android 显示系统
来源:互联网 发布:尼尔机械纪元官方优化 编辑:程序博客网 时间:2024/04/27 14:18
ICS Overlay主要流程
ICS Overlay主要流程
只关注到Overlay的主要过程,对FB未做分析,待以后完善。

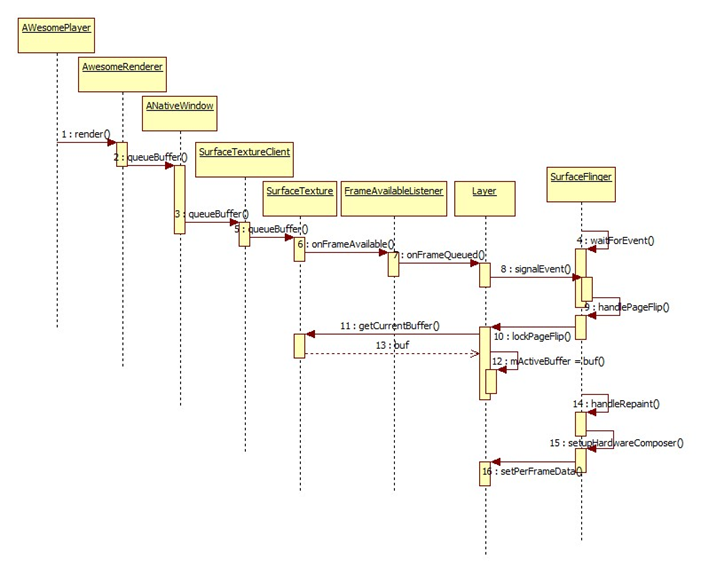
Figure 1queueBuffer流程
1. 在AWesomePlayer的Render中将解码后的Buf通过ANativeWindow接口通知SurfaceTextureClient
struct AwesomeNativeWindowRenderer : public AwesomeRenderer {
virtual void render(MediaBuffer *buffer) {
int64_t timeUs;
CHECK(buffer->meta_data()->findInt64(kKeyTime, &timeUs));
native_window_set_buffers_timestamp(mNativeWindow.get(), timeUs * 1000);
status_t err = mNativeWindow->queueBuffer(
mNativeWindow.get(), buffer->graphicBuffer().get());
}
}
进入到SurfaceTextureClient的queueBuffer(),这里的工作主要有:
1) 更新timestamp,如果没有,则用系统时间
2) 根据Buffer地址从slots中取出Buffer的序号
3) 将序号以及时间戳、以及其它信息通过Binder通信发送给SurfaceTexture。
int SurfaceTextureClient::queueBuffer(android_native_buffer_t* buffer) {
LOGV("SurfaceTextureClient::queueBuffer");
Mutex::Autolock lock(mMutex);
int64_t timestamp;
if (mTimestamp == NATIVE_WINDOW_TIMESTAMP_AUTO) {
timestamp = systemTime(SYSTEM_TIME_MONOTONIC);
LOGV("SurfaceTextureClient::queueBuffer making up timestamp: %.2f ms",
timestamp / 1000000.f);
} else {
timestamp= mTimestamp;
}
int i = getSlotFromBufferLocked(buffer);
status_t err = mSurfaceTexture->queueBuffer(i,timestamp,
&mDefaultWidth, &mDefaultHeight, &mTransformHint);
return err;
}
2. 在SurfaceFlinger进程中,本地端的SurfaceTexture接收到Binder消息,并进入queueBuffer函数。主要做以下工作:
1) 根据传入的int buf从slots中找出相应的Buffer,并更新此buffer的相关信息。
2)发信号mDequeueCondition.signal(),用作通知等待者
3) 通知监听者,onFrameAvailable有帧到达
status_t SurfaceTexture::queueBuffer(intbuf, int64_t timestamp,
uint32_t* outWidth, uint32_t* outHeight, uint32_t* outTransform) {
ST_LOGV("queueBuffer: slot=%d time=%lld", buf, timestamp);
sp<FrameAvailableListener> listener;
{ // scope for the lock
Mutex::Autolock lock(mMutex);
//一些参数检查
if (mSynchronousMode) {
// In synchronous mode we queue all buffers in a FIFO.
mQueue.push_back(buf);
// Synchronous mode always signals that an additional frame should
// be consumed.
listener = mFrameAvailableListener;
} else {
// In asynchronous mode we only keep the most recent buffer.
if (mQueue.empty()) {
mQueue.push_back(buf);
// Asynchronous mode only signals that a frame should be
// consumed if no previous frame was pending. If a frame were
// pending then the consumer would have already been notified.
