Dive Into Python 学习记录2-自省/info 函数 /str / type /callable 函数
来源:互联网 发布:sybase数据库备份恢复 编辑:程序博客网 时间:2024/05/22 07:04
2.1 自省
自省是指代码可以查看内存中以对象形式存在的其它模块和函数,获取它们的信息,并对它们进行操作。用这种方法,你可以定义没有名称的函数,不按函数声明的参数顺序调用函数,甚至引用事先并不知道名称的函数。
def info(object, spacing=10, collapse=1):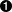
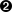
#多行 doc string 被合并到单行中,要改变这个选项需要指定 collapse 参数的值为 0。 #如果函数名称长于10个字符,你可以将 spacing 参数的值指定为更大的值以使输出更容易阅读 """Print methods and doc strings. #即该参数的设置直接影响后续文档说明的输出排列 Takes module, class, list, dictionary, or string.""" methodList = [method for method in dir(object) if callable(getattr(object, method))] processFunc = collapse and (lambda s: " ".join(s.split())) or (lambda s: s) print "\n".join(["%s %s" % (method.ljust(spacing), processFunc(str(getattr(object, method).__doc__))) for method in methodList])if __name__ == "__main__":

print info.__doc__
info 函数的设计意图是提供给工作在 PythonIDE 中的开发人员使用,它可以接受任何含有函数或者方法的对象 (比如模块,含有函数,又比如list,含有方法) 作为参数,并打印出对象的所有函数和它们的doc string。
info 函数就是这样一个例子,它有两个可选参数。
def info(object, spacing=10, collapse=1):spacing 和 collapse 是可选参数,因为它们已经定义了缺省值。object 是必备参数,因为它没有指定缺省值。如果调用info 时只指定一个参数,那么 spacing 缺省为 10 ,collapse 缺省为 1。如果调用 info 时指定两个参数,collapse 依然默认为 1。
假如你要指定 collapse 的值,但是又想要接受 spacing 的缺省值。在绝大部分语言中,你可能运气就不太好了,因为你需要使用三个参数来调用函数,这势必要重新指定spacing 的值。但是在 Python 中,参数可以通过名称以任意顺序指定。
举例:对一个list查找可以进行相关操作的函数
>>> from apihelper import info
>>> li = [ ]
>>> info(li)
__add__ x.__add__(y) <==> x+y
__class__ list() -> new empty list list(iterable) -> new list initialized from iterable's items
__contains__ x.__contains__(y) <==> y in x
__delattr__ x.__delattr__('name') <==> del x.name
__delitem__ x.__delitem__(y) <==> del x[y]
__delslice__ x.__delslice__(i, j) <==> del x[i:j] Use of negative indices is not supported.
__eq__ x.__eq__(y) <==> x==y
__format__ default object formatter
__ge__ x.__ge__(y) <==> x>=y
__getattribute__ x.__getattribute__('name') <==> x.name
__getitem__ x.__getitem__(y) <==> x[y]
__getslice__ x.__getslice__(i, j) <==> x[i:j] Use of negative indices is not supported.
__gt__ x.__gt__(y) <==> x>y
__iadd__ x.__iadd__(y) <==> x+=y
__imul__ x.__imul__(y) <==> x*=y
__init__ x.__init__(...) initializes x; see help(type(x)) for signature
__iter__ x.__iter__() <==> iter(x)
__le__ x.__le__(y) <==> x<=y
__len__ x.__len__() <==> len(x)
__lt__ x.__lt__(y) <==> x<y
__mul__ x.__mul__(n) <==> x*n
__ne__ x.__ne__(y) <==> x!=y
__new__ T.__new__(S, ...) -> a new object with type S, a subtype of T
__reduce__ helper for pickle
__reduce_ex__ helper for pickle
__repr__ x.__repr__() <==> repr(x)
__reversed__ L.__reversed__() -- return a reverse iterator over the list
__rmul__ x.__rmul__(n) <==> n*x
__setattr__ x.__setattr__('name', value) <==> x.name = value
__setitem__ x.__setitem__(i, y) <==> x[i]=y
__setslice__ x.__setslice__(i, j, y) <==> x[i:j]=y Use of negative indices is not supported.
__sizeof__ L.__sizeof__() -- size of L in memory, in bytes
__str__ x.__str__() <==> str(x)
__subclasshook__ Abstract classes can override this to customize issubclass(). This is invoked early on by abc.ABCMeta.__subclasscheck__(). It should return True, False or NotImplemented. If it returns NotImplemented, the normal algorithm is used. Otherwise, it overrides the normal algorithm (and the outcome is cached).
append L.append(object) -- append object to end
count L.count(value) -> integer -- return number of occurrences of value
extend L.extend(iterable) -- extend list by appending elements from the iterable
index L.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present.
insert L.insert(index, object) -- insert object before index
pop L.pop([index]) -> item -- remove and return item at index (default last). Raises IndexError if list is empty or index is out of range.
remove L.remove(value) -- remove first occurrence of value. Raises ValueError if the value is not present.
reverse L.reverse() -- reverse *IN PLACE*
sort L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*; cmp(x, y) -> -1, 0, 1
>>> import odbchelper
>>> info(odbchelper)
buildConnectionString Build a connection string from a dictionary Returns string.
>>> info(odbchelper, 30, 0)
buildConnectionString Build a connection string from a dictionary
Returns string.
