hibernate复习的笔记
来源:互联网 发布:平安证券软件官网 编辑:程序博客网 时间:2024/04/27 23:20
Hibernate的复习
1、 映射的javaBean实体类必须有一个不带参数的构造方法。实体类最好不要写成final型,对懒加载会有影响。加了final懒加载不能使用。
2、 Session的几个主要方法:save, persist(在事务外不会产生sql语句) 保存数据 delete删除数据 update更新数据 get 【load(永远都会产生一个对象)】根据ID查找数据 saveOrUpdate merge(托管) lock把对象变成持久对象
3、 Hibernate对象的三种状态:瞬时:跟数据库没有关联,跟session也没有关联
持久:跟数据库有关联,跟session也有关联 游离(托管):跟数据库有关联,跟session没有关联 (根据ID是否有值来判断是游离还是瞬时)
4、save 一般处理瞬时状态的对象 update一般处理游离的状态的对象
HQL查询
5、Session session = null;
session = HibernateUtil.getSession();
//String hql = "from User where name =:name";
//query.setString("name", name);
String hql = "from User ";
Query query = session.createQuery(hql);
//query.uniqueResult();//结果集只有一条
query.setFirstResult(0);
query.setMaxResults(3);
6、String hql = "select name, age from User where id = 3";//结果集只有一条
session = HibernateUtil.getSession();
Query query = session.createQuery(hql);
List<Object[]> list = query.list();
System.out.println(list.size());//结果为1
System.out.println(list.get(0)[0]);
System.out.println(list.get(0)[1]);
7、Criteria的查询// Restrictions:限制
session = HibernateUtil.getSession();
Criteria criteria = session.createCriteria(User.class);
criteria.add(Restrictions.eq("id", 1));
criteria.add(Restrictions.like("name", name+"%"));
criteria.add(Restrictions.or(Restrictions.eq("id", 1), Restrictions.between("id", 2, 3)));
//这是分页查询
criteria.setFirstResult(0);
criteria.setMaxResults(3);
list = criteria.list();
for (User user : list) {
System.out.println(user.getName());}
8、多对一的关系模型
<many-to-one not-null="true" cascade="save-update" name="dep" column="depId" ></many-to-one><!--depId是外键的字段名,dep是外键的对象表示形式,cascede(save-update、delete、all)表示的级联,not-null表示外键不能为空 -->
9、解决mysql乱码问题(default那里进行修改)

10、级联:cascade(save-update、)Hibernate.initialize(emp.getDep());可以处理懒加载
11、一对多 注意:当定义的像Set这样的集合时,不要写成具体的类(HashSet),否则会报错。
<!--name表示部门表中有很多员工,class表示emps表示的类型,key是外键,它必须跟主表中的外键的名字一样,正是根据外键才能找到员工的 -->
<set name="emps" cascade="save-update">
<key column="depId"></key>
<one-to-many class="com.total.Emp"/>
</set>
12、一对一
主表:<one-to-one cascade="all" name="idCard"></one-to-one>
从表:<class name="IdCard">
<id name="id">
<generator class="foreign">
<param name="property">person</param>
</generator>
</id>
<property name="name"></property>
<one-to-one cascade="all" name="person" constrained="true"></one-to-one>//注释:constrained:表示从对象的主键是引用的主对象的主键的一种约束,必须要为真,对懒加载的时候有用
</class>
如果从主表开始查询从表的内容,其实就是一个join连接,而如果从从表开始查询主表的内容,则需要两个select语句,按原则上讲,第一种的效率更高。
一对一的第二种方法的映射文件
<!-- 第二种写法 -->主表
<class name="IdCard">
<id name="id">
<generator class="native"></generator>
</id>
<property name="name"></property>
<many-to-one name="person" column="person_Id" unique="true" not-null="true"></many-to-one>