listener = mFrameAvailableListener;
} else {
Fifo::iterator front(mQueue.begin());
// buffer currently queued is freed
mSlots[*front].mBufferState = BufferSlot::FREE;
// and we record the new buffer index in the queued list
*front = buf;
}
}
mSlots[buf].mBufferState = BufferSlot::QUEUED;
mSlots[buf].mCrop = mNextCrop;
mSlots[buf].mTransform = mNextTransform;
mSlots[buf].mScalingMode = mNextScalingMode;
mSlots[buf].mTimestamp = timestamp;
mFrameCounter++;
mSlots[buf].mFrameNumber = mFrameCounter;
mDequeueCondition.signal();
*outWidth = mDefaultWidth;
*outHeight = mDefaultHeight;
*outTransform = 0;
} // scope for the lock
// call back without lock held
if (listener != 0) {
listener->onFrameAvailable();
}
return OK;
}
在Layer中,第一次引用时会创建SurfaceTexture,并实现FrameAvailableListener
void Layer::onFirstRef()
{
LayerBaseClient::onFirstRef();
struct FrameQueuedListener : public SurfaceTexture::FrameAvailableListener {
FrameQueuedListener(Layer* layer) : mLayer(layer) { }
private:
wp<Layer> mLayer;
virtual void onFrameAvailable() {
sp<Layer> that(mLayer.promote());
if (that != 0) {
that->onFrameQueued();
}
}
};
mSurfaceTexture = new SurfaceTextureLayer(mTextureName, this);
mSurfaceTexture->setFrameAvailableListener(newFrameQueuedListener(this));
mSurfaceTexture->setSynchronousMode(true);
mSurfaceTexture->setBufferCountServer(2);
}
控制流进入Layer:onFrameQueued()函数,最后调用SurfaceFlinger的事件函数,通知其新事件。
void Layer::onFrameQueued() {
android_atomic_inc(&mQueuedFrames);
mFlinger->signalEvent();
}
3. 在SurfaceFlinger中获得事件,进入主循环处理事件
bool SurfaceFlinger::threadLoop()
{
waitForEvent();
// post surfaces (if needed)
handlePageFlip();//设置刚入队的Buffer为当前激活的Buffer
handleRepaint();//将当前激活的Buffer地址送给硬件叠加层,进行叠加
在lockPageFlip函数中遍历每一层设置当前激活的Buffer
bool SurfaceFlinger::lockPageFlip(const LayerVector& currentLayers)
{
bool recomputeVisibleRegions = false;
size_t count = currentLayers.size();
sp<LayerBase> const* layers = currentLayers.array();
for (size_t i=0 ; i<count ; i++) {
const sp<LayerBase>& layer(layers[i]);
layer->lockPageFlip(recomputeVisibleRegions);
}
return recomputeVisibleRegions;
}
对每个Layer将当前Buffer设置为激活Buffer
void Layer::lockPageFlip(bool& recomputeVisibleRegions)
{
// update the active buffer
mActiveBuffer= mSurfaceTexture->getCurrentBuffer();
在handleRepaint()中调用setupHardwareComposer建立叠加层
setupHardwareComposer(mDirtyRegion);
void SurfaceFlinger::setupHardwareComposer(Region& dirtyInOut)
{
/*
* update the per-frame h/w composer data for each layer
* and build the transparent region of the FB
