XFS文件系统结构分析-XFS数据恢复篇
来源:互联网 发布:生辰八字 知乎 编辑:程序博客网 时间:2024/05/16 05:52
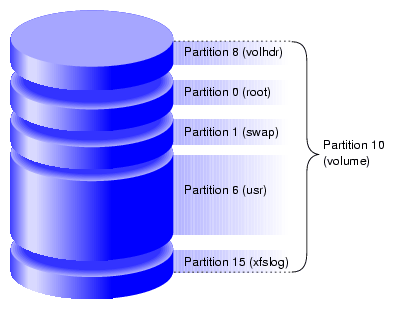
XFS文件系统上的数据恢复可麻烦多了。目前市面上没有基于XFS的数据恢复软件,跨平台的XFS读取软件只有XFS32,但功能非常有限,而且只限于目录、节点是正常的情况。据我对其源代码的分析,读取效率也是比较低的。SGI官方对于XFS的详细结构层的描述极少,有的只是FOR LINUX的源代码。这样对于XFS文件系统损坏,使用XFS REPAIR又无法修复的情况,就很麻烦了。
经过一段时间的研究,总算差不多搞清楚了XFS文件系统的结构层。如果有基于XFS的NAS或LINUX数据出现问题,应该有很大把握了。基于XFS数据恢复的软件已经接近完工。
飞客技术部研究心得:
XFS INODE number:变长的位数表示,三部分组成:起始块组号+起始块号+块内INODE号。起始块号与块内INODE号的位长由SUPERBLOCK中参数指定。
XFS EXT number:变长的位数表示,对于32位系统版本,首先用4个4字节表示EXT 编号,EXT编号由两部分组成:起始位置和大小。EXT编号的起始位置为L1(0-32)连接L2(0-32)连接L3(31-21)构成中间值(暂定为TEMP)然后TEMP又由两部分组成:块组号与块组内部块号,结构为后agblklog位表示内部块号,其余高位表示块组号。
XFS 设计:
分配组(allocation groups)
当创建 XFS 文件系统时,底层块设备被分割成八个或更多个大小相等的线性区域(region)。您可以将它们想象成“块”(chunk)或者“线性范围(range)”,但是在 XFS 术语中,每个区域称为一个“分配组”。分配组是唯一的,因为每个分配组管理自己的索引节点(inode)和空闲空间,实际上,是将这些分配组转化为一种文件子系统,这些子系统正确地透明存在于 XFS 文件系统内。 分配组与可伸缩性 那么,XFS 到底为什么要有分配组呢?主要原因是,XFS 使用分配组,以便能有效地处理并行 IO。因为,每个分配组实际上是一个独立实体,所以内核可以 同时与多个分配组交互。如果不使用分配组,XFS 文件系统代码可能成为一种性能瓶颈,迫使大量需求 IO 的进程“排队”来使索引节点进行修改或执行其它种类的元数据密集操作。多亏了分配组,XFS 代码将允许多个线程和进程持续以并行方式运行,即使它们中的许多线程和进程正在同一文件系统上执行大规模 IO 操作。因此,将 XFS 与某些高端硬件相结合,您将获得高端性能而不会使文件系统成为瓶颈。分配组还有助于在多处理器系统上优化并行 IO 性能,因为可以同时有多个元数据更新处于“在传输中”。 B+ 树无处不在 分配组在内部使用高效的 B+ 树来跟踪主要数据,譬如空闲空间的范围和索引节点。实际上,每个分配组使用 两棵 B+ 树来跟踪空闲空间;一棵树按空闲空间的大小排序来存储空闲空间的范围,另一棵树按块设备上起始物理位置的排序来存储这些区域。XFS 擅长于迅速发现空闲空间区域,这种能力对于最大化写性能很关键。 当对索引节点进行管理时,XFS 也是很有效的。每个分配组在需要时以 64 个索引节点为一组来分配它们。每个分配组通过使用 B+ 树来跟踪自己的索引节点,该 B+ 树记录着特定索引节点号在磁盘上的位置。您会发现 XFS 之所以尽可能多地使用 B+ 树,原因在于 B+ 树的优越性能和极大的可扩展性。
日志记录
当然,XFS 也是一种日志记录文件系统,它允许意外重新引导后的快速恢复。象 ReiserFS 一样,XFS 使用逻辑日志;即,它不象 ext3 那样将文字文件系统块记录到日志,而是使用一种高效的磁盘格式来记录元数据的变动。就 XFS 而言,逻辑日志记录是很适合的;在高端硬件上,日志经常是整个文件系统中争用最多的资源。通过使用节省空间的逻辑日志记录,可以将对日志的争用降至最小。另外,XFS 允许将日志存储在另一个块设备上,例如,另一个磁盘上的一个分区。这个特性很有用,它进一步改进了 XFS 文件系统的性能。 象 ReiserFS 一样,XFS 只对元数据进行日志记录,并且在写元数据之前,XFS 不采取任何专门的预防措施来确保将数据保存到磁盘。这意味着,使用 XFS(就象使用 ReiserFS)时,如果发生意外的重新引导,则最近修改的数据有可能丢失。然而,XFS 日志有两个特性使得这个问题不象使用 ReiserFS 时那么常见。 使用 ReiserFS 时,意外重新引导可能导致最近修改的文件中包含先前删除文件的部分内容。除了数据丢失这个显而易见的问题以外,理论上,这还可能引起安全性威胁。相反,当 XFS 日志系统重新启动时,XFS 确保任何未写入的数据块在重新引导时 置零。因此,丢失块由空字节来填充,这消除了安全性漏洞 ― 这是一种好得多的方法。 现在,关于数据丢失问题本身,该怎么办呢?通常,使用 XFS 时,该问题被最小化了,原因在于以下事实:XFS 通常比 ReiserFS 更频繁地将暂挂元数据更新写到磁盘,尤其是在磁盘高频率活动期间。因此,如果发生死锁,那么,最近元数据修改的丢失,通常比使用 ReiserFS 时要少。当然,这不能彻底解决不及时写数据块的问题,但是,更频繁地写元数据也确实促进了更频繁地写数据。
- XFS文件系统结构分析-XFS数据恢复篇
- XFS文件系统数据恢复实战
- XFS文件系统
- Linux xfs 文件系统备份与恢复
- xfs文件系统的备份与恢复
- xfs文件系统的备份和恢复
- RH436之XFS文件系统
- XFS文件系统碎片整理
- centos6构建XFS文件系统
- 修复xfs文件系统问题
- xfs文件系统修复方法
- linux-文件系统管理07-备份恢复xfs系统
- Linux日志文件系统(EXT4、XFS、JFS)及性能分析
- Linux日志文件系统(EXT4、XFS、JFS)及性能分析
- Linux日志文件系统(EXT4、XFS、JFS)及性能分析
- XFS文件系统简介(xfs_info观察相关数据)
- XFS 文件系统 mount 参数翻译
- opensuse13.2 xfs文件系统修复
- JSP tag 学习
- Java程序员面试中的多线程问题
- WOSA/XFS结构、背景等介绍
- php加速 PHP APC 浅析
- Maven 小结I
- XFS文件系统结构分析-XFS数据恢复篇
- GBK转UTF-8
- Python - 将window 窗口操作过程包装成脚本函数可被调用
- 关于优化&架构设计选择
- spring中的spel表达式语言
- 【2012百度之星/资格赛】G:聊天就是Repeat
- GNU C 、ANSI C、标准C、标准c++的区别和联系
- 64位linux下inet_ntoa()返回值竟然为int,printf报段错误
- 工作积累之Mediator 模式的理解


