R语言tm工具包进行文本挖掘实验
来源:互联网 发布:非洲的社交网络 编辑:程序博客网 时间:2024/04/28 02:51
>library(tm) //使用默认安装的R平台是不带tm package的,必须要到http://www.r-project.org/网站下载package. 值得注意的是:tm package很多函数也要依赖于其它的一些package,所以在这个网站,应该把rJava,Snowball,zoo,XML,slam,Rz,Rweka,matlab这些win32 package一并下载,并解压到默认的library中去。
>vignette("tm") //会打开一个tm.pdf的英文文件,讲述tm package的使用及相关函数
1、Data-import:
> txt <- system.file("texts", "txt", package = "tm") //是为将目录C:\Program Files\R\R-2.15.1\library\tm\texts\txt 记入txt变量
> (ovid <- Corpus(DirSource(txt),readerControl = list(language = "lat"))) //即将txt目录下的5个文件Corpus到Ovid去,language = "lat"表示the directory txt containing Latin (lat) texts
此外,VectorSource is quite useful, as it can create a corpus from character vectors, e.g.:
> docs <- c("This is a text.", "This another one.")
> Corpus(VectorSource(docs)) //A corpus with 2 text documents
在本部分中,我们Finally create a corpus for some Reuters documents as example for later use
> reut21578 <- system.file("texts", "crude", package = "tm")
> reuters <- Corpus(DirSource(reut21578),readerControl = list(reader = readReut21578XML)) // 在这一部分中,将目录C:\Program Files\R\R-2.15.1\library\tm\texts\crude下的20个XML文件Corpus成reuters,要用到XML package(前面已经下载了).
> inspect(ovid[1:2]) //会出现以下的显示,当然identical(ovid[[2]], ovid[["ovid_2.txt"]])==true,所以inspet(ovid["ovid_1.txt","ovid[ovid_2.txt]"])效果一样:

2、Transmation:
> reuters <- tm_map(reuters, as.PlainTextDocument) //This can be done by converting the documents to plain text documents.即去除标签
> reuters <- tm_map(reuters, stripWhitespace) //去除空格
> reuters <- tm_map(reuters, tolower) //将内容转换成小写
> reuters <- tm_map(reuters, removeWords, stopwords("english")) // remove stopwords
注:在这里需要注意的是,如果使用中文分词法,由于词之间无有像英文一样的空隔,好在有Java已经解决了这样的问题,我们只需要在R-console里加载rJava与rmmseg4j两个工具包即可。如
>mmseg4j("中国人民从此站起来了")
[1] 中国 人民 从此 站 起来
3、Filters:
> query <- "id == '237' & heading == 'INDONESIA SEEN AT CROSSROADS OVER ECONOMIC CHANGE'" //query其实是一个字符串,设定了一些文件的条件,如
//id==237, 标题为:indonesia seen at c.........
> tm_filter(reuters, FUN = sFilter, query) // A corpus with 1 text document,这个从数据中就可以看得出来。
4、Meta data management
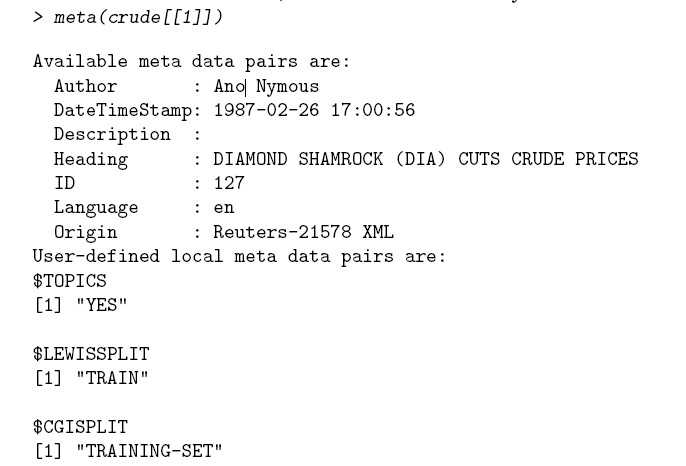
> DublinCore(crude[[1]], "Creator") <- "Ano Nymous" //本来第一个XML文件中是不带作者的,此语句可以改变一些属性的值,类比其它。
> meta(crude[[1]]) //显示第一个文件的元素信息数据得到下图
> meta(crude, tag = "test", type = "corpus") <- "test meta"
> meta(crude, type = "corpus") 改变元素后显示如下

5、Creating Term-Document Matrices
> dtm <- DocumentTermMatrix(reuters)
> inspect(dtm[1:5, 100:105]) //显示如下:
A document-term matrix (5 documents, 6 terms)
Non-/sparse entries: 1/29
Sparsity : 97%
Maximal term length: 10
Weighting : term frequency (tf)
Terms
Docs abdul-aziz ability able abroad, abu accept
127 0 0 0 0 0 0
144 0 2 0 0 0 0
191 0 0 0 0 0 0
194 0 0 0 0 0 0
211 0 0 0 0 0 0
6、对Term-document矩阵的进一步操作举例
> findFreqTerms(dtm, 5) //nd those terms that occur at least 5 times in these 20 files 显示如下:
[1] "15.8" "accord" "agency" "ali"
[5] "analysts" "arab" "arabia" "barrel."
