hdu 1247 字典树
来源:互联网 发布:深圳市的企业数据库 编辑:程序博客网 时间:2024/05/18 20:07
字典树,又称单词查找树,Trie树,是一种树形结构,典型应用是用于统计,排序和保存大量的字符串,所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来节约存储空间,最大限度的减少无谓的字符串比较,查询效率比哈希表高。
它有三个基本性质,根节点不包含字符,除根节点外每一个节点都只包含一个字符,从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串,每个节点的所有子节点包含的字符都不相同。
它有三个基本性质,根节点不包含字符,除根节点外每一个节点都只包含一个字符,从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串,每个节点的所有子节点包含的字符都不相同。
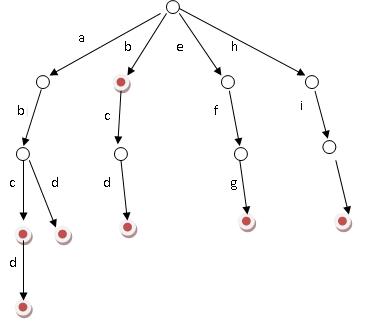
字典树的插入,删除和查找都非常简单,用一个一重循环即可。
1. 从根节点开始一次搜索
2. 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索
3. 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索
4. 迭代过程...
5. 在某个节点处,关键词的所有字母已被取出,则读取附在该节点上的信息,即完成查找
字典树的应用
1.字典树在串的快速检索中的应用。
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
2. 字典树在“串”排序方面的应用
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出
用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可
3. 字典树在最长公共前缀问题的应用
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为最近公共祖先问题(以后补上)。
下面是在网上找的一个简单的代码,忘记出处了。在这里并没有专门一个CHAR来存储字符,而是通过位置来确定是哪个字符,num = str[i] - 'a';
1. 从根节点开始一次搜索
2. 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索
3. 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索
4. 迭代过程...
5. 在某个节点处,关键词的所有字母已被取出,则读取附在该节点上的信息,即完成查找
字典树的应用
1.字典树在串的快速检索中的应用。
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
2. 字典树在“串”排序方面的应用
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出
用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可
3. 字典树在最长公共前缀问题的应用
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为最近公共祖先问题(以后补上)。
下面是在网上找的一个简单的代码,忘记出处了。在这里并没有专门一个CHAR来存储字符,而是通过位置来确定是哪个字符,num = str[i] - 'a';
题意:
题目大意:给定一些单词(按字典序给出), 按字典序输出所有满足条件的单词(条件:该单词由其它两个单词构成)
算法描述:先把所有的单词构造成一颗trie图,然后对所有的单词进行枚举,在trie图上面判断一个单词是否由其它两个单词构成,具有的做法是先沿着路径一直走,如果走到某个节点,该节点为一个单词的结尾,那么再对剩余的单词再从trie图的根开始遍历,看是否能和一个单词匹配,若匹配成功则该单词满足要求,否则继续进行匹配...
#include<iostream>#include<cstring>#include<cstdio>using namespace std;const int MAXN=26;const int MAX=50005;char word[MAX][27];struct node{ bool is; node *next[MAXN]; node() { is=false; memset(next,0,sizeof(next)); }};void Insert(node *rt,char *s){ int i=0; node *p=rt; while(s[i]) { int k=s[i++]-'a'; if(p->next[k]==NULL) p->next[k]=new node(); p=p->next[k]; } p->is=true; //该结点是单词的尾}bool Search(node *rt,char s[]){int i=0,top=0,stack[1000];node *p=rt;while(s[i]){int k=s[i++]-'a';if(p->next[k]==NULL) return 0;p=p->next[k];if(p->is && s[i]) //找到该单词含有子单词的分隔点stack[top++]=i;//入栈}while(top)//从可能的分割点去找{ bool ok=1;i=stack[--top];p=rt;while(s[i]){int k=s[i++]-'a';if(p->next[k]==NULL){ok=false;break;}p=p->next[k];}if(ok && p->is)//找到最后,并且是单词的return 1;}return 0;}int main(){ int i=0; node *rt=new node(); while(gets(word[i])) { Insert(rt,word[i]); i++;}for(int j=0;j<i;j++)if(Search(rt,word[j])) printf("%s\n",word[j]); return 0;}- hdu 1247 字典树
- hdu 1247 字典树
- hdu 1247(字典树)
- hdu 1247 字典树
- HDU 1247 字典树
- hdu 1247 字典树
- hdu 1247~~字典树
- hdu 1247 字典树
- HDU 1247 字典树
- hdu 1247 字典树
- hdu 1247 (字典树)
- 字典树 之 hdu 1247
- hdu 1247 字典树模版
- HDU 1247 Hat’s Words(字典树)
- hdu 1247 字典树 Hat’s Words
- HDU 1247 Hat’s Words 字典树
- hdu 1247 Hat’s Words 字典树
- HDU 1247 Hat’s Words(字典树)
- mysql分区
- GetVersion和GetVersionEx函数详解
- mysql 查询表出错 提示表不存在
- 二面归来
- Objective-C 将HTML转义符转换成中文汉字的方法
- hdu 1247 字典树
- 正向代理 与反向代理笔记
- poj 1861 最小生成树
- C++关键字
- 视频播放器增加color space converter + Transform Filter
- Point And Array你不知道的事
- smartupload 上传和下载文件
- android中Toast重复显示问题解决
- S3C6410开发全纪录(二)《如何计算内存大小,并在UBOOT中调整内存大小》 .