*/
for (size_t i=0 ; i<count ; i++) {
const sp<LayerBase>& layer(layers[i]);
layer->setPerFrameData(&cur[i]);
}
}
将当前激活的buffer设置到 handware composer中进行叠加
void Layer::setPerFrameData(hwc_layer_t* hwcl) {
const sp<GraphicBuffer>& buffer(mActiveBuffer);
if (buffer == NULL) {
// this can happen if the client never drew into this layer yet,
// or if we ran out of memory. In that case, don't let
// HWC handle it.
hwcl->flags |= HWC_SKIP_LAYER;
hwcl->handle = NULL;
} else {
hwcl->handle = buffer->handle;
}
}
OpenMax图示
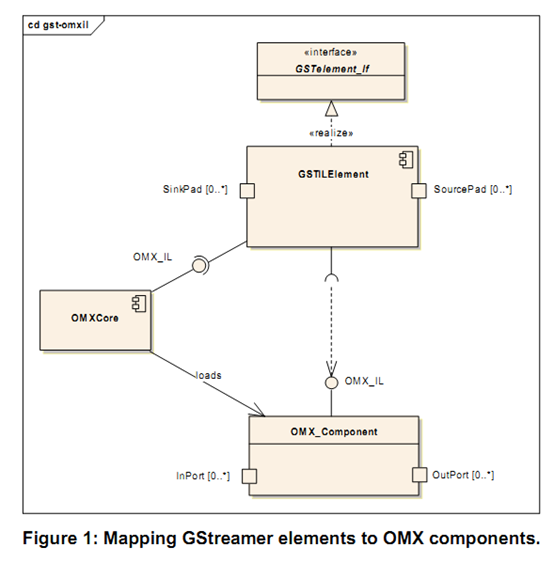
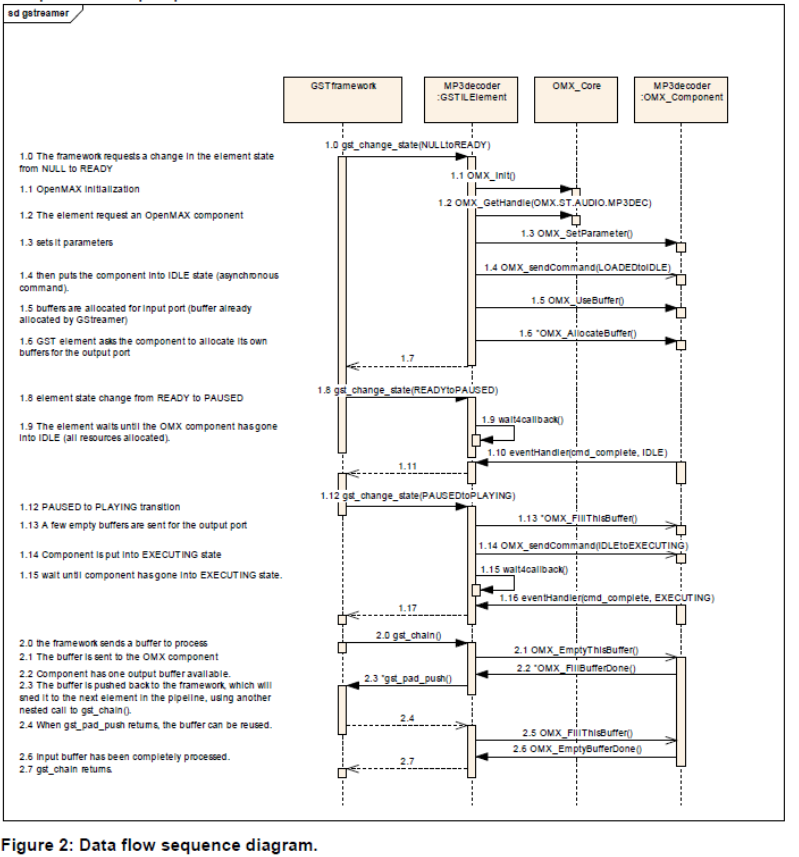
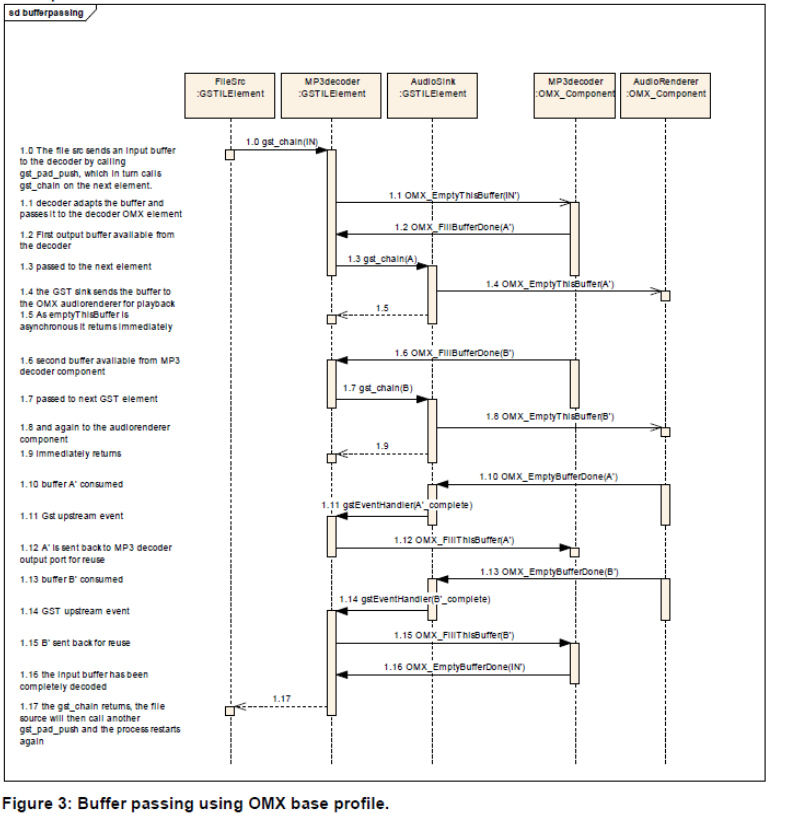
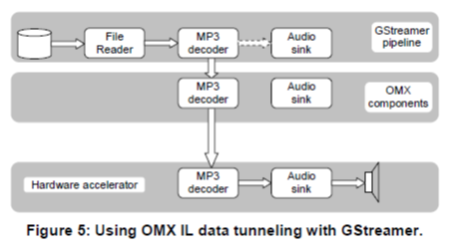
http://www.khronos.org/files/openmax/whitepapers/OpenMAX_IL_with_GSstreamer.pdf
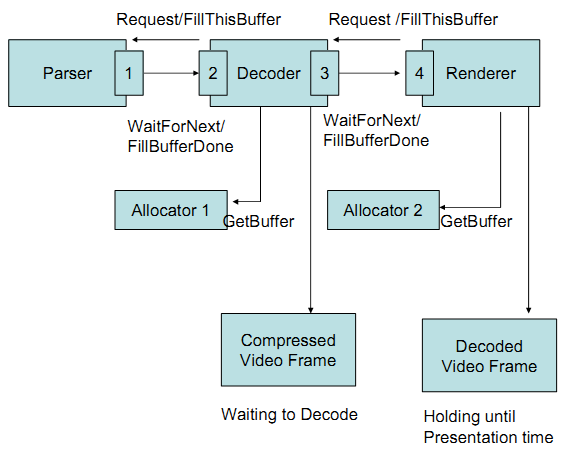
http://www.khronos.org/files/openmax/whitepapers/OpenMAX_IL_Dshow_Filter_integration.pdf
Introduction to the Gstreamer System Architecture
In my last post I wrote some different things about VLC, which I wanted to use for streaming purposes. I had to investigate what library it used. Actually, there is one library called "LIVE 555 streaming media" which the cone, VLC, is using.
Really, it was very difficult for me to find information for getting started.
For this reason, it was proposed to me, to investigate a bit about another low-level library called Gstreamer and written in C, for streaming and playing multimedia, which is used in several applications.
The first impression was really good. There is a first manual in which you can learn the basic features of Gstreamer, how to initialize it, how to put it in different state, what is a pipeline, what is an element, and finally a OGG player, as a "Hello World" application to apply the concepts already learnt.
As a result of my investigation, I'm going to summarize what I've learnt in this Gstreamer Manual.
The main use of Gstreamer is to manage the video and audio stream to create, for example, a video player, or a streaming server.
An element is the most important class of objects in Gstreamer. Usually, a functionality is achieved by linking elements.
Normally, inside the elements, there are pads, which are inputs and outputs. The input pad is called "sink" and is from where data flows trough the element, for example, from a local file, or from another element. The output pad, is called "source".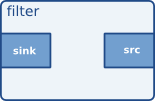 Here we can see an example of an elements with two pads. An input pad, and an output pad.
