在内存墙的困扰中寻找出路
来源:互联网 发布:snmp 端口号 编辑:程序博客网 时间:2024/05/16 15:19
提到系统的性能瓶颈,也许大家最先想到的是硬盘,但你知道内存同样也是系统中的性能“短板”吗?
难以置信?那就让我们揭开内存及其相关技术的面纱,好好看清内存发展的本质吧。
由于处理器厂商与内存厂商相互分离的产业格局,导致了内存技术与处理器技术发展的不同步。在过去的20多年中,处理器的性能以每年大约55%速度快速提升,而内存性能的提升速度则只有每年10%左右。长期累积下来,不均衡的发展速度造成了当前内存的存取速度严重滞后于处理器的计算速度,内存瓶颈导致高性能处理器难以发挥出应有的功效,这对日益增长的高性能计算
(High Performance Computing,HPC)形成了极大的制约。事实上,早在1994年就有科学家分析和预测了这一问题,并将这种严重阻碍处理器性能发挥的内存瓶颈命名为”内存墙”(Memory Wall)。
多核处理器的“内存墙”问题日趋严重
当处理器厂商意识到单纯依靠提高处理器频率并不能持续提升计算性能时,便把目光转向了利用多核心并行计算技术来提升计算性能,同时也希望该技术能缓解内存瓶颈。
但处理器核心越多,性能就越高吗?实际情况并没有那么简单,除了如何有效地给多核心分配任务这一难题之外(核心越多,任务分配的难度越大),多核心并行计算还遭遇到了更为严重的“内存墙”问题。这是因为在高度并行的处理方式下,多核心共享有限的内存带宽将会造成更大的延迟,就好像一条高速公路只有4条道,却有4辆以上的车要并列行驶,当然会造成道路拥堵、行驶缓慢了。

SNL的多核处理器性能仿真测试结果
美国桑迪亚国家实验室(Sandia National Laboratories,SNL)所进行的一项多核处理器性能仿真测试也正好验证了上述问题,SNL研究人员在一篇题为《多核对超级计算机是一个坏消息》的文章中指出:在信息科学领域,更多核心的处理器并不一定会带来更高的处理性能。SNL的仿真测试结果表明:由于“内存墙”的制约,超过8核心之后,处理器性能几乎没有提升,而16核处理器的性能甚至不升反降。由此可见,随着处理器核心的不断增多、处理性能的不断提升,“内存墙”产生的瓶颈效应对基于多核处理器的高性能计算的制约将日趋严重。
好在认识到“内存墙”问题的严重性之后,处理器和内存厂商就一直在尝试解决“内存墙”的问题,并且已经找到了不少行之有效的方法。
降低“内存墙”影响的两条基本途径
内存的性能指标主要有“带宽”(Bandwidth)和“等待时间”(Latency),从这两项指标的基本概念出发,更便于我们理解与“内存墙”问题相关的技术发展。
1.内存带宽及其提升技术
内存带宽(Bandwidth)指内存在单位时间内通过总线传输的数据量,可以用公式“内存带宽=(传输倍率×总线位宽×工作频率)÷8”进行计算,单位为“字节/秒”(Byte/s)。总线位宽指内存数据总线的位数,工作频率也就是内存的时钟频率,传输倍率是指每条内存数据线在一个时钟脉冲周期内传输数据的次数。显然,提高内存带宽的基本方法当就是公式中决定内存带宽的三个因素,即总线位宽、工作频率和传输倍率。
提高内存总线位宽:在现有采用独立内存芯片的架构下,进一步增加内存位宽受到了内存芯片数据线引脚数量的限制,所以通过增加位宽来提升内存带宽的方式,需要采用能有效消除这种引脚限制的新型内存架构。例如受到广泛关注的“内存与处理器集成”技术,就具有通过增加内存位宽来明显提升内存带宽的特点。
提高内存工作频率:单纯依靠提高工作频率来提升内存带宽的方法,会受到内存芯片发热量和工艺难度增加等方面的制约,所以采用这种方法进一步提高内存带宽的空间非常有限。
