Ba,符合2型文法要求。 如果是Aa->Ba这样的形式,那么就不满足了,因为Aa不是一个非终结符。
3型文法:也叫正则文法。辨别依据:在2型文法的基础上需满足:A->a|aB(右线性)或A->a|Ba(左线性)。
由此便可得出四类文法的关系:见下图
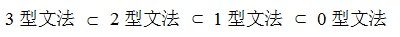
④.文法的二义性:对于某文法的同一个句子存在两种不同的语法树。如下图:
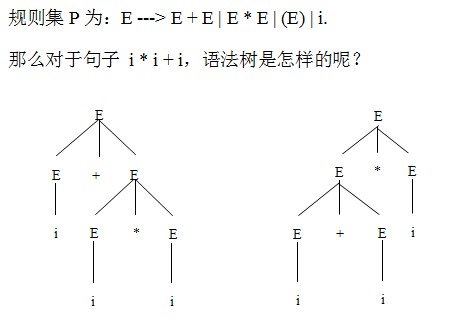
由语法树我们得出句子“i+i*i”是二义性的。
既然文法会出现二义性,那么怎么解决二义性呢?办法有二:修改编译算法;修改文法。
2.自动机
自动机:能识别或生成语言的识别器。
在谈有限自动机之前,先解释一下术语状态转换。所谓状态转换,就是当读入一个字符时,使状态改变为另一状态,改变后的状态称为后继状态。
①.确定优先自动机(DFA):只有一个初始状态,可以有不止一个终止状态。转换的后继状态都是唯一的。例:

既然文法会出现二义性,那么怎么解决二义性呢?办法有二:修改编译算法;修改文法。
2.自动机
自动机:能识别或生成语言的识别器。
在谈有限自动机之前,先解释一下术语状态转换。所谓状态转换,就是当读入一个字符时,使状态改变为另一状态,改变后的状态称为后继状态。
①.确定优先自动机(DFA):只有一个初始状态,可以有不止一个终止状态。转换的后继状态都是唯一的。例:
P集为: Z -> Za | Aa | Bb
A -> Ba | a
B -> Ab | b
构造的状态转换图如下图:A -> Ba | a
B -> Ab | b
②.不确定有限自动机(NFA):可以有若干个开始状态,可以有若干个终止状态。转换的后继状态可有多个。例:

P集为: Z -> Za | Aa | Bb
A -> Ba | Za | a
B -> Ab | Ba | b
构造的状态转换图如下图:A -> Ba | Za | a
B -> Ab | Ba | b
③.NFA到DFA的转换
转换法则:由初始状态S开始,求状态的转换,若有新的状态出现,继续求新状态的转换,直至没有新的状态出现为止。例:
转换法则:由初始状态S开始,求状态的转换,若有新的状态出现,继续求新状态的转换,直至没有新的状态出现为止。例:
P集为: Z -> Za | Aa | Bb
A -> Ba | Za | a
B -> Ab | Ba | b
构造的NFA的状态转换图如下图:A -> Ba | Za | a
B -> Ab | Ba | b
由NFA的状态转换图根据转换法则就可得到DFA的状态转换表如下图:

由DFA的状态转换表就可得到DFA的状态转换图了。状态转换图在这就不展示了,如果你有兴趣的话,自己可以画一下。
④.DFA的化简:去掉等价状态和无关状态。
附注:如果是NFA,则需先将NFA化简成DFA,而后再化简即可。
第三节 词法分析程序之设计原理
1.词法分析的功能:读入源程序字符串,从左至右逐个扫描,并从其中识别出具有独立意义的最小语法单元---单词。
2.词法分析的两种处理结构
①.词法分析程序作为主程序,即把词法分析作为独立的一趟来完成。
②.词法分析程序作为子程序,即把词法分析作为一个供语法分析程序调用的子程序。
3.词法分析程序的流程
在谈流程之前多说两句,词法分析在前文中已说过,其实就是识别单词。那么此时我们就有必要了解一下单词符号的种类了。
单词符号的种类:保留字、标示符、无符号数、界限符。
保留字:也叫关键字,如if、else、do、for、return等。
标示符:用来标记常量、变量、函数等的名字,这是由自己定义的,如i,j,max等。
无符号数:如256、0.5、3E2等等。
界限符:如+、-、*、++、--、>=、==等等。
了解了单词,我们就来看看流程图吧!如下:

OK,前三节就将完了,后面三节将在下篇文章中继续。
④.DFA的化简:去掉等价状态和无关状态。
附注:如果是NFA,则需先将NFA化简成DFA,而后再化简即可。
第三节 词法分析程序之设计原理
1.词法分析的功能:读入源程序字符串,从左至右逐个扫描,并从其中识别出具有独立意义的最小语法单元---单词。
2.词法分析的两种处理结构
①.词法分析程序作为主程序,即把词法分析作为独立的一趟来完成。
②.词法分析程序作为子程序,即把词法分析作为一个供语法分析程序调用的子程序。
3.词法分析程序的流程
在谈流程之前多说两句,词法分析在前文中已说过,其实就是识别单词。那么此时我们就有必要了解一下单词符号的种类了。
单词符号的种类:保留字、标示符、无符号数、界限符。
保留字:也叫关键字,如if、else、do、for、return等。
标示符:用来标记常量、变量、函数等的名字,这是由自己定义的,如i,j,max等。
无符号数:如256、0.5、3E2等等。
界限符:如+、-、*、++、--、>=、==等等。
了解了单词,我们就来看看流程图吧!如下:
- 大话编译原理---上篇
- 大话调试器(上篇)
- 大话浅析DNS原理
- 大话数据结构读书笔记系列(六)树<上篇>
- SQL查询入门(上篇) 原理型
- 大话Elasticsearch常用操作和核心原理
- 大话Google Chrome之编译篇
- 大话解释型语言、编译型语言
- 编译原理
- 《编译原理》
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- 编译原理
- JAVA获取当前操作系统的信息
- Objective-C Primer(2)Private Methods and Class Properties
- LaTeX 中算法有关宏包和命令的使用
- Objective-C Primer(3)Multiple arguments for one method, synthesize and dynamic
- 字符编码笔记:ASCII,Unicode和UTF-8
- 大话编译原理---上篇
- iOS中的url编码问题
- 比一比才知道 GET vs POST
- 16个桌面Linux用户必须要知道的Shell命令
- 梦入IBM之java基础第三天
- 【Kinect开发手记一】准备
- WEB应用之: JS 数组的遍历与元素删除
- 程序员必知8大排序3大查找(二)
- 10026 - Shoemaker's Problem


