大型电商的产品库分布式设计
来源:互联网 发布:极乐净土mmd音乐数据 编辑:程序博客网 时间:2024/04/30 05:34
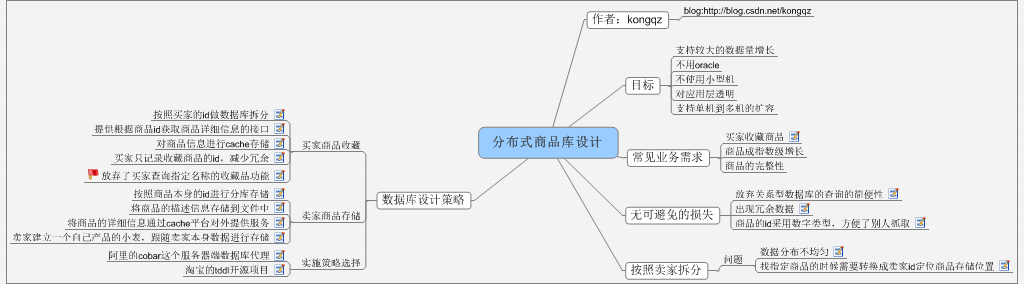
分布式商品库设计
1 作者:kongqz
1.1 blog:http://blog.csdn.net/kongqz
2 目标
2.1 支持较大的数据量增长
2.2 不用oracle
2.3 不使用小型机
2.4 对应用层透明
2.5 支持单机到多机的扩容
3 常见业务需求
3.1 买家收藏商品
一般在平台上都是在交易成功后或者买家进行收藏的时候,产生这部分数据。
3.2 商品成指数级增长
3.3 商品的完整性
4 无可避免的损失
4.1 放弃关系型数据库的查询的简便性
分库的情况下,有些关联查询,我们需要适当放弃
所以在功能设计上可能不会尽善尽美。
4.2 出现冗余数据
我们要冗余必要的关联字段进行对照查询。
4.3 商品的id采用数字类型,方便了别人抓取
用数字做主见的利弊显而易见。自增的商品将导致平台信息被抓取。
5 按照卖家拆分
5.1 问题
5.1.1 数据分布不均匀
每个卖家发布的商品数据会有所不同
5.1.2 找指定商品的时候需要转换成卖家id定位商品存储位置
查询商品的时候需要先知道商品对应的卖家,然后按照卖家id去对应的数据分区查找。
6 数据库设计策略
6.1 买家商品收藏
6.1.1 按照买家的id做数据库拆分
买家量会累积较大。按照买家的id进行数据拆分相对合理。
6.1.2 提供根据商品id获取商品详细信息的接口
这个cache方案可以参考使用淘宝的tair,如果暂时产品不多的话,可以考虑使用memache集群即可。
6.1.3 对商品信息进行cache存储
买家、卖家都需要根据id找到指定的商品。
6.1.4 买家只记录收藏商品的id,减少冗余
1、数据量较大的时候。冗余就意味着磁盘空间。
2、如果我们要支持商品名称的查询,那么折中的办法就是冗余商品名称。这样就引发一个问题,磁盘空间的增大和商品名称修改时的数据同步。在一定情况下我们可以通过消息服务器来异步处理。
6.1.5 放弃了买家查询指定名称的收藏品功能
这个功能性能相当低。跟我们的db设计结构有关。
6.2 卖家商品存储
6.2.1 按照商品本身的id进行分库存储
这个最核心的优势就是让数据存储均匀。
其次就是不需要在查询但一个的产品的时候进行一个产品和卖家的映射查询。
6.2.2 将商品的描述信息存储到文件中
尽量避免大段的数据读写通过数据库的clob和blob字段进行,通过小文件存储减轻数据库压力。
6.2.3 将商品的详细信息通过cache平台对外提供服务
因为对关系型数据库做了拆分冗余。所以这部分数据的读将暴增。为了保证系统的性能。需要将商品cache到集群中。
6.2.4 卖家建立一个自己产品的小表,跟随卖家本身数据进行存储
1、卖家量也会长期累积较大数据量,所以也需要按照自己的sellerid进行分区存储。
2、卖家发布的商品是按照商品本身的id进行分库存储的。
3、卖家需要建立一个针对自己发布的商品的小表。只存储发布的商品以及当前商品状态。
这样在系统设计中,就无法提供根据自己商品名称来查询自己的商品的数据库层次的功能。变通方式就是通过搜索引擎进行。
6.3 实施策略选择
6.3.1 阿里的cobar这个服务器端数据库代理
建议中型项目采用这种策略,配置简单,容易使用
6.3.2 淘宝的tddl开源项目
建议大型项目采用此策略。实施起来相对复杂。
BTW:有图有真相
- 大型电商的产品库分布式设计
- 大型电商的SSO设计策略
- 大型电商的订单设计概要
- 大型电商的SSO设计策略
- java系统架构-大型分布式电商项目实战
- 分布式互联网电商平台的架构设计要点
- 分布式架构设计之电商平台
- 1,大型的电商网站数据库要如何设计? 2,如何处理数据库死锁问题?
- java大型分布式电商项目实战高并发集群分布式系统架构
- 大型电商架构设计各路诸侯点评
- 如何设计一个基于云计算的大型分布式系统
- 基于WCF大型分布式系统的架构设计
- 说说大型网站分布式服务框架的设计思想
- 大型分布式系统架构设计(一)------------大型系统解决方案的演变
- 【AI-CPS OS】重磅:知识图谱在MRO工业品电商平台产品库标准化中的实际应用
- 大型SpringMVC,Mybatis,Redis,Solr,Nginx,SSM分布式电商项目视频教程下载
- 【备忘】【No8】大型SpringMVC,Mybatis,Redis,Solr,Nginx,SSM分布式电商项目视频教程
- 【备忘】大型SpringMVC,Mybatis,Redis,Solr,Nginx,SSM分布式电商项目视频教程下载
- Factory模式
- C# enum用法
- c/c++中const用法总结
- PagedGeometry笔记
- 推荐一系列优秀的Android开发源码
- 大型电商的产品库分布式设计
- js的关于验证文本框中的文本是否都是数字
- 总线设备驱动模型总结
- POJ 1236Network of Schools(tarjan)
- C#和C++中char类型的区别
- container_of()宏
- memcached svn php5.2 apache2.2集成OK(windows)
- windows搭建GoLang开发环境
- 虚拟键码对照表