提高内存传输倍率:通过增加传输倍率来提升内存带宽的方法对大家来说更为熟悉。例如DDR内存是双倍数据率(Double Data Rate),其每条数据线都能够从存储单元预取2位数据,并分别在时钟脉冲的上升沿和下降沿各传输1位数据,即在一个时钟周期的传输倍率为2,在相同频率下DDR内存的数据传输量是SDRAM内存的2倍。同理,DDR2内存、DDR3内存的传输倍率分别为4、8,而Rambus的“百万兆字节带宽”技术则可将传输倍率提高到32,从而大幅度提升内存的带宽。
2.内存等待时间及其屏蔽技术
内存等待时间(Latency),即从处理器向内存发出访问请求到内存发出数据所用的时间,一般用“纳秒”(ns)来度量。相对于处理器的高速处理能力而言,内存等待时间显得过长,在现有内存技术还不能从根本上大幅度降低等待时间的情况下,利用高速缓存技术和并行处理技术来尽量降低“内存墙”的影响目前仍然是有效的方法。
内存等待时间屏蔽技术:将处理器可能访问的数据和程序代码预先保存到高速缓存中,尽可能地减少处理器对内存的直接访问,而是从高速的缓存中获取数据,就是一种典型的内存等待时间屏蔽(Latency Hiding)技术。这种基于缓存机制的技术一直是降低“内存墙”影响的常规方法。
硬件支持的并行处理技术:虽然由硬件支持的多线程、乱序执行等并行处理技术并不能直接解决“内存墙”问题,但多线程和乱序执行的并行处理机制,能够更有效地减少在处理任务过程中处理器资源被闲置的情况,当处理器处理大量任务时其“资源不被闲置”所产生的累积效应,就能使吞吐量明显增加,因此整体的处理效率就相应地有所提升,从而在一定程度上屏蔽了“内存墙”的影响。
现实中如何降低内存等待时间
由于提升内存的工作频率难度很大,因此在降低内存等待时间时,厂商并非直接改进内存,而是将目光集中在如何优化处理器对内存的使用上。从最新的Intel Core i7和AMD Phenom Ⅱ等四核处理器中可以看到,用于降低内存等待时间的缓存和预取、多线程和乱序执行等技术被进一步改进,同时处理器集成内存控制器进一步降低了内存等待时间。
1.增强的多级缓存和预取技术
当处理器需要读取数据时,首先会在自己的缓存中查找,如果找到就高速读取到核心中处理,这被称为“缓存命中”,访问缓存的命中次数与总访问次数的比率称为“命中率”(Hit Rate)。利用缓存有效降低内存等待时间的关键是要尽可能提高缓存命中率,目前多核处理器缓存技术的发展趋势是采用更大容量的、更多级的缓存结构,以及更为有效的缓存管理和数据预取技术。
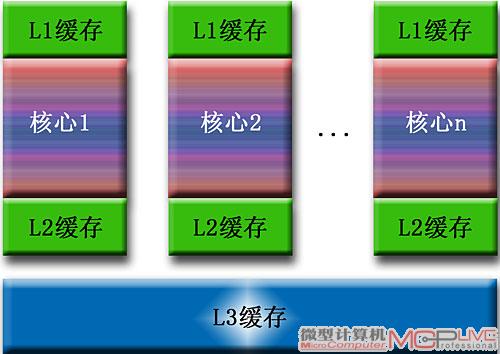
多核处理器的三级缓存设计
增强的大容量多级缓存设计:增加缓存的容量可保存更多的数据,显然能提高缓存命中率。而增加缓存的层级是提高缓存命中率的另一种途径,例如两级缓存中L1、L2的理论命中率均为80%左右,两级缓存总的命中率大约为(80+0.2×80)%=96%,依此类推缓存级层越多命中率越高。因此在Core i7和Phenom Ⅱ等新一代四核处理器中,都采用了大容量的三级缓存结构,每个处理器核心都具有独立的L1、L2两级缓存,共享大容量L3缓存,其中Phenom Ⅱ的L3缓存容量为6MB,Core i7的L3缓存容量更达到了8MB,并且Core i7的微架构中还采用了易扩展设计,为今后继续增大L3缓存容量埋下了伏笔。
更有效的缓存管理技术:对于多核处理器的缓存系统而言,采用更有效的缓存管理技术也是非常重要的。例如Core i7采用了“先进的智能缓存”(Advanced Smart Cache,ASC)技术,可根据各个核心的处理负载动态分配共享的L3缓存,从而提高了各核心从共享的L3中读取数据的效率。
