项目成本评估及预算的制定
来源:互联网 发布:ip网络广播终端 编辑:程序博客网 时间:2024/04/29 09:41
项目中成本评估中,最大的比例是进度评估,经常遇到我们的评估不准确,做了根本原因分析后如下图:
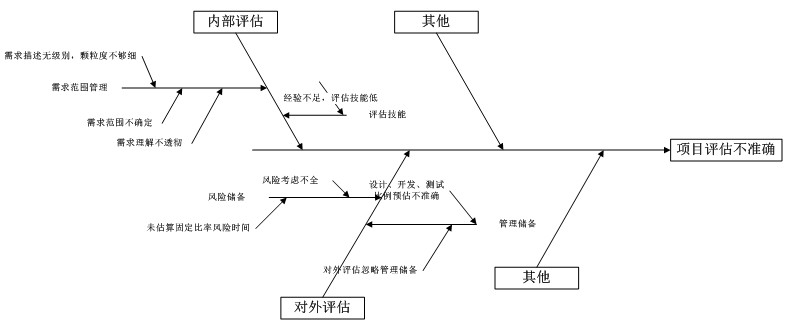
由上图我们得出,
占有大比例及优先级的原因如下:
1、 需求范围管理
2、 评估技能—而实际中这点并不是主要原因,评估者的多半经验都可满足评估标准
3、 风险储备
4、 管理储备
但并不是满足以上就让我们有个漂亮准确度高的成本评估指标,IT公司中,除了软件外包,很多公司忽略甲方,认为只有第三方才是甲方,如果一个运营类的公司,那么他的甲方实际上是这个公司的管理层,boss。
那么我们在每个项目中其实都遵循着软件外包的一个思路,就是我们需要两套“账本”,一套给“甲方”,一套给自己。也可以理解为一套为实际成本估算,另一套为预算(跟甲方报的价格)。
预算的组成流程:
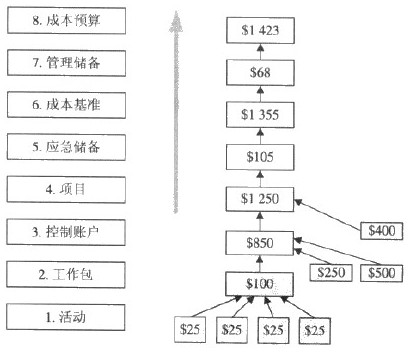
实际的预算制定过程中,也会根据企业类型、客户类型、项目类型的不同,以上节点未必需要全部具备。
我们自己的实际成本评估往往不可能非常准确,当我们把这套“账本”报给“甲方”时,必然出现延误,需求范围扩展等问题。
总结对内对外的必要估算组成部分,应按一定百分比进行评估。
调研
设计
开发
测试
管理
风险
配置
实施
其他
对外
√
√
√
√
√
√
√
√
忽略
对内
√
√
√
√
--
--
--
--
忽略
对日对国内的项目也不一样,但整体看都会是两套账本,并且根据企业级别(如能力成熟模型的级别)不同,对外部进行估算的标准也不同,即甲方能接受的评估依据不同,主要分为功能点估算和代码行估算。功能点估算用的方法多为类比,找具有资深开发经验和管理经验的人进行历史项目类比的方式进行估算,代码行估算的方式很多,多数采用自下而上的估算方式。
软件项目评估分两种类型,7钟场景。总结一下,国内项目基本都用的是功能点估算,按公司规模项目类型不同,选择不同的估算场景,能力成熟度比较高的公司,尤其在做对日项目的时候,用代码行估算的情况比较多,第一是因为甲方有需求,并且甲方有能力评估你估算的代码行对方是否接受,第二是这种估算需要在组织过程资产沉淀到一定基础上,有很多切合公司实际情况的参数时,才可以估算的准确。比如沉淀了公司的个人生产率,成本基准,功能点权重系数等等。
随着项目进展,评估会越来越准确,所以合同前的估算很粗,故要考虑的问题很多。
有些公司还会规定,将间接成本(需要进行项目和部门分摊的成本)纳入到项目成本中来。
下面我们开始说实际场景,之前看到篇文章总结的非常好,也符合实际,故这里不在赘述,做如下分享:
场景一:合同前的工作量估算
场景描述:
(1)没有实施过CMMI2级
(2)合同未签,需要给客户报价
(3)有客户的概要需求,有类似的项目数据可供参考
(4)需要估计整个项目的总工作量,以便于估算总成本,给客户报价
估算步骤:
(1)寻找类似的历史项目,进行项目的类比分析,根据历史项目的工作量凭经验估计本项目的总工作量;
(2)进行WBS分解,力所能及地将整个项目的任务进行分解;
(3)参考类似项目的数据,采用经验法估计WBS中每类活动的工作量;
(4)汇总得到项目的总工作量;
(5)与第(1)步的结果进行印证分析,根据分析结果,确定估计结果。
场景二:基于详细需求的经验估计
场景描述:
(1)只有详细需求,没有历史数据
估算步骤:
(1)WBS分解,将任务分解到一个人或者一个小团队可以执行的颗粒度;WBS分解时要识别出所有的交付物、项目管理活动、工程活动等。
(2)采用经验法估计每个活动的工作量;
(3)汇总得到:每个阶段的工作量、项目的总工作量。
其他说明:
在该场景下,只使用了经验法,无法对结果进行印证,难以判断结果的合理性。
、
场景三:由编码估算整体
场景描述:
(1)有类似项目的历史数据
(2)有编码活动的生产率数据
(3)有详细需求
(4)实施了CMMI2级,但是没有积累历史项目的工作量分布数据
估算步骤:
(1)产品分解,将系统分为子系统,子系统分解为模块;
