python实现支持unicode中文的AC自动机
来源:互联网 发布:大卫罗宾逊体测数据 编辑:程序博客网 时间:2024/04/30 07:57
最近开始从分析数据,要从大量短文本中匹配很多关键字,如果暴力find的话,发现CPU成为了瓶颈,于是想到了AC自动机
AC自动机是多模式匹配的一个经典数据结构,原理是和KMP一样的构造fail指针,不过AC自动机是在Trie树上构造的,但原理是一样的。
为了能够匹配unicode,我讲unicode编码之后,按照每4位进行索引,变成了16叉trie树。
其实这种事情应该用C/C++来写的,不过我不太会使用python调用c,所以就用python改写了
下面是代码
#coding=utf-8KIND = 16#BASE = ord('a')class Node(): static = 0 def __init__(self): self.fail = None self.next = [None]*KIND self.end = False self.word = None Node.static += 1class AcAutomation(): def __init__(self): self.root = Node() self.queue = [] def getIndex(self,char): return ord(char)# - BASE def insert(self,string): p = self.root for char in string: index = self.getIndex(char) if p.next[index] == None: p.next[index] = Node() p = p.next[index] p.end = True p.word = string def build_automation(self): self.root.fail = None self.queue.append(self.root) while len(self.queue)!=0: parent = self.queue[0] self.queue.pop(0) for i,child in enumerate(parent.next): if child == None:continue if parent == self.root: child.fail = self.root else: failp = parent.fail while failp != None: if failp.next[i] != None: child.fail = failp.next[i] break failp = failp.fail if failp==None: child.fail=self.root self.queue.append(child) def matchOne(self,string): p = self.root for char in string: index = self.getIndex(char) while p.next[index]==None and p!=self.root: p=p.fail if p.next[index]==None:p=self.root else: p=p.next[index] if p.end:return True,p.word return False,None class UnicodeAcAutomation(): def __init__(self,encoding='utf-8'): self.ac = AcAutomation() self.encoding = encoding def getAcString(self,string): string = bytearray(string.encode(self.encoding)) ac_string = '' for byte in string: ac_string += chr(byte%16) ac_string += chr(byte/16) #print ac_string return ac_string def insert(self,string): if type(string) != unicode: raise Exception('UnicodeAcAutomation:: insert type not unicode') ac_string = self.getAcString(string) self.ac.insert(ac_string) def build_automation(self): self.ac.build_automation() def matchOne(self,string): if type(string) != unicode: raise Exception('UnicodeAcAutomation:: insert type not unicode') ac_string = self.getAcString(string) retcode,ret = self.ac.matchOne(ac_string) if ret!=None: s = '' for i in range(len(ret)/2): s += chr(ord(ret[2*i])+ord(ret[2*i+1])*16) ret = s.decode('utf-8') return retcode,ret def main2(): ac = UnicodeAcAutomation() ac.insert(u'丁亚光') ac.insert(u'好吃的') ac.insert(u'好玩的') ac.build_automation() print ac.matchOne(u'hi,丁亚光在干啥') print ac.matchOne(u'ab') print ac.matchOne(u'不能吃饭啊') print ac.matchOne(u'饭很好吃,有很多好好的吃的,') print ac.matchOne(u'有很多好玩的')if __name__ == '__main__': main2() 下面是测试结果
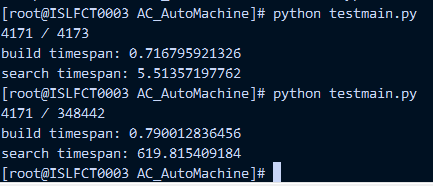
关键词数是2000,长度2-12
文本长度为60-80,分别测试4000条文本和300000条文本的速度
速度分别为 5.5s 和 619.8s
如下图,挺不错的
- python实现支持unicode中文的AC自动机
- AC自动机的实现原理
- python的unicode支持
- Python 的Unicode 支持
- 双数组AC自动机(doubleArrayTrie)的实现
- 【AC自动机】:Aho-Corasick算法的实现
- AC自动机的一种简单实现
- B00014 C++实现的AC自动机
- AC自动机的简单Java实现
- AC自动机的一种简单实现
- AC自动机代码实现
- AC自动机实现
- Python3实现AC自动机
- AC自动机的学习
- AC自动机算法实现详解
- AC自动机理论与实现
- AC自动机-一般算法实现
- 多模式匹配算法:AC自动机的C++实现
- MyEclipse安装插件的几种方法
- 椭圆的生成算法
- 用netcat搭建简单web服务器
- linux查看文件数
- MTK层相关应用集合
- python实现支持unicode中文的AC自动机
- JAVA程序员必看的15本书
- Webview离线功能(优先cache缓存+cache缓存管理)
- Unable to determine name from existing gemspec
- GetPrivateProfileString的问题,获得的CString结构有问题,高手指点
- MMI启动过程:
- SQLmap工具介绍及其使用
- 圆生成算法
- MTK相关常识


