两阶段提交-2PC
来源:互联网 发布:笔记本电脑怎么用淘宝 编辑:程序博客网 时间:2024/05/18 09:23
两阶段提交协议(two phase commit protocol,2PC)可以保证数据的强一致性,许多分布式关系型数据管理系统采用此协议来完成分布式事务。它是协调所有分布式原子事务参与者,并决定提交或取消(回滚)的分布式算法。同时也是解决一致性问题的一致性算法。该算法能够解决很多的临时性系统故障(包括进程、网络节点、通信等故障),被广泛地使用。但是,它并不能够通过配置来解决所有的故障,在某些情况下它还需要人为的参与才能解决问题。参与者为了能够从故障中恢复,它们都使用日志来记录协议的状态,虽然使用日志降低了性能但是节点能够从故障中恢复。
在两阶段提交协议中,系统一般包含两类机器(或节点):一类为协调者(coordinator),通常一个系统中只有一个;另一类为事务参与者(participants,cohorts或workers),一般包含多个,在数据存储系统中可以理解为数据副本的个数。协议中假设每个节点都会记录写前日志(write-ahead log)并持久性存储,即使节点发生故障日志也不会丢失。协议中同时假设节点不会发生永久性故障而且任意两个节点都可以互相通信。
当事务的最后一步完成之后,协调器执行协议,参与者根据本地事务能够成功完成回复同意提交事务或者回滚事务。
顾名思义,两阶段提交协议由两个阶段组成。
在正常的执行下,这两个阶段的执行过程如下所述:
阶段1:请求阶段(commit-requestphase,或称表决阶段,votingphase)
在请求阶段,协调者将通知事务参与者准备提交或取消事务,然后进入表决过程。在表决过程中,参与者将告知协调者自己的决策:同意(事务参与者本地作业执行成功)或取消(本地作业执行故障)。
阶段2:提交阶段(commitphase)
在该阶段,协调者将基于第一个阶段的投票结果进行决策:提交或取消。当且仅当所有的参与者同意提交事务协调者才通知所有的参与者提交事务,否则协调者将通知所有的参与者取消事务。参与者在接收到协调者发来的消息后将执行响应的操作。
两阶段提交协议最大的劣势是其通过阻塞完成的协议,在节点等待消息的时候处于阻塞状态,节点中其他进程则需要等待阻塞进程释放资源才能使用。如果协调器发生了故障,那么参与者将无法完成事务则一直等待下去。
以下情况可能会导致节点发生永久阻塞:
如果参与者发送同意提交消息给协调者,进程将阻塞直至收到协调器的提交或回滚的消息。如果协调器发生永久故障,参与者将一直等待,这里可以采用备份的协调器,所有参与者将回复发给备份协调器,由它承担协调器的功能。
如果协调器发送“请求提交”消息给参与者,它将被阻塞直到所有参与者回复了,如果某个参与者发生永久故障,那么协调器也不会一直阻塞,因为协调器在某一时间内还未收到某参与者的消息,那么它将通知其他参与者回滚事务。
同时两阶段提交协议没有容错机制,一个节点发生故障整个事务都要回滚,代价比较大。
(a verygood example)
下面我们通过一个例子来说明两阶段提交协议的工作过程:
A组织B、C和D三个人去爬长城:如果所有人都同意去爬长城,那么活动将举行;如果有一人不同意去爬长城,那么活动将取消。用2PC算法解决该问题的过程如下:
首先A将成为该活动的协调者,B、C和D将成为该活动的参与者。
阶段1:
A发邮件给B、C和D,提出下周三去爬山,问是否同意。那么此时A需要等待B、C和D的邮件。
B、C和D分别查看自己的日程安排表。B、C发现自己在当日没有活动安排,则发邮件告诉A它们同意下周三去爬长城。由于某种原因,D白天没有查看邮件。那么此时A、B和C均需要等待。到晚上的时候,D发现了A的邮件,然后查看日程安排,发现周三当天已经有别的安排,那么D回复A说活动取消吧。
阶段2:
此时A收到了所有活动参与者的邮件,并且A发现D下周三不能去爬山。那么A将发邮件通知B、C和D,下周三爬长城活动取消。
此时B、C回复A“太可惜了”,D回复A“不好意思”。至此该事务终止。
通过该例子可以发现,2PC协议存在明显的问题。假如D一直不能回复邮件,那么A、B和C将不得不处于一直等待的状态。并且B和C所持有的资源,即下周三不能安排其它活动,一直不能释放。其它等待该资源释放的活动也将不得不处于等待状态。
基于此,后来有人提出了三阶段提交协议,在其中引入超时的机制(2阶段提交协议的变种协议中也有相应的超时机制),将阶段1分解为两个阶段:在超时发生以前,系统处于不确定阶段;在超市发生以后,系统则转入确定阶段。
2PC协议包含协调者和参与者,并且二者都有发生问题的可能性。假如协调者发生问题,我们可以选出另一个协调者来提交事务。例如,班长组织活动,如果班长生病了,我们可以请副班长来组织。如果协调者出问题,那么事务将不会取消。例如,班级活动希望每个人都能去,假如有一位同学不能去了,那么直接取消活动即可。或者,如果大多数人去的话那么活动如期举行(2PC变种)。为了能够更好地解决实际的问题,2PC协议存在很多的变种,例如:树形2PC协议(或称递归2PC协议)、动态2阶段提交协议(D2PC)等。
理想的时候:没有异常
此时,我们假设所有参与者、网络都不会出现异常,这种情况下2PC没有任何难度。
- 协调者向所有参与者发出VOTE_REQUEST请求,然后 协调者阻塞等待所有参与者的响应
- 参与者在收到VOTE_REQUEST的时候,执行事务预处理,根据预处理的结果响应协调者:VOTE_COMMIT或者VOTE_ABORT; 然后参与者等待协调者的最后决定(global_decision)