Here we can see an example of an elements with two pads. An input pad, and an output pad.
This is an element called filter, with input and output pads.
Besides elements, there is a kind of container called bin, which would be the parent of some elements. And then, there is a type of bin, calledpipeline.
This is a hierarchical structure for one important reason. A medium-sized project with gstreamer will contain a lot of elements, imagine that you want to put the "play" state. You should tell to each element. This method allows you to tell the command to the pipeline and it will advise all its elements.
There are also buses and message reporting functionalities which I'm not going to explain in this post because it will be too long.
Finally, as an exemple of the above explained, we have the first "hello world" application, which is an audio player of the Vorbis encoded content in an OGG file.

In the next posts I'm going to explain how it functions by putting snippets of code, and extending a little bit more the bus and message functionalities.
gstreamer介绍
Rainbow编码器是基于gstreamer实现的,webkit的video标签使用了gstreamer,gstreamer项目里还有一个rtsp的服务器,gstreamer的应用越来越多,而且它的确是一个不错的东西。
最近有几次需要向人家解释gstreamer,发现这样一些观点:gstreamer比vlc差远了;下载gstreamer编译后就是一个播放器等等,这些都是对于gstreamer不理解造成的。为了理解gstreamer,我们先来看看directshow。
DirectShow(有时缩写如 DS 或 DShow),开发代号 Quartz ,是一种由微软公司开发的能够让软件开发者对媒体文件执行各种不同处理的应用程序设计接口。它是微软公司对早先 Windows视频科技的一次更新。基于微软公司 Windows 组件对象模型(COM)框架,DirectShow为大部份微软公司程序设计语言提供了一个媒体的普遍接口,而且是一个可扩展的,能在使用者或开发者的命令下播放或记录媒体文件的,以Filter为基础的框架。DirectShow 开发工具及凭证被加入到微软公司 SDK 平台的一部份。Windows Media Player 这样的应用程序运用 DirectShow 或者它的各种衍生来播放来自文件或是互联网上的内容。DirectShow's 的最大的竞争对手是苹果计算机的QuickTime 框架。
以上内容是从http://zh.wikipedia.org/zh/DirectShow贴过来的,也就是维基百科。directshow和gstreamer有什么关系吗?当然有,我们可以把gstreamer理解成linux下的directshow。
在Wikimedia中,对于gstreamer是这样描述的:
GStreamer is a pipeline-based multimedia framework written in the C programming language with the type system based on GObject.
GStreamer是一个基于管道的多媒体框架,采用c语言开发,基于GObject。
Gstreamer基于GObject,是跨平台的,包括Linux (x86, PowerPC and ARM), Solaris (Intel and SPARC) and OpenSolaris, FreeBSD, OpenBSD, NetBSD, Mac OS X, Microsoft Windows and OS/400。gstreamer已经多种语言绑定,包括Python,Perl,Ruby等。
gstreamer通过把若干elements链接在一起构成pipeline实现对媒体内容的处理,element通过plug-in的方式提供。bin是一种特殊的element,是由多个其它elements组成的。
element之间通过pad进行数据通讯,一个element的源pad可以链接到另一个element的sink pad。pad之间的数据类型通过capability来协商。pipeline有多种状态,当处于playing状态的时候,数据buffer就从源pad向sink pad传送。
Gstreamer的核心实现了对plug-in的注册和加载等功能,plug-in是以动态库的形式存在的。当需要某个element的时候,Gstreamer就动态的加载对应的动态库。可以通过编写plug-in方式对gstreamer的功能进行扩展,包括编码方式,封装格式等各种功能。
来看看这张来自《GStreamer Application Development Manual》的图片: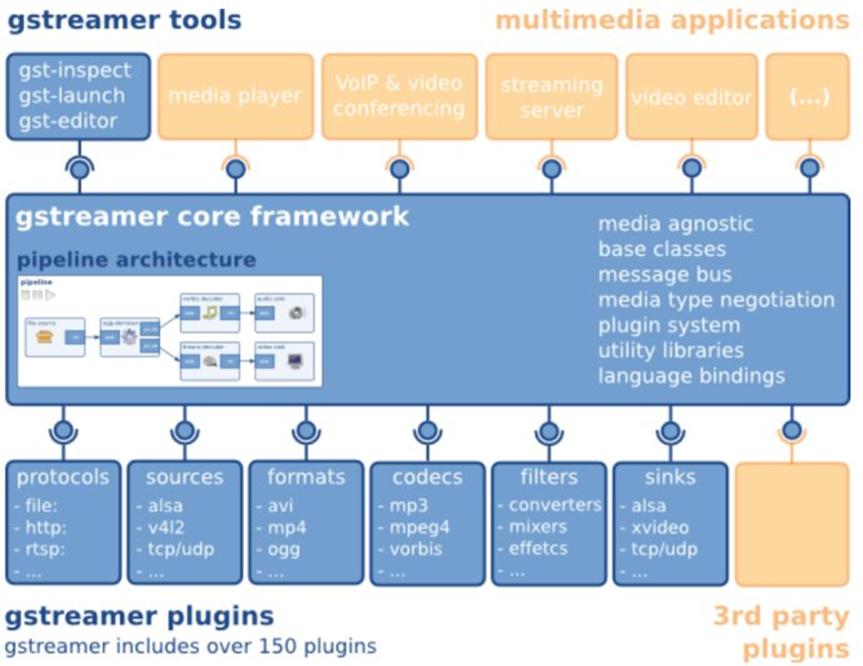
命令行调试工具
两个比较常用的工具是gst-inspect和gst-launch,用gst-inspect给出一个plugin或者element的信息,gst-launch用用于调试插件。
也可以直接用gst-launch来完成很多任务,但是如果要实现一个产品还是不要直接采用gst-launch。比如你想录制一个通过组播发送的视频流,就可以通过如下命令实现:
gst-launch udpsrc multicast-group=239.3.3.3 port=33333 ! filesink location=video.ts
下面给出一些有用的命令:
通过组播发送TS流
基于gstreamer的应用