ASC对共享的L3缓存采用了“包容性”(Inclusive)机制,即L1、L2中的数据都包含在L3中,当一个核心访问L3没有命中时,会立即转向访问内存读取数据,从而有效降低了继续查找L1、L2所产生的侦听通信量和时间延迟。ASC还引入了基于L3包容性机制的“侦听过滤”(Snoop Filter)技术,当处理器访问L3命中时并不直接从速度较慢的L3读取所需数据,而是转向速度更快的L1或L2读取,从而减少了处理器获取数据的时间。
更有效的数据预取技术:即基于一定的预测机制,把处理器最可能用到的数据预先从内存读取到缓存中,从而提高缓存命中率。数据预取可通过处理器内置的预取器(Prefetcher)以硬件预取方式实现,也可在程序中调用处理器的预取指令以软件预取方式实现。例如Phenom Ⅱ的每个核心有1个指令预取器和1个数据预取器,并采用了“先进的内存预取器”(Advanced Memory Prefetcher,AMP)技术。AMP可绕过L2将数据直接从内存读取到L1中,避免了L2的延时,也减轻了L2的负载。AMP技术具有“自适应预取”(Adaptive Prefetch,AP)机制,可基于对内存请求的监测和分析预取任何地址的数据。AMP还引入了置于内存控制器中的“DRAM预取器”,可配合AP机制监测整体的内存访问请求,把可能用到的数据预先提取到DRAM预取缓冲器中,以便在需要时以更快的速度传送这些数据。
2.多线程和乱序执行技术
“超线程”(Hyper-Threading,HT)也称作“同步多线程”(Simultaneous Multi-Threading,SMT)。HT技术起源于Pentium 4处理器,由于处理器核心的寄存器等多个部件都配置了两套,所以可以在处理器中增加一个线程调度单元,将两个线程的指令序列分配到这些两套部件中,就相当于同时激活了两个线程。当一个线程因等待数据而处于停顿状态时,立即让另一线程执行任务,从而避免了处理器资源被闲置,提升了处理效率。在Core i7处理器中,同样使用了HT技术,并且指令执行机制更高效,缓存容量和内存带宽更大,配合高度线程化的应用程序,Core i7处理器的HT技术在降低内存等待时间、提升整体的处理效率方面更为有效。

著名的“超线程”HT技术的实质就是降低内存等待时间
乱序执行(Out-of-Order Execution,OOOE)是一种指令级并行计算的处理器设计。支持OOOE的处理器可以不按程序中原有的指令顺序执行任务,而是通过OOOE引擎监测和分析哪些处理器单元会被闲置、程序中的哪些指令可不按顺序提前执行,再将这些指令分配给闲置的处理单元开始执行,然后将其运算结果按程序中的原有顺序重新排列。OOOE利用并行处理机制避免了处理器资源的闲置,与HT技术一道提升了处理器的整体处理效率。最新的多核处理器均强化了OOOE的设计,例如Core i7中“重排序缓冲器”(Re-Order Buffer,ROB)等关键OOOE单元的规模被明显加大,Intel“智能内存访问”(Smart Memory Access,SMA)技术则提高了OOOE的效率。SMA除了指令级的预取管理功能之外,还具有“内存数据相关性预测”(Memory Disambiguation)机制,能对指令之间的相关性进行分析,智能化地预测将要执行的指令,并提前将其所需数据预取到缓存中,使这些指令执行时能快速获取所需数据,从而有效降低了等待数据的延迟。
3.集成式内存控制器