(2)WBS分解,将任务分解到一个人或者一个小团队可以执行的颗粒度;WBS分解时要识别出所有的交付物、项目管理活动、工程活动等。
(3)建立WBS分解中的活动与产品元素的映射关系,识别出WBS中哪些活动可以采用模型法估算;
(4)估计产品元素的规模,可以采用代码行法或功能点法,并估计每个产品元素的复杂度、复用率等;
(5)根据历史的编码阶段的生产率数据和产品元素的规模估计、复杂度、复用率等采用模型法计算每个产品元素的编码工作量;
(6)根据历史的类似项目的数据及估算人的经验估计其他活动的工作量,可以采用经验法。
(7)汇总得到:每个阶段的工作量、项目的总工作量。
其他说明:
在该场景下,混合使用了经验法与模型法,这2种方法互相补充,而不是互相印证。
场景四:由总体印证基于WBS的估计
场景描述:
(1)有类似项目的历史数据
(2) 有类似项目的全生命周期的生产率数据(含管理工作量)
(3)有详细需求
(4)实施了CMMI2级,但是没有积累历史项目的工作量分布数据
估算步骤:
(1)产品分解,将系统分为子系统,子系统分解为模块;
(2)估计产品元素的规模,可以采用代码行法或功能点法;
(3)累计出整个产品的总规模,并估计产品总体的复杂度、复用率等;
(4)根据类似项目的全生命周期的生产率数据和产品的总规模、复杂度、复用率等采用模型法计算总的开发工作量;
(5)WBS分解,将任务分解到一个人或者一个小团队可以执行的颗粒度;WBS分解时要识别出所有的交付物、项目管理活动、工程活动等。
(6)根据历史的类似项目的数据及估算人的经验估计所有活动的工作量,可以采用经验法。
(7)汇总得到:每个阶段的工作量、项目的总工作量。
(8)与第(4)步得出的工作量进行比较印证,如果偏差不大,则以第(7)步的结果为准,如果偏差比较大,要仔细分析原
场景五:三维印证基于WBS的估计
场景描述:
(1)有类似项目的历史数据
(2) 有类似项目的全生命周期的生产率数据(含管理工作量)
(3)有详细需求
(4)实施了CMMI3级,有历史项目的工作量分布数据(阶段分布、工种分布)
估算步骤:
(1)产品分解,将系统分为子系统,子系统分解为模块;
(2)估计产品元素的规模,可以采用代码行法或功能点法;
(3)累计出整个产品的总规模,并估计产品总体的复杂度、复用率等;
(4)根据类似项目的全生命周期的生产率数据和产品的总规模、复杂度、复用率等采用模型法计算总的开发工作量;
(5)根据历史项目的工作量分布数据及第(4)步估算的项目总工作量
(6)WBS分解,将任务分解到一个人或者一个小团队可以执行的颗粒度;WBS分解时要识别出所有的交付物、项目管理活动、工程活动等。
(7)根据历史的类似项目的数据及估算人的经验估计所有活动的工作量,可以采用经验法。
(8)汇总得到:每个阶段的工作量、每个工种的工作量、项目的总工作量。
(9)与第(4)、(5)步得出的工作量进行比较印证,如果偏差不大,则以第(7)步的结果为准,如果偏差比较大,要仔细分析原因,可能的原因举例如下:
类似项目的生产率数据不适合本项目;
WBS分解的颗粒度不够详细;
估算专家的经验不适合本项目;
具体任务的估计不合理;
场景六:四维印证基于WBS的估计
场景描述:
(1)有类似项目的历史数据
(2) 有类似项目的编码活动的生产率数据(不含管理工作量)
(3)有详细需求
(4)实施了CMMI3级,有历史项目的工作量分布数据(阶段分布、工种分布、阶段工种分布)
(5)项目采用了瀑布模型
估算步骤:
(1)产品分解,将系统分为子系统,子系统分解为模块;
(2)估计产品元素的规模,可以采用代码行法或功能点法,并估计每个产品元素的复杂度、复用率等;
(3)根据类似项目的编码活动的生产率数据和产品元素的规模、复杂度、复用率等采用模型法计算每个产品元素的编码工作量;
(4)根据历史项目的按工种的工作量分布数据及第(3)步的估算的编码工作量依次计算:
i)根据历史项目的编码的工作量占编码阶段的工作量的百分比与第(3)部计算出的编码工作量计算编码阶段的总工作量;
ii)根据历史项目的编码阶段各工种的工作量分布百分比计算编码阶段每个工种的工作量;
iii)根据历史项目的其他阶段的工作量与编码阶段的工作量比例计算其他阶段的总工作量;