</class>
<!-- 第二种写法 -->从表
<class name="Person">
<id name="personId">
<generator class="native"></generator>
</id>
<property name="name"></property>
<one-to-one cascade="all" name="idCard" property-ref="person"/><!-- 这就是IdCard中的person,根据它找得到IdCard的对象 -->
</class>
13、多对多的映射
<1><class name="Student">
<id name="id">
<generator class="native"></generator>
</id>
<property name="name"></property>
<set name="teacher" table="teacher_student">
<key column="student_id"></key>
<many-to-many class="Teacher" column="teacher_id"></many-to-many>
</set>
</class>
<2><class name="Teacher">
<id name="id">
<generator class="native"></generator>
</id>
<property name="name"></property>
<set name="students" table="teacher_student">
<key column="teacher_id"></key>
<many-to-many column="student_id" class="Student"></many-to-many>
</set>
</class>
多对一、多对多的关系查询时效率比较低,最好不要使用。
14、组建映射(就是在Person对象中的一个属性是一个对象:如Person对象中有一个属性是Name),
<class name="Person">
<id name="personId">
<generator class="native"></generator>
</id>
<component name="name"><!--组建映射 -->
<property name="firstName"></property>
<property name="lastName"></property>
</component>
<one-to-one cascade="all" name="idCard" property-ref="person"/><!-- 这就是IdCard中的person,根据它找得到IdCard的对象 -->
</class>
15、set、list、bag、map
<set name="emps" cascade="save-update">
<key column="depId"></key>
<one-to-many class="com.total.Emp"/>
</set>-->
<list name="emps" cascade="all">
<key column="depId"></key>
<list-index column="OrderId" base="1"></list-index>
<one-to-many class="com.total.Emp"/>
</list>
<bag name="emps">它对应的也List但是没有顺序
<key column="depId"></key>
<one-to-many class="Emp"/>
</bag>
<map name="emps" cascade="all">
<key column="depId"></key>
<map-key type="string" column="empName"></map-key>//column表示emps中的empName属性
<one-to-many class="Emp"/>
</map>
<array name="emps" cascade="all">//用法与list相同
<key column="depId"></key>
<list-index base="1" column="orderId"></list-index>
<one-to-many class="Emp"/>
</array>
16、关于级联cascade(none,all,save-update,delete)
一般来说many-to-one和many-to-many都不设置级联,one-to-one和one-to-many才设置级联。
17、inverse是否放弃维护关联关系,在one-to-many、many-to-many设置为true,放弃维护关系。One-to-many维护关系。注意:one-to-one的对象不维护关联关系。注意:inverse不能在有序集合中出现如:list array。inverse只会在集合中出现。
18、继承的映射关系
<1>父表、子表在同一张表中,有字段是空的,设计上不是很好。查询效率比较高Discriminator---鉴别器
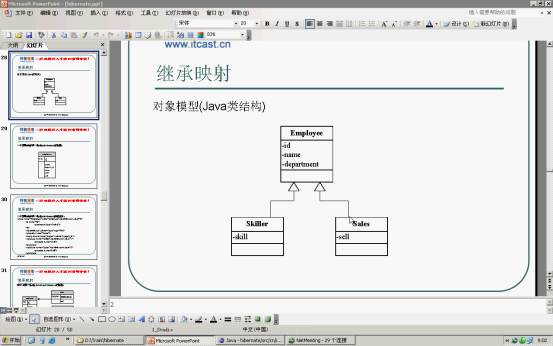
<class name="Employee" discriminator-value="0">
<id name="empId">
<generator class="native"></generator>
</id>
<discriminator column="type" type="string"></discriminator><!-- 有识别力的 -->
<property name="name"></property>
<many-to-one name="dep" column="depId" cascade="all"></many-to-one>
<subclass name="Sales" discriminator-value="1">
<property name="sale"></property>
</subclass>
