Finding a needle in Haystack:Facebook's photo storage的理解
来源:互联网 发布:佣兵天下的java游戏 编辑:程序博客网 时间:2024/05/01 16:50
博客的所有内容都是个人理解,难免有理解错误的地方,欢迎大家多多拍砖!
这是facebook发在OSDI上的一篇论文,讲述了facebook用于存储用户图片的系统Haystack,目前facebook存储了260billion图片,而图片文件显然都是小文件,使用传统的方式存储数量如此巨大的小文件,必然会带了很大的性能问题。
1、元信息数量庞大。因为每一个图片都会当做一个文件进行存储,每个文件都有相应的元信息,其中很多元信息对于facebook来说是没有用处的。
2、元信息的读取成为瓶颈。因此查找一个文件必须将所有的元信息加载到内存中,对于PB级别的小文件,这个读取过程非常的消耗时间。
3、读取一个图片至少需要3次IO。将元信息读到内存,将Inode读到内存,最后将具体的内容读到内存。
原先的实现方案是NAS加CDN的实现方式,这种实现方案,主要是利用了facebook图片应用的特点。
1、一次写多次读,从不修改,极少删除。
2、最近上传的图片是访问的热点数据,时间较长的图片较少被访问。
CDN对热点数据进行缓存,所以对于大部分访问有较好的支持,但是由于facebook庞大的用户群,即使存储较长的时间较少被访问,但是总的访问量也比较巨大,这就导致了长尾问题。为了缓解长尾问题,facebook试图在每个NAS上部署自己的memecache,但是最终的效果很不理想。如果在CDN上不能命中catch,在NAS上也基本不可能命中memcache。最终得出的结论是,靠缓存提升性能的空间是有限的,必须从架构上进行改变。
基于这些问题,facebook设计了Haystack,Haystack主要为满足以下几点的需求:
1、高吞吐量和低访问延迟。保证每次读取只有一次IO,通过将元信息存储在内存中实现。
2、容错机制,采用类似GFS的冗余备份机制,在不同地点的物理节点上存储冗余数据,保证数据的安全。
3、廉价,总体的花费要少于之前的实现方案。
4、简单。为使Haystack尽快的投入使用,必须保证系统的简单。
Haystack的主要思想是将许多的小图片文件存储到一个大文件中,这样文件系统只需要管理少量的大文件即可,有效的减少了元信息的数量。主要三部分组成:Directory、Store、Catch。其实Haystack的这个设计与HDFS有很多的相似点,其中Directory作用相当于NameNode,Store作用相当于DataNode,logic volum 相当于blockId,physical volume相当于block。Catch是为快速响应请求添加的模块,如果HDFS用来做低延时的访问应用,也应该加上Catch。同样采用了冗余备份的机制,其中一个logic volum对应多个physical volume,physical volume相互备份,在发生数据丢失时进行恢复。
再来看一下Haystack的数据上传和查询的流程。
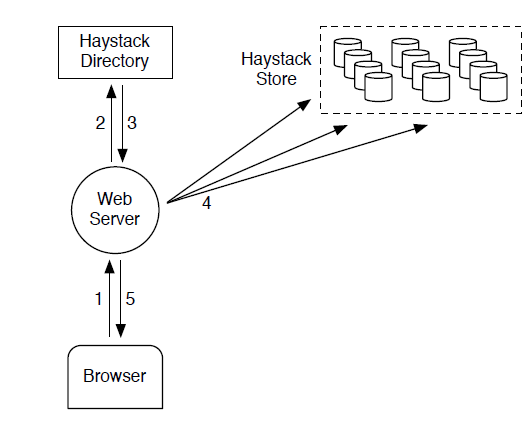
上传流程如上图所示,数据首先传输到WebServer端,WebServer端向Directory请求一个可写logic volum,然后将数据传输到该logic volum对应的不同的physical volume上。
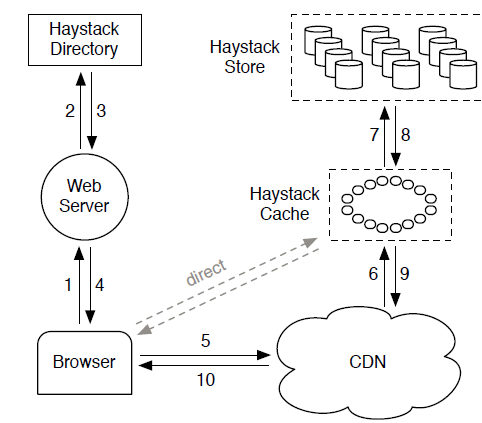
数据读取的流程如上图所示,请求到达webServer端,在Directory端构造读取的URL,格式如下:

根据URL由外向内依次进行读取。
下面来看一下三个核心模块的介绍:
1、Directory
该部分有四个主要的功能:第一,保存logic volum到physical volume的映射;第二,进行负载均衡;第三,决定使用CDN还是Catch;第四,判定那些logic volum是只读的。
2、Catch
Haystack里的catch是一个分布式的hash表,使用图片的id所谓key值。上文中也提到CDN之后的catch作用是很微弱的。所以Catch中只存储满足下边两个条件的内容:
1、来在客户端直接的请求;2、从可写physical volume读出的内容。