- 协调者等待所有的参与者的响应,如果所有参与者都响应VOTE_COMMIT,那么协调者就向所有参与者发出GLOBAL_COMMIT; 如果至少有一个参与者响应VOTE_ABORT,那么协调者就向所有参与者发出GLOBAL_ABORT
- 参与者根据协调者的决定(global_decision)在本地进行事务操作


在理想的时代,一切都是完美的,一切都是简单的。
协调者的状态转移图如下:
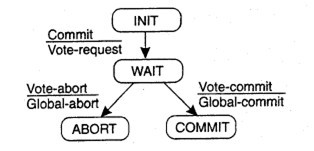
参与者的状态转移图如下:

次理想的时候:节点、网络异常会最终恢复
最糟糕的时候:协调者和参与者在死亡后无法恢复
2PC很无辜的看着大家,其实这个与我无关。听我详细道来。
本节的算法摘自《Distributed Systems: Principles and Paradigms》。
Actions of Coordinator
write("START_2PC tolocal log");
multicast("VOTE_REQUESTto all participants");
while(not all votes have been collected)
{
waitfor("any incoming vote");
if(timeout)
{
write("GLOBAL_ABORT to local host");
multicast("GLOBAL_ABORT to all participants");
exit();
}
record(vote);
}
if(all participants send VOTE_COMMIT and coordinatorvotes COMMIT)
{
write("GLOBAL_COMMIT to local log");
multicast("GLOBAL_COMMIT to all participants");
}
else
{
write("GLOBAL_ABORT to local log");
multicast("GLOBAL_ABORT to all participants");
}
Actions of Participantsdata/Main/TwoPhaseCommit.txt
write("INIT to locallog");
waitfor("VOTE_REQUESTfrom coordinator");
if(timeout)
{
write("VOTE_ABORT to local log");
exit();
}
if("participantvotes COMMIT")
{
write("VOTE_COMMIT to local log");
send("VOTE_COMMIT to coordinator");
waitfor("DESCISION from coordinator");
if(timeout)
{
multicast("DECISION_REQUEST to other participants");
waituntil("DECISION is received"); /// remain blocked
write("DECISION to local log");
}
if(DECISION == "GLOBAL_COMMIT")
{
write("GLOBAL_COMMIT to local log");
}
else if(DECISION== "GLOBAL_ABORT")
{
write("GLOBAL_ABORT to local log");
}
}
else
{
write("GLOBAL_ABORT to local log");
send("GLOBAL_ABORT to coordinator");
}
算法解析
2PC这个协议本身其实本不难,难的是很多人(包括我自己)在学习算法本身的时候会思考如何把他应用在实际系统上。是想,如果我们假设任何阶段coordinator或者participant出现异常,那么整个算法就停止在那个地方一直循环等待,直到退出的节点恢复,算法才继续往前走,这个算法其实一点难度都没有。但是每个人都会思考,这样的算法在实际过程中还有用吗?实际过程中 的工程师们是如何来处理这个问题的?只要一思考这些,读者就会觉得怎么都不对。其实就2PC而言,他本来就是一个阻塞的算法, 在所有participant都响应VOTE_REQUEST之后,在收到DECISION之前,coordinator宕机,那么算法就会一直阻塞,因为没有人 知道最后的decision是什么。既然它天生就是阻塞的,那么我们直接再弱化一下它好了,任何步骤主要出现异常,算法都阻塞。这样理解到的才是算法的实质。
可能有人会问,上面算法中有的地方在超时后会进行一些操作,然后算法可以继续;有些地方在超时后算法无法继续;这是为什么?什么时候决定算法可以继续,什么时候应该阻塞?以我对算法本身的理解,继续还是阻塞的标准是:
- 是否会导致事务的结果处于一种不一致的状态(一部分参与者commit,一部分参与者abort);如果不会出现不一致的情况, 那么算法可以继续;否则就必须阻塞。
可以这么理解:非阻塞的部分是算法的优化。算法继续,唯一会出现不一致状态的情况是,所有的参与者都响应了VOTE_REQUEST,在 任何参与者收到decision之前coordinator宕机死亡,此时所有参与者都必须等待coordinator恢复。