<subclass name="Skiller" discriminator-value="2">
<property name="skiller"></property>
</subclass>
</class>
Employee employee2 = (Employee) session.get(Employee.class, 3);
System.out.println(employee2.getClass());//hibernate能自动判断是哪种对象的类型。这种多态查询,hibernate能自动判断它的类型,而且效率比较好。
<2>父类、子类在同一张表中 不会出现空字段,但是效率比较低(特别是查询的效率)
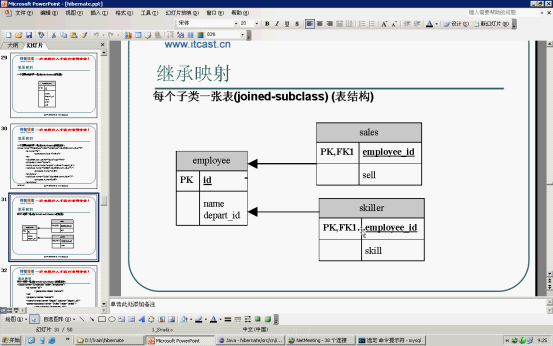
<class name="Employee" discriminator-value="0">
<id name="empId">
<generator class="native"></generator>
</id>
<property name="name"></property>
<many-to-one name="dep" cascade="all" column="depId"></many-to-one>
<joined-subclass name="Sales" table="sales">
<key column="empId" ></key>//column即使主键,也是外键,名字随便取,最好与主表中的主键名字相同
<property name="sale"></property>
</joined-subclass>
<joined-subclass name="Skiller" table="skiller">
<key column="empId"></key>//column即使主键,也是外键
<property name="skiller"></property>
</joined-subclass>
</class>
Employee employee2 = (Employee) session.get(Employee.class, 3);
查询语句查询主表是效率比较高只要查询主表,但是查询子表时,则需要连接所有的子表查询,效率比较低。
System.out.println(employee2.getName());//hibernate能自动判断是哪种对象的类型。
<3>字段数较少的子表与父表在同一个表,字段较多的独立存在一张表
<!-- 第三种写法 -->
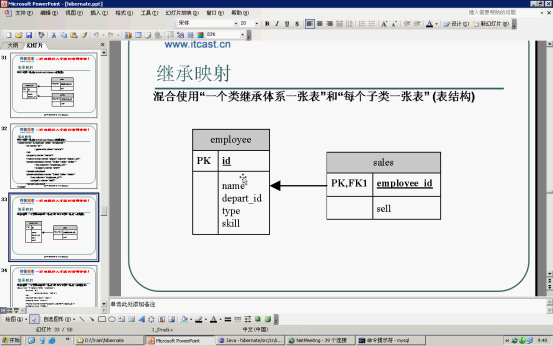
<class name="Employee" discriminator-value="0">
<id name="empId">
<generator class="native"></generator>
</id>
<discriminator column="type" type="string"></discriminator>
<property name="name"></property>
<many-to-one name="dep" column="depId" cascade="all"></many-to-one>
<subclass name="Sales" discriminator-value="1">
<property name="sale"></property>
</subclass>
<subclass name="Skiller" discriminator-value="2">
<join table="skiller">
<key column="empId"></key>
<property name="skiller"></property>
</join>
</subclass>
</class>
优点:结合了上序两表的优点。
<4>

<!-- 第四种写法 -->会生成三个表
<class name="Employee" discriminator-value="0">
<id name="empId">
<generator class="holi "></generator>//这种方法的主键生成不能使自动增长
</id>
<property name="name"></property>
<union-subclass name="Sales" table="sales">
<property name="sale"></property>
</union-subclass>
<union-subclass name="Skiller" table="skiller">
<property name="skiller"></property>
</union-subclass>
</class>
查询时是连接三个表(union)然后在所有的记录中查询那条符合条件的记录。有一定的效率影响。
19、懒加载(主要是通过asm、cglib这两个包来实现的)
Get、load的区别,load只有在对象调用的时候才会去访问数据库,而get是马上就会去访问。
如果查询的记录不存在,load会报ObjectNotFoundException异常,而get会报NullPointerException异常
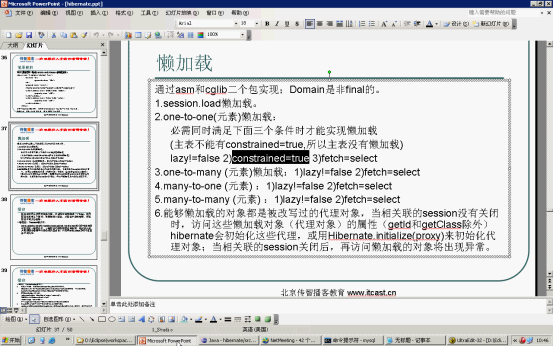
在一对一的关系中,查询主对象时,在默认情况下,是不存在懒加载的,但是查询从表时会存在懒加载。
从表中:<one-to-one cascade="all" lazy="proxy" fetch="join" name="person" constrained="true"></one-to-one>lazy 、fetch能实现不是懒加载,默认情况下是懒加载。Hibernate.initialize(card.getPerson());可以初始化。消除懒加载。
多对一、多对多主要也是通过lazy、fetch的设置来实现懒加载的消除的。
 比较重要。
比较重要。
20、缓存:

Session中有一个缓存。叫做一级缓存
Query不能从session的缓存中取数据。 能从一级缓存取数据的只有get、load、iterator.