首先是Webkit,Webkit在实现html5 video标签的支持的时候,采用了gstreamer。
Totem播放器
参考资料
主站点 http://www.gstreamer.org/
Wikipedia之Gstreamer词条 http://en.wikipedia.org/wiki/GStreamer
理解Gstreamer架构
本文给出了Gstreamer的总体设计。通过阅读本文可以了解Gstreamer的内部工作原理。本文编译自gstreamer源码中的文档,原文在源码中的位置是/gstreamer/docs/design/part-overview.txt。
概述
Gstreamer是一个libraries和plugins的集合,用于帮助实现各种类型的多媒体应用程序,比如播放器,转码工具,多媒体服务器等。
利用Gstreamer编写多媒体应用程序,就是利用elements构建一个pipeline。element是一个对多媒体流进行处理的object,比如如下的处理:
读取文件。
不同格式的编解码。
从硬件采集设备上采集数据。
在硬件设备上播放多媒体。
多个流的复用。
elements的输入叫做sink pads,输出叫做source pads。应用程序通过pad把element连接起来构成pipeline,如下图所示,其中顺着流的方向为downstream,相反方向是upstream。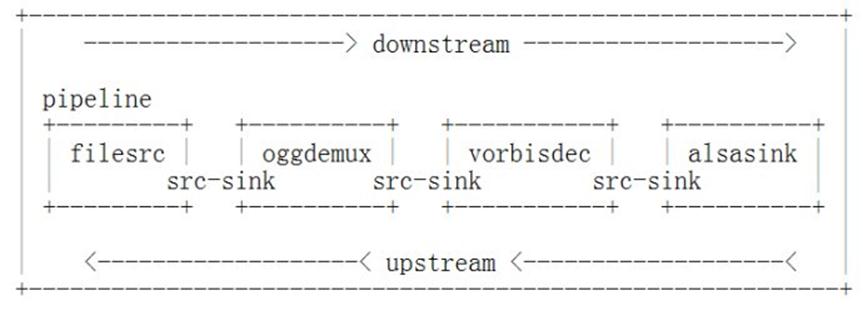
应用程序会收到来自pipeline的消息和通知,比如EOS等。
总体设计
Gstreamer的设计目标如下:
快速处理大规模数据。
对多线程处理的完全支持。
能处理各种格式的流媒体。
不同数据流的同步。
处理多种设备的能力。
基于Gstreamer的应用程序能够具备的处理能力依赖于系统中安装的不同种类功能的elements的数量。
Gstreamer核心不具备处理具体的media的功能,但是element处理media时需要具备的特性很多是由Gstreamer的核心提供的。
elements
element是pipeline的最小组成部分。element提供了多个pads,或者为sink,或者为source。一个element有四种可能的状态,分别是NULL,READY,PAUSED,PLAYING。NULL和READY状态下,element不对数据做任何处理,PLAYING状态对数据进行处理,PAUSE状态介于两者之间,对数据进行preroll。应用程序通过函数调用控制pipeline在不同状态之间进行转换。
element的状态变换不能跳过中间状态,比如不能从READY状态直接变换到PLAYING状态,必须经过中间的PAUSE状态。
element的状态转换成PAUSE会激活element的pad。首先是source pad被激活,然后是sink pad。pad被激活后会调用activate函数,有一些pad会启动一个Task。
PAUSE状态下,pipeline会进行数据的preroll,目的是为后续的PLAYING状态准备好数据,使得PLAYING启动的速度更快。一些element需接收到足够的数据才能完成向PAUSE状态的转变,sink pad只有在接收到第一个数据才能实现向PAUSE的状态转变。
通常情况下,element的状态转变需要协调一致。
可对element进行如下分类:
source,只提供数据源。
sink,比如播放设备。
transform
demuxer
muxer
Bin
bin是由多个element构成的特殊的element,用图来说明:
Pipeline
pipeline是具备如下特性的特殊的bin:
选择并管理一个全局的时钟。
基于选定的时钟管理running_time。running_time用于同步,指的是pipeline在PLAYING状态下花费的时间。
管理pipeline的延迟。
通过GstBus提供element与应用程序间的通讯方式。
管理elements的全局状态,比如EOS,Error等。
Dataflow and buffers
Gstreamer支持两种类型的数据流,分别是push模式和pull模式。在push模式下,upstream的element通过调用downstream的sink pads的函数实现数据的传送。在pull模式下,downstream的element通过调用upstream的source pads的函数实现对数据的请求。
push模式是常用的模式,pull模式一般用于demuxer或者低延迟的音频应用等。
在pads之间传送的数据封装在Buffer里,Buffer中有一个指向实际数据的指针以及一些metadata。metadata的内容包括:
timestamp
offset
duration
media type
其它
在push模式下,element通过调用gst_pad_push()函数把buffer传送给对应的pad。在pull模式下,element通过调用gst_pad_pull_range()函数把pull过来。
element在push buffer之前需要确认对应的element具备处理buffer中的数据类型的能力。在传说红之前首先查询对应的element能够处理的格式的种类,并从中选择合适的格式,通过gst_buffer_set_caps()函数对buffer进行设置,然后才传送数据。
收到一个buffer后,element要首先对buffer进行检查以确认是否能够处理。
可以调用gst_buffer_new()函数创建一个新的buffer,也可以调用gst_pad_alloc_buffer()函数申请一个可用的buffer。采用第二种方法接收数据的buffer可以设定接收其它类型的数据,这是通过对buffer的caps进行设定来实现的。
选择媒体类型并对buffer进行设定的处理过程叫做caps negotianation。
Caps
Caps,也就是媒体类型,采用key/value对的列表来描述。key是一个字符串类型,value的类型可能是int/float/string类型的single/list/range。
Data flow and events
除了数据流,还有events流。与数据流不同,events的传送方向既有downstream的,也有upstream的。
events用于传递EOS,flushing,seeking等消息。
有的events必须和data flow一起进行serialized。serialized的events比如TAG,非serialized的events比如FLUSH。
Pipeline construction
gst_pipeline_create()函数用于创建一个pipeline,gst_bin_add()函数用于向pipeline中添加element,gst_bin_remove()函数用于从pipeline中移除element。gst_element_get_pad()函数用于检索pipeline中的element。gst_pad_link()函数用于把pads连接在一起。
