lucene3.6中FSDirectory以及RAMDirectory的使用方法
来源:互联网 发布:淘宝直播海报图片 编辑:程序博客网 时间:2024/05/07 08:42
在lucene中Directory类作为一个基本的目录文件操作类,是基础并且非常重要的,其中我们用的最多的主要有2个分别是FSDirectory和RAMDirectory:
1.FSDirectory是把操作的索引放在磁盘上,优点是文件可以被保存,缺点是速度慢。
用法为:Directory dir =FSDirectory.open(new File(indexPath)); 其中indexPath为索引目录所在的位置。
2.RAMDirectory是把操作的索引放在内存中,优点是操作速度快,缺点是内存中不可保存,一旦关闭后索引目录便会丢失。
用法为: Directory dir = new RAMDirectory(); 一般我们都是新建一个RAMDirectory(),而不像FSDirectory是直接打开存储路径所在位置。
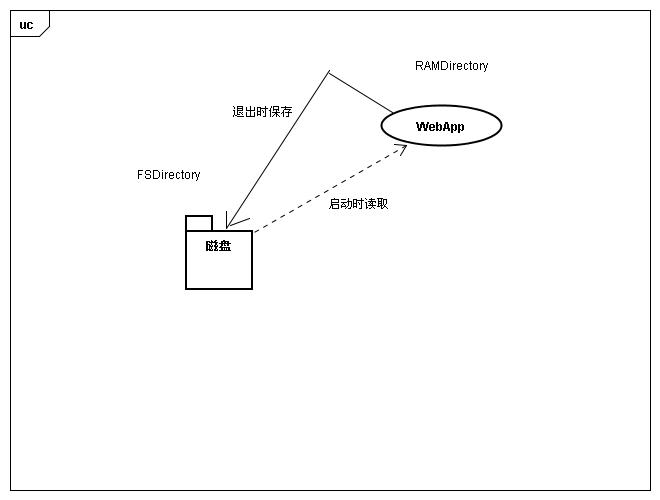
那么我们在实际使用上应该对FSDirectory和RAMDirectory进行如何的取舍?什么时候又该使用什么呢?在lucene的实际应用中,我们一般把FSDirectory和RAMDirectory混合起来应用,互相利用对方的优点来弥补自己的缺点,即:在程序开始的时候分别建立两个Directory类目录,分别是fsdir和ramdir。
在程序运行的时候操作ramdir,在退出保存的时候操作fsdir以保证索引目录不会丢失。
下面这个是我自己画的两者的使用图(随手画的,别太在意那个UC用例):
下面是代码:
总的结构是这样的:
DiretoryTest.java代码如下
package com.itcast.lucene.directory;
import java.io.File;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import com.itcast.lucene.utils.File2DocumentUtils;
public class DiretoryTest {
String filePath = "E:\\zqlstudy\\eclipseworkspace\\LuceneDemo\\luceneDatasource\\IndexWriter addDocument's a javadoc .txt";
String indexPath = "E:\\zqlstudy\\eclipseworkspace\\LuceneDemo\\luceneIndex";
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_36);
@Test
public void test() throws Exception{
/**
* 用directory封装index路径
*/
//Directory dir = FSDirectory.open(new File(indexPath));
Directory dir = new RAMDirectory(); //操作的索引均放入内存当中;优点:速度快 缺点:不保存文件
/**
* 关于FSDirectory.open(new File(indexPath))和new RAMDirectory()的取舍
*
*/
//这里我们需要把file转换成document
Document doc = File2DocumentUtils.file2Document(filePath);
/**
* IndexWriterConfig
*/
IndexWriterConfig conf = new IndexWriterConfig(Version.LUCENE_36, analyzer);
/**
* IndexWriter是操作索引库的一个类(CUD索引库)
*/
IndexWriter writer = new IndexWriter(dir,conf);
writer.addDocument(doc); //增加
writer.close();//最后释放
}
@Test
public void test2() throws Exception{
/**
* 磁盘目录与RAM内存目录的混合使用
* 分别新建2个目录
*/
Directory fsdir = FSDirectory.open(new File(indexPath));
//1.启动的时候读取
Directory ramdir = new RAMDirectory(fsdir);
IndexWriterConfig conf = new IndexWriterConfig(Version.LUCENE_36, analyzer);
IndexWriterConfig conf2 = new IndexWriterConfig(Version.LUCENE_36, analyzer);
//这里要注意,同一个IndexWriterConfig的实例对象是不允许被同时调用2次的,因此我们这里应该另外再new一个IndexWriterConfig的实例
//运行程序时操作RAMdir(内存读取)
IndexWriter ramwriter = new IndexWriter(ramdir,conf);
//添加Document
Document doc = File2DocumentUtils.file2Document(filePath);
ramwriter.addDocument(doc);
ramwriter.close(); //一定要注意关闭
//2.退出的时候保存
IndexWriter fswriter = new IndexWriter(fsdir, conf2);
//退出时把内存中的index保存到磁盘上
fswriter.addIndexes(new Directory[]{ramdir});
//fswriter.addIndexesNoOptimize(new Directory[]{ramdir}); //lucene早期版本的写法,不进行优化
fswriter.close();
}
}
HelloWorld.java代码如下
package com.itcast.lucene.helloworld;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import com.itcast.lucene.utils.File2DocumentUtils;
public class HelloWorld {
/**
* 把地址的'/'换成'//'转义
*/
String filePath = "E:\\zqlstudy\\eclipseworkspace\\LuceneDemo\\luceneDatasource\\IndexWriter addDocument's a javadoc .txt";
String indexPath = "E:\\zqlstudy\\eclipseworkspace\\LuceneDemo\\luceneIndex";
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_36);
/**
*
* 创建索引
* @throws IOException
* @throws CorruptIndexException
*/
@Test
public void createIndex() throws Exception{
/**
* 用directory封装index路径
*/
Directory dir = FSDirectory.open(new File(indexPath));