iv)根据历史项目的其他阶段的每个工种的工作量分布百分比及第iii)步的结果计算其他阶段的每个工种的工作量;
(5)WBS分解,将任务分解到一个人或者一个小团队可以执行的颗粒度;WBS分解时要识别出所有的交付物、项目管理活动、工程活动等。
(6)根据历史的类似项目的数据及估算人的经验估计所有活动的工作量,可以采用经验法。
(7)汇总得到:每个阶段每个工种的工作量、每个阶段的工作量、每个工种的工作量、项目的总工作量。
(8)与第(4)步得出的工作量进行比较印证,如果偏差不大,则以第(6)步的结果为准,如果偏差比较大,要仔细分析原因,可能的原因举例如下:
类似项目的生产率数据不适合本项目;
WBS分解的颗粒度不够详细;
估算专家的经验不适合本项目;
具体任务的估计不合理;
场景七:需求变更的工作量估计
场景描述:
(1)有变更的需求描述
(2)项目进行到了编码阶段
(3)有本项目的编码的生产率
估算步骤:
(1)进行需求变更的波及范围分析
(2)进行本次变更的的WBS分解
(3)对于变更引起的代码变化进行规模、复杂度等其他属性的估计
(4)根据本项目的编码的生产率及估计的规模采用模型法估计工作量
(5)对于WBS分解中其他活动进行经验估计
(6)汇总所有的工作量得到本次变更的工作量估计
以上的七种场景,在进行代码行估算的时候,一定要注意几点:
1、 组织过程资产是否有管理层认可的数据;比如功能点技术权重系数,比如模块代码复用率百分比,这些都归属于沉淀的参数估算。所以一般我们会将类比和参数估算结合。进行代码行估算时以上尤为重要,但功能点估算时也可进行统计,但多半更依赖于经验。
2、 对估算者的能力要求比较高;
3、 客户方认可代码行估算的能力;
4、 做好客户询问:XXX打印界面为什么估算了350行代码的回答。
尤其在生产制造业,行业规则固定,业务需求明确,一个做解决方案提供和实施顾问的企业,可以根据自身产品的沉淀,技术框架的沉淀,准确估算出一个功能点的代码行数
比如我们有统一的工具类程序包,统一的基本逻辑处理程序包。一个提交按钮的假设代码行产生是10行,一个文本框产生的代码量是10行,那么每调用一次check,衍生代码是可能也是10行,而这10行有复用率的标准。比如整个系统中凡是涉及到编号的文本框都复用。
我们可以发现,多半估算准确度高的都是瀑布式模型,而敏捷开发方法不利于项目估算,因为有很多工作流交叠,舍弃的雏形模块的删减,无法正确的计算出损失,并且过多的依赖于团队能力,个人素质,资产没有沉淀在数据、文本上,这恐怕也是多数互联网公司做敏捷宣传时很少提及到底节约了多少成本的原因。
完结。
- 项目成本评估及预算的制定
- 项目成本评估及预算的制定
- 【郭林专刊】项目成本评估及预算的制定
- 按日查看项目的预算成本和实际成本
- 使用资本预算确定项目成本
- 如何制定有效的年度营销预算
- 项目计划的制定及执行
- 软件开发成本构成及评估
- 第十三天:制定预算
- 一个开发周期为6个月的中小型软件开发项目成本预算大致表,不足之处请指点
- 一个开发周期为6个月的中小型软件开发项目成本预算大致表,不足之处请指点
- 一个开发周期为6个月的中小型软件开发项目成本预算大致表,不足之处请指点
- 一个开发周期为6个月的中小型软件开发项目成本预算大致表,不足之处请指点
- 一个开发周期为6个月的中小型软件开发项目成本预算大致表,不足之处请指点
- 成本中心预算查询
- 收入成本预算-历程
- 网站的成本收入应该怎么评估
- azure的弹性计算成本评估
- 用递归法实现一个十进制数据转换成二进制
- WOJ
- 在终端中打开各类文件的通用命令
- 腾讯抄你肿么办,致创业者或准创业者们!
- mysql中的unix_timestamp函数
- 项目成本评估及预算的制定
- Unix多线程编程技术
- 使用jQuery AJax 与 asp.net ashx 结合使用
- totorse cvs 用法
- Oracle常用监控SQL
- Oracle常用监控SQL
- STM32 USB Mass Storage 例程调试笔记
- 腾讯实习生笔试题目(一)
- the main methos of class Ssh in pyssh module