有的element会在数据流开始传送的时候创建新的pads,通过调用函数g_signal_connect()函数,能在新的pads被创建的时候接收到消息。
由于处理的数据互相不兼容,有的elements是不能被连接到一起的。gst_pad_get_caps()函数查询element能够处理的数据类型。
Pipeline clock
Pipeline的一个重要功能是为pipeline中的所有elements选择一个全局时钟。
时钟的作用是提供一个每秒为GST_SECOND的单调递增的时钟,单位是纳秒。element利用这个时钟时间来播放数据。
在pipeline被设为PLAYING之前,pipeline查询每一个element是否能提供clock,并按照如下次序来选择clock:
应用程序选择了一个clock。
如果source element提供了clock。
其它任何提供了clock的element。
选择一个默认的系统clock。
也有特殊的情况,比如存在音频sink提供了clock,那么就选择其提供的clock。
Pipeline states
完成了pads的链接和signals的链接,就可以设定pipeline为PAUSED状态启动数据流的处理。当bin(这里指的是pipeline)进行状态转换的时候要转换所有的children的状态,转换的次序是从sink element开始到source element结束,这样做的目的是为了确保upstream element提供数据的时候,downstream element已经准备好。
Pipeline status
Pipeline会通过bus向应用程序通报发生的events。bus是由pipeline提供的一个object,可以通过gst_pipeline_get_bus()函数取得。
bus分布到加入pipeline的每一个element。element利用bus来发布messages。有各种不同类型的messages,比如ERRORS,WARNINGS,EOS,STATE_CHANGED等。
pipeline以特殊的方式处理接收到的EOS message,只有当所有的sink element发送了EOS message的时候,pipeline才会把EOS发送给应用程序。
也可以通过gst_element_query()函数获取pipeline status,比如获取当前的位置或者播放的时间。
Pipeline EOS
当source filter遇上了流结束,会沿着downstream的方向向下一个element发送一个EOS的event,这个event依次传送给每一个element,接收到EOS event的element不再接收数据。
启动了线程的element发送了EOS event后就不再发送数据。
EOS event最终会到达sink element。sink element会发送一个EOS消息,通告流结束。pipeline在接收到EOS消息以后,把消息发送给应用程序。只有在PLAYING状态下会把EOS的消息传送给应用程序。
发送了EOS以后,pipeline保持PLAYING状态,等待应用程序把pipeline的状态置为PAUSE或者READY。应用程序也可以进行seek操作。
Gstreamer的同步机制
本文编译自gstreamer源代码中的文档,原文的路径是gstreamer/docs/design/part-synchronisation.txt。
本文描述了Gstreamer的同步机制,Gstreamer中实现同步的组件如下:
GstClock,是全局的,用于pipeline中的所有elements。
GstBuffer的timestamps。
buffers之前的NEW_SEGMENT event。
GstClock
GstClock是精确到纳秒的表示当前时间的一个计数。其值用absolute_time表示。这个计数的源的选择如下:
系统时间,精度是微妙。
音频设备。
基于网络的数据包,比如RTP数据包。
其它。
在Gstreamer中任何element都可以提供GstClock,pipeline从所有可用的GstClock中选定一个并用于pipeline中所有的elements。时间计数单调递增,可以不是从0开始计数。
Running time
选定了clock之后pipeline会维护一个基于选定时钟的running_time。running_time指的是pipeline处于PLAYING状态下的时间总和,计算方法如下:
如果pipeline处于NULL或者READY状态则running_time处于undefined。
PAUSE状态下,running_time的值保持不变,如果处于刚开始启动时的PAUSE状态,running_time的值为0。
flushing seek之后,running_time被置为0。这需要向所有被flush的elemnt指定一个新的base_time。
上述的计算方法在pipeline的状态从PLAYING状态设定为PAUSE状态时记录running_time,当从PAUSE状态转变为PLAYING状态后基于absolute_time恢复running_time。针对PAUSE后继续计数的clock,比如system clock,以及PAUSE后不再计数的clock,比如audioclock都是适用的。
running_time的计算方法如下:
C.running_time = absolute_time - base_time
Timestamps
GstBuffer的timestamps以及NEW_SEGMENT event定义了 buffer timestamps 到 running_time的变换
B: GstBuffer
B.timestamp = buffer timestamp (GST_BUFFER_TIMESTAMP)
NS: NEWSEGMENT event preceeding the buffers.
NS.start: start field in the NEWSEGMENT event
NS.stop: stop field in the NEWSEGMENT event
NS.rate: rate field of NEWSEGMENT event
NS.abs_rate: absolute value of rate field of NEWSEGMENT event
NS.time: time field in the NEWSEGMENT event
NS.accum: total accumulated time of all previous NEWSEGMENT events. This field is kept in the GstSegment structure.
