全文检索--lucene
来源:互联网 发布:2016网络十大神曲逆 编辑:程序博客网 时间:2024/04/30 10:24
Lucene是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。在此简略介绍一下,以备将来不时之需。
1,在项目底下新建两个文件夹,lucene为存放生成的索引目录,luceneDateResource为存放被索引文件的目录,搜索在此文件中查找,其中要引入的包有:je-analysis-1.5.3.jar,lucene-analyzers-2.4.0.jar,lucene-core-2.4.0.jar,lucene-highlighter-2.4.0.jar
项目目录大概如下:
2,新建一个类,名为HelloWorld.java,其中使用junit 4做单元测试
package com.lucene.helloworld;import java.io.IOException;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriter.MaxFieldLength;import org.apache.lucene.queryParser.MultiFieldQueryParser;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.Filter;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.store.LockObtainFailedException;import org.apache.lucene.store.RAMDirectory;import org.junit.Test;import com.lucene.file2document.utils.File2DocumentUtils;public class HelloWorld { //filePath是文件路径,当前例子在以下的filePath路径底下的文件里进行搜索,indexPath是索引路径,生成的索引文件会放在indexPath下String filePath = "D:\\Documents and Settings\\xuxh\\Workspaces\\MyEclipse 8.6\\luceneDemo\\luceneDateResource\\IndexWriter addDocument's a javadoc .txt"; String indexPath = "D:\\Documents and Settings\\xuxh\\Workspaces\\MyEclipse 8.6\\luceneDemo\\lucene"; Analyzer analyzer = new StandardAnalyzer(); /** * 创建索引 * * IndexWriter 是用来操作(增、删、改)索引库的。 * * @throws IOException * @throws LockObtainFailedException * @throws Exception */ @Test public void createIndex() throws Exception { //因为在文件系统中存放的是file类型文件,而lucene中是document文件,所以在使用时要先进行类型的转换 Document doc = File2DocumentUtils.file2document(filePath); //此处为自己写的一个公用方法,用于将file类型文件转换成document类型 IndexWriter indexWriter = new IndexWriter(indexPath, analyzer, true, MaxFieldLength.LIMITED); //创建索引,进行初始化 indexWriter.addDocument(doc); //添加索引 indexWriter.close(); //关闭资源indexWriter } @Test public void search() throws Exception { String queryString = "document"; //假设要搜索的内容为document // 1,把要搜索的文件解析为Query String[] fields = {"name", "content"}; //要搜索的字段,构成一个数组 QueryParser queryParser = new MultiFieldQueryParser(fields, analyzer); //使用MultiFieldQueryParser可搜索多个字段 Query query = queryParser.parse(queryString); //将String转换成Query // 2,进行查询 Filter filter = null; IndexSearcher indexSearcher = new IndexSearcher(indexPath); //指明索引的路径,开始进行搜索 TopDocs topDocs = indexSearcher.search(query, filter, 10000); System.out.println("总共有【" + topDocs.totalHits + "】条记录"); // 3,打印结果 for(ScoreDoc scoreDoc : topDocs.scoreDocs) { int docSn = scoreDoc.doc; //文档内部编号 Document doc = indexSearcher.doc(docSn); // 根据编号取出相应的文档 File2DocumentUtils.printDocumentInfo(doc); //打印结果 } } /** * 文件系统fsDir与内存系统ramDir的操作,使用Directory类型 */ @Test public void fsAndRam() throws Exception{ Directory fsDir = FSDirectory.getDirectory(indexPath); //取到索引路径 //启动时把文件系统fsDir读取到内存系统ramDir中 Directory ramDir = new RAMDirectory(fsDir); //操作ramDir创建索引 //此处将上述用到的IndexWriter的第一个参数由String改为Directory IndexWriter ramIndexWriter = new IndexWriter(ramDir, analyzer, MaxFieldLength.LIMITED); Document doc = File2DocumentUtils.file2document(filePath); //将file转换成document ramIndexWriter.addDocument(doc); //添加创建索引 ramIndexWriter.optimize(); //优化索引,将其他位置的索引合并到当前索引库中 ramIndexWriter.close(); //关闭资源ramIndexWriter //退出时保存,将ramIndexWriter里的保存到fsIndexWriter IndexWriter fsIndexWriter = new IndexWriter(fsDir, analyzer, true, MaxFieldLength.LIMITED);//此处需指明"true",即重新生成索引,否则会导致索引的重复累积,比如原本搜索过有3条匹配记录,再探索一次,却变成了7条记录,//即第一次的3+第二次的3(即与第一次的3条记录重复的)+重新搜索产生的1条,导致记录重复,实际上第二次搜索只产生1条记录,最后正确的记录数应为4条匹配记录 //addIndexesNoOptimize不进行优化 fsIndexWriter.addIndexesNoOptimize(new Directory[] {ramDir}); //addIndexes将其他位置的索引位置合并到当前索引库当中,addIndexesNoOptimize无优化功能 fsIndexWriter.optimize(); fsIndexWriter.close(); }}