“集成式内存控制器”(Integrated Memory Controller,IMC)技术大家应该也不陌生。在消费级处理器上,该技术最早应用在AMD Athlon处理器上。它将原来北桥芯片组中的内存控制器集成在处理器芯片中,缩短了处理器访问内存的物理路径,从而降低了读取内存的延迟;同时可使内存控制器与处理器运行在相同的时钟频率下,能够在很大程度上减少处理器访问内存数据的等待时间。
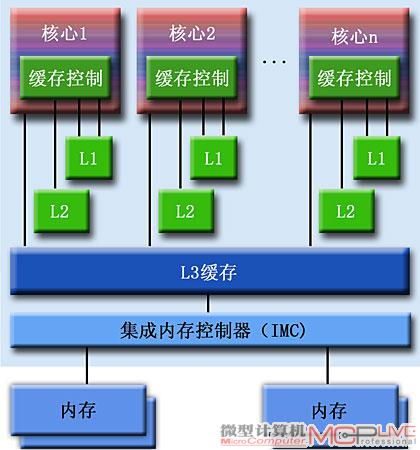
集成内存控制器的多核处理器
在Phenom Ⅱ处理器中,集成的是双通道DDR2 1066和DDR3 1333内存控制器;Core i7处理器则首次集成了三通道DDR3 1333内存控制器。再配合AMD HyperTransport 3.0、Intel QuickPath Interconnect(QPI)总线技术,可有效提升各核心对内存的存取效率。
提升内存带宽的各种努力
除了利用多级缓存、并行处理等技术降低内存等待时间之外,降低“内存墙”影响的另一种途径当然就是提升内存带宽,尽可能缩小内存与处理器的性能差距。如前所述,当提高工作频率遭遇发热和工艺方面的瓶颈后,人们一直在尝试通过提高内存的传输效率、传输位宽和传输倍率等方法来提升内存的传输带宽。
1.利用缓冲器提升内存性能的技术
“全缓冲双列直插式内存模块”(Fully-Buffered DIMM,FBD)是一种能有效扩展DDR2/DDR3内存带宽和容量的技术,其关键硬件是Intel的“先进内存缓冲器”(Advanced Memory Buffer,AMB)。在FBD内存架构中,内存模块不再与内存控制器直接交换数据,而是通过AMB进行缓冲处理。AMB的通用内存接口可连接DDR2/DDR3内存模块,AMB与内存控制器则采用多路的点对点高速串行链接连接方式,以取代常规的共享式并行连接,即每个DIMM插槽上内存条的AMB互相串联起来,并采用点对点的传输方式,数据依次从一个缓冲器传向下一个缓冲器,这种串接方式的优点是具有恒定的点对点连接阻抗,提高了信号传输的稳定性和可靠性。

常规并行连接与FBD的串行链接
AMB的每一路串行连接都采用了自同步(Self-Clocking)传输技术,数据接收端的时钟频率可随数据流的大小自动调节,这种传输方式有效地提高了数据的传输速度,从而可将传输带宽提升4倍。由于FBD采用串行传输方式,可以用更少的引脚建立更多的内存通道,并且每个内存通道可连接更大容量的内存模块,因此FBD可使内存系统的总容量扩展到384GB。不过,由于FBD内存的功耗和造价较高,故而主要应用于服务器、工作站和高性能计算机。
FBD内存缓冲技术今后的发展趋势,是取消现行将AMB组合在内存上的方案,而直接将AMB芯片置于主板上或者采用插卡的形式,这就是所谓的“板载缓冲器”(Buffer On Board,BOB)技术。此外,AMD也开发有类似的G3MX(G3 Memory Extender)内存扩展技术,Inphi的“隔离式内存缓冲器”(Isolation Memory Buffer,IMB)也是一种内存缓冲技术。
2.增加传输倍率提升内存性能的技术
通过提高内存传输倍率来提升带宽是内存技术发展的一个主要趋势。例如从DDR、DDR2的2、4倍传输率到DDR3的8倍传输率,此外还出现过其它提升内存传输倍率的技术,例如“4倍带宽内存”(Quad Band Memory,QBM)技术主要是利用场效应管使DDR内存能够在一个时钟周期内传输4次数据,从而将内存带宽提升4倍。