符合同步要求的buffers其B.timestamp需在NS.start和NS.stop之间,B.timestamp不在这个范围内的buffers需要丢掉或者进行修正。
对于running_time存在如下变换:
if (NS.rate > 0.0)
B.running_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum
else
B.running_time = (NS.stop - B.timestamp) / NS.abs_rate + NS.accum
B.running_time由NEWSEGMENT event以及该segment的buffers得到。
可显示的第一个buffer的running_time的值为0。
对于 NS.rate > 1.0,timestamps的值缩小从而使得播放速度加快。
For negative rates, timestamps are received stop NS.stop to NS.start so that the first buffer received will be transformed into B.running_time of 0 (B.timestamp == NS.stop and NS.accum == 0).
Synchronisation
对于running_time的计算方法如下:
采用clock以及element的base_time:
C.running_time = absolute_time - base_time
采用buffer timestamp和其前面的NEWSEGMENT event,假定为正向播放:
B.running_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum
这里的前缀C.和B.代表不同的计算方法。
同步播放的目的就是确保running_time为B.running_time的buffer在C.running_time的时刻播放。
这需要满足如下条件:
B.running_time = C.running_time
也就是:
B.running_time = absolute_time - base_time
或者
absolute_time = B.running_time + base_time
具有B.running_time的buffer应当被播放时的absolute_time记为B.sync_time,那么:
B.sync_time = B.running_time + base_time
这意味着等到clock到了B.sync_time的时候才播放buffer,对于多个流中具有相同的running_time的buffer应该同时播放。
dumuxer必须确保向输出pads发出的NEWSEGMENT能为buffers生成一样的running_time,从而使之保持同步。通常向pads发出同样的NEWSEGMENT来确保同步的buffer具有一样的timestamp。
Stream time
stream time,也称作在流中的位置,是一个在0和媒体文件长度(时间)之间的值。具有如下用途:
report the POSITION query in the pipeline
the position used in seek events/queries
the position used to synchronize controller values
通过buffer和其前面的NEWSEGMENT event来计算stream time:
stream_time = (B.timestamp - NS.start) * NS.abs_applied_rate + NS.time
对于播放速度为负的情况,B.timestamp将从NS.stop 到 NS.start,使得stream time反向。在PLAYING 状态,也可以采用pipeline clock 计算当前的stream_time。 Give the two formulas above to match the clock times with buffer timestamps allows us to rewrite the above formula for stream_time (and for positive rates).
C.running_time = absolute_time - base_time
B.running_time = (B.timestamp - NS.start) / NS.abs_rate + NS.accum
=>
(B.timestamp - NS.start) / NS.abs_rate + NS.accum = absolute_time - base_time;
=>
(B.timestamp - NS.start) / NS.abs_rate = absolute_time - base_time - NS.accum;
=>
(B.timestamp - NS.start) = (absolute_time - base_time - NS.accum) * NS.abs_rate
filling (B.timestamp - NS.start) in the above formule for stream time
=>
stream_time = (absolute_time - base_time - NS.accum) * NS.abs_rate * NS.abs_applied_rate + NS.time
最后的计算公式通常是sink用于report当前的position的准确和有效的方式。Note that the stream time is never used for synchronisation against the clock.
gstreamer中的调度模式
编译自 GStreamer Plugin Writer's Guide - Chapter 11
操作系统需要进程调度的功能,人需要通过大脑进行复杂的调度工作一样,Gstreamer为了协调多个elements进行工作,也需要调度功能。在Gstreamer中,调度的任务就是调用pipeline中的每个element处理数据并为下一个element准备数据。
在gstreamer中有三种调度模式。第一种通过_chain()函数实现调度,采用这种调度模式的elements的sink pad都被设置了一个chain函数,并向souce pads推送buffer。第二种是随机访问的模式,这种调度方式基于_getrange()函数。第三种是task-runner模式,这种模式下,相应的element就是pipeline的"引擎"。
pad activation阶段
GStreamer决定采用何种调度模式的阶段叫做pad activation阶段。在这个阶段,GStreamer会通过scheduling capabilities来查询每一个element所支持的调度模式,并决定采用何种调度模式,然后把指定的调度模式notify给每一个pad,让pipeline以指定的调度模式开始运行。
Pads可被设定为三种调度模式之一,每一种模式对于pads有不同的要求。Pads需要实现一个通知函数,Gstreamer通过这个函数来设定Pads的调度模式。对于被设定为基于pull调度模式的sink pads还要启动自己的任务。
如果所有的elements被设定为基于push的调度模式,意味着通过chain函数,从upstream把数据push到下一个element。这要求每个element都要调用gst_pad_set_chain_function()对每一个sinkpad设定chain函数
可以通过设定pad工作在基于pull的调度模式,使之成为pipeline的"引擎"。
可以设定pipeline中所有的pads为基于push的调度模式。
Pads driving the pipeline
Sinkpads设定为基于pull的模式,所有的sourcepads都基于非pull的模式,这样的element可以启动一个任务来驱动pipeline的数据流。所有相关elements have random access over all of their sinkpads,并把数据push到sourcepads。这样的调度适合如下类型的elements:
Demuxer,parsers以及输入数据是unparsed的特定类型的decoders
特定类型的audio输出,这种类型的audio输出需要对输入数据进行控制,比如Jack sound server。
作为"引擎"任务需要在activation函数中创建:
#include "filter.h"
#include <string.h>
static gboolean gst_my_filter_activate (GstPad * pad);
static gboolean gst_my_filter_activate_pull (GstPad * pad, gboolean active);
static void gst_my_filter_loop (GstMyFilter * filter);
GST_BOILERPLATE (GstMyFilter, gst_my_filter, GstElement, GST_TYPE_ELEMENT);
static void
gst_my_filter_init (GstMyFilter * filter)
{
...
gst_pad_set_activate_function (filter->sinkpad, gst_my_filter_activate);
gst_pad_set_activatepull_function (filter->sinkpad, gst_my_filter_activate_pull);
...