//这里我们需要把file转换成document
Document doc = File2DocumentUtils.file2Document(filePath);
/**
* IndexWriterConfig
*/
IndexWriterConfig conf = new IndexWriterConfig(Version.LUCENE_36, analyzer);
/**
* IndexWriter是操作索引库的一个类(CUD索引库)
*/
IndexWriter writer = new IndexWriter(dir,conf);
writer.addDocument(doc); //增加
writer.close();//最后释放
}
/**
* 搜索
* IndexSearch是用来在索引库中查询的
*/
@Test
public void search() throws Exception{
String querystring = "document";
/**
* 文本解析为Query
*/
String[] fields = {"name","content"};
QueryParser queryparser = new MultiFieldQueryParser(Version.LUCENE_36, fields, analyzer); //解析器负责解析文本对象为Query对象
Query query = queryparser.parse(querystring);
/**
* 进行查询
*
*/
Directory dir = FSDirectory.open(new File(indexPath));
IndexReader reader=IndexReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader); //从读取的索引中进行查询
Filter filter = null;
//TopDocs是lucene自己封装的一个集合类型
TopDocs topdocs = searcher.search(query, filter, 10000); //过滤器进行过滤屏蔽 10000表示一次进行查询的文档为10000 一般设为1000-10000这个跟效率有关
System.out.println("总共有【"+topdocs.totalHits+"】条匹配结果");
/**
* 打印结果
* scoreDocs指的是当前数据
* totalHits指的是总数据
*/
for(ScoreDoc scoreDoc : topdocs.scoreDocs){
int docSn = scoreDoc.doc;//文档内部编号
Document doc = searcher.doc(docSn); //根据文档编号取出相应的文档
File2DocumentUtils.printDocumentInfo(doc); //打印出文档的信息
}
}
}
File2DocumentUtils.java代码如下
package com.itcast.lucene.utils;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
public class File2DocumentUtils {
public static Document file2Document(String path){
File file = new File(path);
Document doc = new Document();
doc.add(new Field("name",file.getName(),Store.YES,Index.ANALYZED));
doc.add(new Field("content",readFileContent(file),Store.YES,Index.ANALYZED));
doc.add(new Field("size",String.valueOf(file.length()),Store.YES,Index.NOT_ANALYZED));
doc.add(new Field("path",file.getAbsolutePath(),Store.YES,Index.NO));
return doc;
}
public static String readFileContent(File file) {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
StringBuffer content = new StringBuffer();
for(String line = null; (line = reader.readLine())!=null;){
content.append(line).append("\n");
}
return content.toString();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static void printDocumentInfo(Document doc){
/**
* <pre>
* 获取name属性的值
* 即doc.get("name");
* </pre>
*
* @param doc
*/
System.out.println("----------------------------");
System.out.println("name = "+doc.get("name"));
System.out.println("content = "+doc.get("content"));
System.out.println("size = "+doc.get("size"));
System.out.println("path = "+doc.get("path"));
System.out.println("----------------------------");
}
}
用JUnit测试Test2可以看到匹配结果。
- lucene3.6中FSDirectory以及RAMDirectory的使用方法
- FSDirectory 与 RAMDirectory
- 使用RAMDirectory 和 FSDirectory对于索引创建的优化
- RAMDirectory中的内容转到FSDirectory
- Directory(FSDirectory与RAMDirectory同时使用,减少IO操作,提高效率)
- Lucene中索引的删除,更新与查找以及恢复(lucene3.5)
- lucene3.6
- 很好的lucene3.6入门指南
- c#中类的学习以及使用方法
- Lucene3.0(2.9)中对于TokenStream的遍历方法!
- lucene3.0中各检索方法的使用介绍
- lucene3.0中检索方法的使用介绍
- lucene3.1.0+luke3.5.0开发中遇到的问题解决办法
- 痛苦的Lucene3.0.2
- lucene3.6.0的分析器
- Lucene3.6入门实例
- Lucene3.6 之 Filter
- Lucene3.6总结篇
- Sqlite入门与C/C++的应用
- 动态创建无级子菜单:乾坤大挪移无极紫菜汤
- 快速幂乘
- android导入外部已存在的数据库大于1M的数据库文件方法
- MySQL Cluster (三) --- 3台机器搭建集群环境
- lucene3.6中FSDirectory以及RAMDirectory的使用方法
- 应该记住的8位java人物
- Ubuntu笔记
- android raw读取超过1M文件的方法
- 黑马程序员_关于枚举
- chkdsk /f 修复优盘
- 基础太差了
- 第一次面试java笔试题目
- 同步和提交AOKP源码