Rambus公司近几年启动的“百万兆字节带宽开创计划”(Terabyte Bandwidth Initiative,TBI)备受关注。TBI的目标是开发百万兆级带宽的单芯片内存控制系统。Rambus目前已开发了“32倍数据传输率”(32X Data Rate)、“全差分内存架构”(Fully Differential Memory Architecture,FDMA)和FlexLink可扩展链接等关键技术。基于TBI技术的新型内存将为高性能的多核处理器系统以及图形处理、游戏等应用提供完整有效的解决方案。按照Rambus的计划,基于TBI技术的第1代XDR2 SoC芯片,能使单片DRAM内存的带宽达到38.4GB/s,第2代XDR2 SOC芯片可使单片DR AM的带宽达到51.2GB/s,其进一步的目标是实现一个内存控制芯片连接16片DRAM内存,从而使总带宽达到百万兆字节每秒,即1024GB/s或1TB/s。

有效提升内存带宽的32倍传输率技术
32倍数据传输率技术采用极为精确的锁相环倍频电路,将输入的时钟信号转换为32倍频的内部时钟信号,从而使内存数据通道在一个输入时钟信号周期内把32位数据传输到内存缓冲器中,是一种全新的32位缓冲预取架构,用500MHz的时钟频率就可达到16GB/s的传输率,因此32倍数据率技术将可大幅度提升内存的带宽。FDMA技术利用抗干扰性能极强的差分信号传输方式,为数据、指令和地址信号在内存控制器与内存之间的传输提供更可靠更有效的通道。FlexLink是一种创新的高速可扩展点对点式命令和地址链接架构,2路链接就可达到16GB/s的连接速率,简化了内存与内存控制器的连接,并且易于扩展内存容量。
更先进的内存与处理器集成技术
相比上述单纯降低内存等待时间和提升内存带宽的现有技术,业界还致力于研究更加先进的内存与处理器集成技术。这类技术中最有代表性的就是“在内存中处理”(Processingin Memory,PIM),其基本思路是将内存与多核处理器集成到同一颗芯片中。此外,“智能随机存取存储器”(Intelligent Random Access Memory,IRAM)和“嵌入式动态随机存储器”(Embedded Dynamic Random Access Memory,EDRAM)技术也是基于将内存与处理器集成的原理。
PIM技术的优势主要体现在两个方面:一是能够有效降低内存等待时间,由于处理器各核心与内存之间的物理距离明显缩短,核心访问内存的等待时间也随之被有效减少,即由原来的芯片间延时变为芯片内延时;二是具有提升内存带宽的潜力,传统的独立式内存架构由于受到内存芯片引脚数目的限制,难以通过采用增加数据线引脚来提高内存的位宽,而PIM技术则能使核心与内存在同一芯片内部建立更宽的数据传输通道,没有引脚的限制,因而更容易通过增加位宽来提升内存带宽。

采用3D堆叠芯片封装的Intel 80核处理器
理论计算表明,PIM技术所具有的这些特点,将有可能使内存的反应时间降低5~10倍,带宽提升50~100倍,能耗降低50%~75%。目前很多厂商都在研发“三维堆叠芯片”(3D Stacking Chip)封装技术,以最终制造出基于3D堆叠的PIM芯片。
例如桑迪亚国家实验室(SNL)研发的X-Caliber处理器,就是将DRAM内存堆叠在多核处理器逻辑电路层上的PIM芯片,其性能可随核心数量的不断增加呈现上升的平稳趋势。不过,3D堆叠芯片封装技术目前面临的一个主要难题是散热问题,还需要在堆叠方式、散热、电源和热管理技术等方面取得进一步的突破。
摆脱““内存墙””围困的远景展望
更多的核心≠更高的性能:由于“内存墙”等问题对多核处理器性能提升形成的严重阻碍,AMD认为单纯依靠增加处理器核心的办法不可行,Intel也表示在现有发展环境下超过16核心不会明显提高性能。对于未来处理器性能的提升,Intel比较关注处理器浮点运算能力的增强,而AMD似乎更倾向于采用基于GPU的流处理技术。由此看来,在多核处理器的“内存墙”等问题还不能从根本上有所突破的情况下,将不大可能继续大幅度增加处理器的核心数量来提升处理性能,而需要另辟蹊径满足日益增长的对高性能计算的需求。