}
...
static gboolean
gst_my_filter_activate (GstPad * pad)
{
if (gst_pad_check_pull_range (pad)) {
return gst_pad_activate_pull (pad, TRUE);
} else {
return FALSE;
}
}
static gboolean
gst_my_filter_activate_pull (GstPad *pad,gboolean active)
{
GstMyFilter *filter = GST_MY_FILTER (GST_OBJECT_PARENT (pad));
if (active) {
filter->offset = 0;
return gst_pad_start_task (pad,(GstTaskFunction) gst_my_filter_loop, filter);
} else {
return gst_pad_stop_task (pad);
}
}
启动后作为"引擎"的任务对输入和输出有完全的控制。最简单的"引擎"就是读取输入并将其push到sourcepads。这样的调度模式和仅仅有chain函数驱动的调度模式相比更加灵活。
#define BLOCKSIZE 2048
static void
gst_my_filter_loop (GstMyFilter * filter)
{
GstFlowReturn ret;
guint64 len;
GstFormat fmt = GST_FORMAT_BYTES;
GstBuffer *buf = NULL;
if (!gst_pad_query_duration (filter->sinkpad, &fmt, &len)) {
GST_DEBUG_OBJECT (filter, "failed to query duration, pausing");
goto stop;
}
if (filter->offset >= len) {
GST_DEBUG_OBJECT (filter, "at end of input, sending EOS, pausing");
gst_pad_push_event (filter->srcpad, gst_event_new_eos ());
goto stop;
}
ret = gst_pad_pull_range (filter->sinkpad, filter->offset,BLOCKSIZE, &buf);
if (ret != GST_FLOW_OK) {
GST_DEBUG_OBJECT (filter, "pull_range failed: %s", gst_flow_get_name (ret));
goto stop;
}
ret = gst_pad_push (filter->srcpad, buf);
buf = NULL;
if (ret != GST_FLOW_OK) {
GST_DEBUG_OBJECT (filter, "pad_push failed: %s", gst_flow_get_name (ret));
goto stop;
}
filter->offset += BLOCKSIZE;
return;
stop:
GST_DEBUG_OBJECT (filter, "pausing task");
gst_pad_pause_task (filter->sinkpad);
}
Providing random access
启动一个自己的进程来作为pipeline引擎的element需能够通过sinkpads进行随机访问,这意味着所有相连的element都应该具备随机访问的功能。elements通过gst_pad_pull_range()函数实现随机访问。sourcepads采用gst_pad_set_getrange_function()设定一个_get_range()函数,在_get_range()函数中支持随机访问。可实现随机访问的elements有:
Data sources,比如file sources,以极低的延迟访问文件中任意位置的数据。
Filters
Parsers
下面的例子给出了_get_range()函数的实现:


#include "filter.h"
static GstFlowReturn
gst_my_filter_get_range (GstPad * pad,
guint64 offset,
guint length,
GstBuffer ** buf);
GST_BOILERPLATE (GstMyFilter, gst_my_filter, GstElement, GST_TYPE_ELEMENT);
static void
gst_my_filter_init (GstMyFilter * filter)
{
GstElementClass *klass = GST_ELEMENT_GET_CLASS (filter);
filter->srcpad = gst_pad_new_from_template (
gst_element_class_get_pad_template (klass, "src"), "src");
gst_pad_set_getrange_function (filter->srcpad,
gst_my_filter_get_range);
gst_element_add_pad (GST_ELEMENT (filter), filter->srcpad);
...
}
static gboolean
gst_my_filter_get_range (GstPad * pad,
guint64 offset,
guint length,
GstBuffer ** buf)
{
GstMyFilter *filter = GST_MY_FILTER (GST_OBJECT_PARENT (pad));
[.. here, you would fill *buf ..]
return GST_FLOW_OK;
}
很多理论上可实现随机访问的elements在实际应用当中仅仅实现了基于push的调度模式,因为downstream elements都没有启动自己的任务。实际上应该实现_chain()和_get_range()两个函数,同时还要提供_activate_*()函数用于启动自己的任务,这样Gstreamer就可以选择最优的调度模式。
RefBase,Bp,Wp解析

- Android 显示系统
- Android 显示系统
- Android 显示系统
- Android的显示系统
- Android 显示系统
- android 显示系统
- Android 显示系统
- Android 显示系统
- android 4.0 显示系统
- Android 显示系统简介
- Android 显示系统简介
- android 显示系统
- Android GDI 显示系统
- 显示Android系统桌面
- android 显示系统架构
- Android显示系统Vsync
- Android 显示系统
- QCOM Android 显示系统
- Cocos2D 触摸分发原理
- Static Factory(静态工厂、简单工厂)
- httpunit使用示例
- Factory Method(工厂方法)
- 线程同步----事作(Event)
- android 显示系统
- Java 多线程同步
- Abstract Factory(抽象工厂)
- Builder(建造者)
- C++ 内存池 -- C++ Memory Pool
- Protoype(原型模式)
- 使用testNG进行并发性能测试
- C#入门经典学习1-C#简介
- apache与jetty整合,用mod_proxy