evict(Object) 清除session(一级缓存)的一个对象,clear()清除所有的缓存对象。
二级缓存:

图中二级缓存缺少的第一步:cache.use_second_level_cache true默认情况下,二级缓存是打开的,所以不配置也可以。第二部是:cache.provider_class
org.hibernate.cache.OSCacheProvider 第三步是:<cache usage="read-only"/>或<class-cache usage="read-only" class="Student"/>第四部:在src的路径下加上oscache.propertities文件(本人试验加与不加的效果一样)。
Hinernate首先是从一级缓存查找,如果没有,然后再是二级缓存查找,如果还没有,就到数据库查找。先配置hibernate.generate_statistics true这样有利于二级缓存的调试。
SessionFactory factory =HibernateUtil.getSessionFactory();
Statistics statistics = factory.getStatistics();//统计类
System.out.println(statistics);
System.out.println(statistics.getSecondLevelCacheHitCount());//被击中的次数
System.out.println(statistics.getSecondLevelCacheMissCount());//没被击中的次数
System.out.println(statistics.getSecondLevelCachePutCount());//放入二级缓存的次数
清楚二级缓存的对象:HibernateUtil.getSessionFactory().evict(User.class);的所有对象
HibernateUtil.getSessionFactory().evict(User.class,1);青春二级缓存的某个对象
Query、criteria查询不会用到一、二级缓存(一般不使用,因为它们的命中点太低),要使用,除了配置上序的耳机缓存的配置为,还需要query.setCacheable(true); 和cache.use_query_cache true

这是JTA的事物,可以处理几个数据库的件的处理。
TreadLocal相当于一个Map,它的主键是跟当前线程有关的。
private static ThreadLocal local = new ThreadLocal();
public static Session getSession()
{
Session session = (Session) local.get();
if(session != null)
{
return session;
}
session = getSessionFactory().openSession();
local.set(session);
return (Session) local.get();
}
21、openSessionInView自己写的
OpenSessionInViewFilter的作用
Spring为我们解决Hibernate的Session的关闭与开启问题。
Hibernate 允许对关联对象、属性进行延迟加载,但是必须保证延迟加载的操作限于同一个 Hibernate Session 范围之内进行。如果 Service 层返回一个启用了延迟加载功能的领域对象给 Web 层,当 Web 层访问到那些需要延迟加载的数据时,由于加载领域对象的 Hibernate Session 已经关闭,这些导致延迟加载数据的访问异常
public void doFilter(ServletRequest arg0, ServletResponse arg1,
FilterChain arg2) throws IOException, ServletException {
Session session = null;
Transaction transaction = null;
try {
session = HibernateUtil.getSession();
transaction = session.beginTransaction();
arg2.doFilter(arg0, arg1);
transaction.commit();
} catch (Exception e) {
if(transaction != null){transaction.rollback();}
e.printStackTrace();
throw new RuntimeException();
}finally{
HibernateUtil.closeSession();
}
}
22、乐观锁
乐观锁,大多是基于数据版本(Version)记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个“version”字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
怎么设置:1、首先在要加乐观锁的对象上添加一个字段(可以使整形,也可以是时间,只要是可以区别时间的都行)。2、然后在配置文件中增加一个<version name="ver"></version>或<timestamp name="ver"></timestamp>在Id后面。3、在要加乐观锁的class里面加一个 optimistic-lock="version" 默认情况下就是这样。注意:每次测试时,要使用不同的session。测试时会报org.hibernate.StaleObjectStateException异常。
23、配置连接池(c3p0)
首先在总的配置文件配置:在lib中加上c3p0的包,再配置connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider,还可以配一些连接池有关的一些配置。
24、一些hibernate其他的配置
hibernate.default_batch_fetch_size = 8
25、 基本值类型
内建的 基本映射类型可以大致分为
integer, long, short, float, double, character, byte, boolean, yes_no, true_false
这些类型都对应Java的原始类型或者其封装类,来符合(特定厂商的)SQL 字段类型。boolean, yes_no 和 true_false都是Java 中boolean 或者java.lang.Boolean的另外说法。