“将一切多重化”的思路:据报道,美国专家Joseph Ashwood设计了一种全新架构的存储系统,其最大特点是能够实现并行存取,存取速度明显高于现在的串行存取方式存储器。由于这种新型存储系统与多核处理器的并行处理机制相适应,故而被称作“多核存储器”。虽然“多核存储器”目前只完成了书面设计,距离实际应用还有很远,但其思路却与一些研究人员提出的“将一切多重化”(Multi-Everything)的理论不谋而合,也许“多线程”、“多核处理器”、“多核内存”等技术的发展轨迹,就是解决“内存墙”问题的一种可能途径。
未来新一代存储技术的发展:开发基于全新架构和新型器件的存储器,从而缩小内存与处理器性能差距应该是解决“内存墙”问题的一种更有效的途径。例如正在发展的“相变存储器”(PCM)、“可编程金属单元存储器”(PMCM)、“磁性随机存取存储器(MRAM)、“铁电随机存取存储器”(FRAM)、“纳米管随机存取存储器”(NRAM)和“记忆电阻”(Memristor)等新型存储技术,其中一些非易失存储器已有望取代目前的闪存。而随着技术的进一步发展,某些新型的高速存储器将有可能最终取代现在的DRAM内存。
各种全新计算机构架的研究:迄今为止的计算机系统架构都是基于冯·诺伊曼的“存储程序原理”,因此根本的解决办法或许是采用非“冯·诺伊曼”的全新计算机架构。例如“数据流机器”(DFM)、“人工神经网络”(ANN)等均摒弃了存储程序的原理,因而不再存在“内存墙”的问题。
总之,我们从计算机技术的发展历程中不难看出,科学家很早就意识到了“内存墙”问题。针对内存带宽和内存等待时间两大基本途径,前者的应对方法是采用提高内存总线位宽和传输倍率的技术;后者是采用多级缓存和预取、多线程和乱序执行等技术;而近期热门的内存与处理器集成技术更彻底地同时优化内存带宽和内存等待时间。不过,人们对更高性能计算的追求是没有止境的,在多核处理器性能越来越强的情况下,人们必须突破“内存墙”的重重阻碍,找到走向更高性能计算的通途。
- 在内存墙的困扰中寻找出路
- 寻找迷宫的出路
- 程序在内存中运行的奥秘
- 程序在内存中运行的奥秘
- 在内存中我知道的
- 程序在内存中运行的奥秘
- 程序在内存中运行的奥秘
- 程序在内存中运行的奥秘
- 程序在内存中运行的奥秘
- 程序在内存中运行的奥秘
- 数据在内存中存放的位置
- 图片在内存中占用的大小
- 程序在内存中运行的奥秘
- 在内存中创建原图的副本
- 在内存中绘图
- 在内存中绘图
- DWORD变量在内存中和纯单引号的串在内存中存储顺序
- java中数据类型在内存中存储的方式
- Three20的安装过程
- 每两部Andriod智能手机里,就有一部是三星
- hive 中的多列进行group by查询方法
- 如何在点击android中的EditText的时候不弹出软键盘
- 解决checkbox未选中,无法获取其value值的方法
- 在内存墙的困扰中寻找出路
- java如数据库乱码问题
- Servlet简介及工作原理
- Struts2 Action多方法调用
- struts2中 Action获取表单参数的几种方式
- 进程栈大小 与 线程栈大小
- adb-Android debug bridge(安卓调试桥)
- 关于C#中的错误:The type 'X' does not exists in the "Y"
- Sqlite简单介绍与一些常用的例子