举例:对一个tuple查找可以进行相关操作的函数
from apihelper import info
>>> li = ()
>>> info(li)
__add__ x.__add__(y) <==> x+y
__class__ tuple() -> empty tuple tuple(iterable) -> tuple initialized from iterable's items If the argument is a tuple, the return value is the same object.
__contains__ x.__contains__(y) <==> y in x
__delattr__ x.__delattr__('name') <==> del x.name
__eq__ x.__eq__(y) <==> x==y
__format__ default object formatter
__ge__ x.__ge__(y) <==> x>=y
__getattribute__ x.__getattribute__('name') <==> x.name
__getitem__ x.__getitem__(y) <==> x[y]
__getnewargs__ None
__getslice__ x.__getslice__(i, j) <==> x[i:j] Use of negative indices is not supported.
__gt__ x.__gt__(y) <==> x>y
__hash__ x.__hash__() <==> hash(x)
__init__ x.__init__(...) initializes x; see help(type(x)) for signature
__iter__ x.__iter__() <==> iter(x)
__le__ x.__le__(y) <==> x<=y
__len__ x.__len__() <==> len(x)
__lt__ x.__lt__(y) <==> x<y
__mul__ x.__mul__(n) <==> x*n
__ne__ x.__ne__(y) <==> x!=y
__new__ T.__new__(S, ...) -> a new object with type S, a subtype of T
__reduce__ helper for pickle
__reduce_ex__ helper for pickle
__repr__ x.__repr__() <==> repr(x)
__rmul__ x.__rmul__(n) <==> n*x
__setattr__ x.__setattr__('name', value) <==> x.name = value
__sizeof__ T.__sizeof__() -- size of T in memory, in bytes
__str__ x.__str__() <==> str(x)
__subclasshook__ Abstract classes can override this to customize issubclass(). This is invoked early on by abc.ABCMeta.__subclasscheck__(). It should return True, False or NotImplemented. If it returns NotImplemented, the normal algorithm is used. Otherwise, it overrides the normal algorithm (and the outcome is cached).
count T.count(value) -> integer -- return number of occurrences of value
index T.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present.
>>>
2.2 type / str / dir
>>> type(1)
str 将数据强制转换为字符串。每种数据类型都可以强制转换为字符串。str 还允许作用于模块;
>>> a = 123456
>>> str (a)
'123456'
>>> b = str (a)
>>> b
'123456'
>>> a
123456
>>> list = ['123', '456','789','python']
>>> list
['123', '456', '789', 'python']
>>> b = str(list)
>>> b
"['123', '456', '789', 'python']"
>>> tuple = ('123', '456','789','python')
>>> tuple
('123', '456', '789', 'python')
>>> b = str(tuple)
>>> b
"('123', '456', '789', 'python')"
>>> tuple = (123, 456,789,python) #元组内元素python类型无法确定,报错,
Traceback (most recent call last):
File "<pyshell#28>", line 1, in <module>
tuple = (123, 456,789,python)
NameError: name 'python' is not defined
>>> tuple = (123, 456,789)
>>> tuple = (123, 456,789,'python') # 字符串写法,否则报未定义错误
>>> b = str(tuple)
>>> b
"(123, 456, 789, 'python')"
>>>
>>> type(tuple[0])
<type 'int'>
>>> type(tuple[3])
<type 'str'>
tuple = (abc, der, python) # 有此用法,但元素需要先定义
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
tuple = (abc, der, python)
NameError: name 'abc' is not defined
info 函数的核心是强大的 dir 函数。dir 函数返回任意对象的属性和方法列表,包括模块对象、函数对象、字符串对象、列表对象、字典对象 …… 相当多的东西。
>>> li = []>>> dir(li)
callable 函数,它接收任何对象作为参数,如果参数对象是可调用的,返回 True;否则返回 False。可调用对象包括函数、类方法,甚至类自身
>>> import string>>> string.punctuation
- Dive Into Python 学习记录2-自省/info 函数 /str / type /callable 函数
- Dive Into Python 学习记录3-getattr 介绍/过滤列表/and or/lambda 函数
- Python的type, str, dir和callable函数
- Dive Into Python 学习记录1-函数/模块导入/字典/列表/元组/字符串分割、连接、格式化/映射list/
- dive into python (2)
- Dive into python第四章自省的威力笔记
- [Dive into Python:第四章]:自省的威力
- Dive Into Python学习日志
- python函数 cmp() type() str() repr()和 ''
- Dive in Python学习笔记四:自省的威力
- Dive into python 第4章 自省的威…
- Dive Into Python
- Dive into Python 点滴
- dive into python (3)
- dive into python
- python常用的自省函数
- python常用内置函数dir,type,str等
- python函数 callable(object)
- MAC加密算法家族
- 如何在CSDN博客中的所贴的代码进行【代码块】显示
- SQL Server更改表数据类型View中Column数据类型没有相应改变
- Block 编程(翻译官方文档)
- @Deprecated
- Dive Into Python 学习记录2-自省/info 函数 /str / type /callable 函数
- 解读巧避友情链接的5大风险
- NOI 兔兔与蛋蛋的游戏
- 360浏览器打开多标签功能
- 快速排序 Java/C
- 用邮件发送运行时间久的SQL语句
- INI读写(C#)
- IP、ICMP、UDP、TCP 校验和算法
- 关于scanf("%c",&ch)直接跳过的问题