[9] "barrels" "bpd" "commitment" "crude"
[13] "daily" "dlrs" "economic" "emergency"
[17] "energy" "exchange" "exports" "feb"
[21] "futures" "government" "gulf" "help"
[25] "hold" "international" "january" "kuwait"
[29] "march" "market"
> findAssocs(dtm, "opec", 0.8) // Find associations (i.e., terms which correlate) with at least 0:8 correlation for the term opec
opec prices. 15.8
1.00 0.81 0.80
如果需要考察多个文档中特有词汇的出现频率,可以手工生成字典,并将它作为生成矩阵的参数
> d <- Dictionary(c("prices", "crude", "oil")))
> inspect(DocumentTermMatrix(reuters, list(dictionary = d)))
因为生成的term-document矩阵dtm是一个稀疏矩阵,再进行降维处理,之后转为标准数据框格式
> dtm2 <- removeSparseTerms(dtm, sparse=0.95) //parse值越少,最后保留的term数量就越少
> data <- as.data.frame(inspect(dtm2)) //最后将term-document矩阵生成数据框就可以进行聚类等操作了见下部分
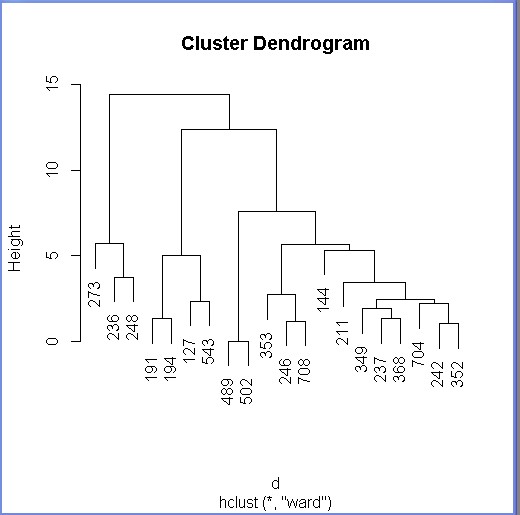
7、 再之后就可以利用R语言中任何工具加以研究了,下面用层次聚类试试看
> data.scale <- scale(data)
> d <- dist(data.scale, method = "euclidean")
> fit <- hclust(d, method="ward")
>plot(fit) //图形见下:
- R语言tm工具包进行文本挖掘实验
- 利用R语言的tm包进行文本挖掘
- R包之tm:文本挖掘包
- R语言︱文本挖掘套餐包之——XML+SnowballC+tm包
- R语言学习笔记——使用tm包挖掘文本中的频繁词
- R语言文本挖掘tm包详解(附代码实现)
- R:文本挖掘学习笔记1 - tm Package
- R语言做文本挖掘
- R语言之文本挖掘
- R语言-文本挖掘例子
- R语言文本挖掘-分词
- 使用R进行文本数据挖掘
- 基于R语言的文本挖掘技术
- 【R语言】文本挖掘-情感分析
- R语言|文本挖掘应用|标签云
- R语言:文本挖掘 主题模型 文本分类
- R语言做文本挖掘 Part3文本聚类
- R语言做文本挖掘 Part4文本分类
- Hadoop,MapReduce操作Mysql
- boj64解题报告
- MapReduce,DataJoin,链接多数据源
- Java中多线程实现方式2和3
- iphone App的国际化
- R语言tm工具包进行文本挖掘实验
- paip.51cto HTML转码规则
- 棋盘问题
- dotcloud 托管 python web应用 第一章 helloworld
- org.hibernate.hql.ast.QuerySyntaxException: User is not mapped [from User] 异常总结
- word中的vba
- 输入三个整数,把这三个数由小到大输出。
- Box2D v2.1.0用户手册翻译 - 第02章 Hello Box2D
- log4j使用教程