第二个条件存在的原因是,facebook应用的特点,刚上传的图片往往有较大的访问量。
3、Store
Store是最复杂的一个部分,主要的设计思想就是在某一个physical volume能够通过图片的Id在海量的图片中直接定位到想要读取的图片,并且只进行一次IO。通过在内存中存储本机存储的海量图片的索引信息,保证元信息的查询都是全内存操作。
对于facebook这种图片上传随时都在进行的系统,如何保证中的index与写到磁盘上的index一致是一个比较重要的问题,尤其是在某台机器宕机的情况下。因为磁盘上存储的index文件是内存中元信息在某个时间点的快照,所以在机器重启时重建内存中的元信息除了读取index文件之外还需要根据index文件判断磁盘上那些信息没有存储在index文件中,这个根据index文件和磁盘上最后写入的内容很容易判断。这样就在短时间内构建起了海量图片文件对应的元信息。
对于这篇论文个人总结一下,从文件系统的角度基本上也是受GFS思想的启发,采用主从式的设计架构,从用冗余备份的机制。但是类GFS文件系统是不能满足海量小文件存储和低延迟访问的需求的(HDFS也有人再做相关的研究,当然笔者也做过一些工作,后续的博客也会介绍),因此facebook采用了目前解决小文件问题比较流行的思想,将小文件合并成大文件并对小文件建立索引的思想,国内的TFS也是采用的类似的解决方案解决得也是类似的应用问题(淘宝中商品的展示图片)。
- Finding a needle in Haystack:Facebook's photo storage的理解
- Finding a needle in Haystack: Facebook’s photo storage
- 经典论文翻译导读之《Finding a needle in Haystack: Facebook’s photo storage》
- 经典论文翻译导读之《Finding a needle in Haystack: Facebook’s photo storage》
- 经典论文翻译导读之《Finding a needle in Haystack: Facebook’s photo storage》
- Facebook photo-storage [haystack]
- GmH (Geometric min-Hashing: Finding a (Thick) Needle in a Haystack)
- How would HBase compare to Facebook's Haystack for photo storage?
- E文积累_20080303_find a needle in a haystack
- How Google Finds Your Needle in the Web's Haystack
- How Google Finds Your Needle in the Web's Haystack
- The First Occurrence of Needle In Haystack
- *haystack++ != *needle++
- facebook 照片存储系统haystack的学习
- Facebook Haystack 管理百亿照片
- Facebook Haystack图片存储架构
- Facebook Haystack图片存储架构
- facebook photo serving stack
- Netty之源代码解析
- 常用类型 总结
- Shell Perl Python 脚本语言介绍
- android翻书效果实现原理( 贝塞尔曲线绘制原理/点坐标计算)
- UIWebView 控制页面 字体 大小
- Finding a needle in Haystack:Facebook's photo storage的理解
- UIScrollView 实现 重用机制 dome
- eclipse或者myeclipse的Help菜单下找不到SoftWare Updates菜单的解决
- IsBadReadPtr
- DPC,时钟中断,以及DPC定时器(1)
- ASIHTTPRequest Url 请求转码
- 自定义menu
- Simsimi和Gimi Talk:聊天机器人还能火多久
- vb.net 向Excel模板中填充数据