string
从java.lang.String 到 VARCHAR (或者 Oracle的 VARCHAR2)的映射。
date, time, timestamp
从java.util.Date和其子类到SQL类型DATE, TIME 和TIMESTAMP (或等价类型)的映射。
calendar, calendar_date
从java.util.Calendar 到SQL 类型TIMESTAMP和 DATE(或等价类型)的映射。
big_decimal, big_integer
从java.math.BigDecimal和java.math.BigInteger到NUMERIC (或者 Oracle 的NUMBER类型)的映射。
locale, timezone, currency
从java.util.Locale, java.util.TimeZone 和java.util.Currency 到VARCHAR (或者 Oracle 的VARCHAR2类型)的映射. Locale和 Currency 的实例被映射为它们的ISO代码。TimeZone的实例被影射为它的ID。
class
从java.lang.Class 到 VARCHAR (或者 Oracle 的VARCHAR2类型)的映射。Class被映射为它的全限定名。
binary
把字节数组(byte arrays)映射为对应的 SQL二进制类型。
text
把长Java字符串映射为SQL的CLOB或者TEXT类型。
serializable
把可序列化的Java类型映射到对应的SQL二进制类型。你也可以为一个并非默认为基本类型的可序列化Java类或者接口指定Hibernate类型serializable。
clob, blob
JDBC 类 java.sql.Clob 和 java.sql.Blob的映射。某些程序可能不适合使用这个类型,因为blob和clob对象可能在一个事务之外是无法重用的。(而且, 驱动程序对这种类型的支持充满着补丁和前后矛盾。)
imm_date, imm_time, imm_timestamp, imm_calendar, imm_calendar_date, imm_serializable, imm_binary
一般来说,映射类型被假定为是可变的Java类型,只有对不可变Java类型,Hibernate会采取特定的优化措施,应用程序会把这些对象作为不可变对象处理。比如,你不应该对作为imm_timestamp映射的Date执行Date.setTime()。要改变属性的值,并且保存这一改变,应用程序必须对这一属性重新设置一个新的(不一样的)对象。
实体及其集合的唯一标识可以是除了binary、 blob 和 clob之外的任何基础类型。(联合标识也是允许的,后面会说到。)
在org.hibernate.Hibernate中,定义了基础类型对应的Type常量。比如,Hibernate.STRING代表string 类型。
自定义类型(hibernate帮助文档查找)
26、关于session的线程不安全,sessionFactory是线程安全的。

27、session的一级缓存和批量更新问题
Session的flush方法,是保持数据与数据库同步,一般情况下不使用。因为有时候一级缓存的数据不需要马上就插入数据库,hibernate会自动将数据插入数据库,会自动进行处理。
public static void main(String[] args) {
Configuration configuration = new Configuration().configure();
SessionFactory sessionFactory = configuration.buildSessionFactory();
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
Emp emp1 = new Emp();
emp1.setEmpName("张三");
Emp emp2 = new Emp();
emp2.setEmpName("李四");
Dep dep = new Dep();
dep.setDepName("学习部");
dep.getEmps().add(emp1);
dep.getEmps().add(emp2);
for (int i = 0; i < 1000000000; i++) {
session.save(dep);//会将数据放入一级缓存、二级缓存//如果一次性保存全部的,hibernate会把它们先放在一级缓存中,等全部放入一级缓存中才会全部插入数据库,那么可能会导致一级缓存溢出,所有需要批量进行插入,当插入20个是就清空一级缓存。
if(i % 20 == 0)
{
session.flush();//将数据批量插入数据库。
session.clear();//批量插入一次性插入20个
}
transaction.commit();
session.close();
}
无状态的sesssion进行批量插入。
StatelessSession session = sessionFactory.openStatelessSession();
这种session不会与一级、二级、过滤器、拦截器打交道,用它进行批量操作时,它会马上把数据立即插入数据库,跟JDBC的操作差不多。(它主要用来进行批量的插入,一般情况下不要使用它。
//批量跟新
Query query = session.createQuery("from Emp");
List<Emp>list = query.list();
for (Emp emp : list) {
emp.setEmpName("asd");//进行更新。
session.update(emp);//不要要该句,因为持久化对象会自动进行数据库的跟新
}//hibernate 3.0之前的版本只能用这种方法进行批量更新。
//批量更新 hibernate 3.0之之后的版本才能用这种方法进行批量更新。它还存在一些问题,用它的时候千万谨慎。
Query query1= session.createQuery("update Emp set empName =: name");
query.executeUpdate();
query1.setString("name",name);
28、Hql和Criteria的一些补充
Query query = session.createQuery("from Emp where empId = 1");
session.get(Emp.class, 1);