有个同事的观点:所有参与者(包括协调者)都必须通过多副本的方式保证自己的高可用性, 因为单副本不可用的问题不是2PC这个协议的目的,如果没有2PC这个协议,单副本的不可用性也是存在的,因此这种问题与2PC无关。可以说2PC本身不解决高可用性问题,它仅仅 解决的是atomic group commit的问题,这是2PC的假设,也是理解2PC的关键。一句话:每个协议解决自己的问题,不要带着你面临的 n个问题来理解2PC(包括其他分布式协议),这样只能使你自己陷入死角。
大家会说,那么每个协议如果这样去了解,岂不是都很简单,我作为架构师的最终目的是实现高可用的系统,而不是分开理解每个协议。呵呵,可以理解,我和大家一样由于这个想法走了很多的弯路。我会后续慢慢的告诉大家2PC如何在高可用的系统中使用。在分布式一致性这一系列文章中,我会为大家逐一解开谜底。
- Large-scale Incremental Processing Using Distributed Transactions and Notifications 看google如何使用2PC实现实时搜索,通过BigTable自身的高可用性解决解决participants的高可用性问题;通过乐观锁解决coordinator不具备高可用性的问题。看了这篇分析,你会发现前面我关于2PC的分析是正确的。
- Chubby一种可能的实现解析,看2PC如何与PAXOS结合实现replicated state machine,通过 分布式选举解决coordinator的高可用性问题,通过replicated state machine解决participants的高可用性问题。
分析对工程实践的指导
还是从同事那里讨论得到的:如果在分布式系统中,协议包括这种逻辑:A发起一个请求给所有人;等待所有人响应之后A继续进行处理。这样的东西一看就太复杂,不靠谱,因为这相当于实现了一个2PC,有些偏复杂,如果必须这么实现, 那么同学,你一定要按照2PC的理解方式去理解,去分析这个问题。
其实在分布式系统中,需要使用2pc思想指导设计的地方很多。一个很简单的例子,中心节点控制从一个数据节点拷贝一个分片到另外一个数据节点就需要这样的协议。以gfs增加block副本为例,当gfs metaserver的后台线程发现某个block的副本数量小于配置的阈值的时候,就会发起副本拷贝的任务:将block从一个chunkserver拷贝到另外一个chunkserver。这样的场景会产生如下问题:
- metaserver如何监控拷贝进度?
- 如果拷贝的源失败如何处理?
- 如果拷贝的目的失败如何处理?
一个比较挫的设计方法:meta不断的去询问源或者目的,任务是否结束,根据复制的结果决定如何进行后续的操作。想一想,这个实现起来有 多困难,metaserver上有上十万的block,如何处理?
看看伟大的google是如何处理的,metaserver为所有复制任务维护一个任务队列,任务队列中的任务有超时时间; 后台线程发现副本数量小于配置的阈值,首先查看任务队列中是否有任务正在进行该bock的复制操作,如果有任务 则不做任何事情;如果没有相应的任务,则发起任务。metaserver的工作到此为止。那么如何判断任务队列中的任务完成与否呢?这是chunkserver的事情,复制的目的会在复制任务完成后向metaserver汇报新复制的block, metaserver在收到复制完成的汇报后会把相应的任务从任务队列中删除。这样,整个协议很简单,很清晰,不易出bug。 之前那种挫的设计,状态太难维护。在我们实际的工程实践中,一定要尽量少的使用一个进程去等待另外两个进程 完成某项任务的协议,这样的协议太难维护了。
- 两阶段提交-2PC
- 两阶段提交-2PC
- 两阶段提交2PC
- 两阶段提交协议(2PC)
- 2PC 两阶段提交协议
- 2PC、XA、DTP与两阶段提交
- 2PC、XA、DTP与两阶段提交
- [Oracle] 分布式事务和两阶段提交(2PC)
- 两阶段提交协议,分布式事务控制(2PC)
- 2PC、XA、DTP与两阶段提交
- [Oracle] 分布式事务和两阶段提交(2PC)
- 分布式事务两阶段提交(2PC)的思考
- 《从Paxos到ZooKeeper》读书笔记--两阶段提交 2PC
- 两阶段提交(2PC)协议与XA事务处理
- [Oracle] 分布式事务和两阶段提交(2PC)
- 分布式事务和两阶段提交(2PC)
- 一分钟了解两阶段提交2PC
- 分布式事务、两阶段提交协议2PC、三阶提交协议3PC
- LDD3源码分析之ioctl操作
- C++语言复习六
- 如果可以后悔,世界会变成什么样
- toggle style menu contribution ,which is not persisted
- Cassandra1.1.0中Compaction部分源代码解析——准备篇
- 两阶段提交-2PC
- Fedora MP3播放
- POJ 1161并查集
- 从手机产品登录页面设计想到的
- 在VC下如何使用头文件unistd.h
- python-求在pi的方法 来自python cookbook上 just for fun
- C++模版编程——单链表的实现
- prototype.js 1.4版开发者手册(强烈推荐)
- Ruby学习之路——编程实践【1】 打印1到n的所有质数