图1 文件系统与索引库的关系
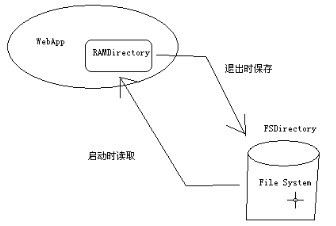
图2 文件系统与内存系统的关系
(1)图1 :由于在文件系统中存放的是File类型的文件,而在索引库中存放的是Document类型的文件,所以在使用lucene进行全文检索时,要在两者之间进行转换,在创建索引时要将文件转换成索引库的储存类型Document ---------createIndex()方法
(2)图2 :有时候可以将需要的内容放在内存中,这样可以提高检索的速度,而使用内存的话可以使用RAMDirectory,在启动时读取Ram的内容,在退出时重新保存为文件系统。-------fsAndRam()方法
3,文件工具类,此类是自己写的一个类,将公用的方法放在此类
package com.lucene.file2document.utils;import java.io.BufferedReader;import java.io.File;import java.io.FileInputStream;import java.io.InputStreamReader;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.Field.Index;import org.apache.lucene.document.Field.Store;public class File2DocumentUtils {/** * 将file转换为document * * 存放在硬盘上的是file类型文件,lucene操作的是document文件,所以在使用lucene时要将file转换成lucene * 存储name,content,size,path * @param path * @return * @throws Exception * @throws Exception */public static Document file2document(String path) throws Exception {File file = new File(path);Document doc = new Document();doc.add(new Field("name", file.getName(), Store.YES, Index.ANALYZED));doc.add(new Field("content", readFileContent(file), Store.YES, Index.ANALYZED));doc.add(new Field("size", String .valueOf(file.length()), Store.YES, Index.NOT_ANALYZED));doc.add(new Field("path", file.getPath(), Store.YES, Index.NO));return doc;}/** * 读取文件内容 * @param document * @throws Exception */public static String readFileContent(File file) throws Exception {BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(file)));StringBuffer content = new StringBuffer();for(String line = null; (line = reader.readLine()) != null;) {content.append(line).append("\n");}return content.toString();}/** * 输出检索出的信息 * * <pre> * 获取 name 属性的值的两种方法: * 1,Field f = doc.getField("name"); * f.stringValue(); * 2,doc.get("name"); * </pre> * * @param doc */public static void printDocumentInfo(Document doc) {System.out.println("------------------------------------------");System.out.println("name = " + doc.get("name"));System.out.println("content = " + doc.get("content"));System.out.println("size = " + doc.get("size"));System.out.println("path = " + doc.get("path"));}}4,运行后,在目录lucene下多出了几个文件,这些文件便是生成的索引文件
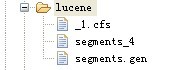

同时运行单元测试中的search()方法后,出现以下的结果:

此处出现2条记录,是因为在HelloWorld.java中运行了两个方法:createIndex()和fsAndRam(),并且这两个方法要在search()方法前调用,否则search()方法不能通过单元测试。
- Lucene 全文检索实践
- lucene 全文检索简介
- lucene 全文检索简介
- Lucene 全文检索
- 全文检索Lucene说明书
- 全文检索引擎lucene
- 全文检索LUCENE
- Lucene全文检索1
- lucene全文检索总结 .
- 全文检索--lucene
- lucene全文检索应用
- Lucene与全文检索
- lucene全文检索案例
- 初识全文检索Lucene
- 全文检索 Lucene
- 全文检索(lucene)
- lucene全文检索更新
- lucene 全文检索
- Android 打包签名 从生成keystore到完成签名
- 一位码农的人生自述(二)------忆
- awk学习笔记
- 如何选购平板电脑
- erlang app file 讲解
- 全文检索--lucene
- wifi详解(四)
- spring权限控制配置一例
- 泛型应用
- Java几款性能分析工具的对比
- 一位码农的人生自述(三)------卿
- django学习日志——mydoit之django admin能做些什么(三)
- 如何做需求分析
- INSTALL_FAILED_INSUFFICIENT_STORAGE调试错误的解决