这两的区别在于第一种不会从缓存中去取,但是第二个会到缓存中取数据。能够从缓存中取数据的只有get、load、iterator
Query.iterator()的一些见解。
某些情况下,你可以使用iterate()方法得到更好的性能。 这通常是你预期返回的结果在session,或二级缓存(second-level cache)中已经存在时的情况。 如若不然,iterate()会比list()慢,而且可能简单查询也需要进行多次数据库访问: iterate()会首先使用1条语句得到所有对象的持久化标识(identifiers),再根据持久化标识执行n条附加的select语句实例化实际的对象。
// fetch ids
Iterator iter = sess.createQuery("from eg.Qux q order by q.likeliness").iterate();
while ( iter.hasNext() )
{
Qux qux = (Qux) iter.next();
}
Criteria的一些补充
离线查询 detachedCriteria是个做动态查找(适合做从web页面传过来几个条件(不确定个数),然后后台进行操作(这样就可以避免很长的sql语句的拼凑(jdbc的做法));
DetachedCriteria detachedCriteria = DetachedCriteria.forClass(Emp.class);
detachedCriteria.add(Restrictions.eq("empId", empId));//可以根据前台传过来的条件的多少进行条件的增减。
detachedCriteria.add(Restrictions.eq("empName", empName));
Criteria criteria = detachedCriteria.getExecutableCriteria(session);
关于N+1次查询
29、时间监听器(可以再session进行一些操作之后再做些事情,与过滤器的作用有点相似
1、首先些一个监听器,实现SaveOrUpdateEventListener接口,然后在hibernate.cfg.hbm的配置文件中进行注册(一定得注册hibernate自己的一个监听器)
配置文件的配置:
<listener type="save" class="com.listeners.EmpLisenter"/>
<listener type="save" class="org.hibernate.event.def.DefaultSaveOrUpdateEventListener"/>
实现接口的:public class EmpLisenter implements SaveOrUpdateEventListener {
public Serializable onSaveOrUpdate(SaveOrUpdateEvent event)
throws HibernateException {
if (event.getObject() instanceof com.pojos.Emp) {
Emp user = (Emp) event.getObject();
System.out.println("--- " + user.getEmpName());
System.out.println("sadasdasdas");
}
return null;
}
30、本地查询
查询一个对象
Query query = session.createSQLQuery("select {emp.*} from emp").addEntity("emp", Emp.class);
List<Emp> list = query.list();
for (Emp emp : list) {
System.out.println(emp.getEmpName());
}
查询对个对象
Query query = session.createSQLQuery("select {emp.*},{dep.*} from emp, dep").addEntity("emp", Emp.class).addEntity("dep", Dep.class);
List list = query.list();
Object[] obj1= (Object[]) list.get(0);//得到的是Emp对象
Emp emp = (Emp) obj1[0];
System.out.println(emp.getEmpName());//得到的是Dep对象
Dep dep = (Dep) obj1[1];
System.out.println(dep.getDepName());
//有问题的:
Query query = session.createQuery("select e.empName, e.empId, d.depName, d.depId from Emp e join Dep d where d.depId = e.depId");
List<Object[]> list = query.list();
//监听器的实现没有成功
//本地查询要好好验证
, name);
- hibernate复习的笔记
- Hibernate 复习笔记一
- Hibernate 复习笔记二
- 复习hibernate笔记 1
- hibernate复习笔记1
- Hibernate复习笔记
- Hibernate复习笔记
- hibernate复习笔记
- Hibernate复习笔记(一)
- Hibernate复习笔记(二)
- Hibernate复习笔记(三)
- Hibernate复习笔记(二)---annotation的使用
- 线程复习的笔记
- Hibernate复习笔记(一)---环境搭建及第一个HelloWorld程序的实现
- hibernate 复习
- hibernate复习
- hibernate复习
- Hibernate复习
- MFC 改变控件字体大小
- 变量 内存 分配 ios iphone
- 菜鸟学 C#调用存储过程操作oracle数据库中的表
- Start AdminServer And NodeManager Using WLST
- DOM标准
- hibernate复习的笔记
- fortran学习
- UVALive 5865 Finding Bottleneck Shorstet Paths
- Linux命令整理之三:ln
- 等等
- SQL相除
- Linux下通用线程池的构建
- Flex使用Popupmanager弹出窗口的交互传值方法
- typedef和typename关键字


