Memcached初探
来源:互联网 发布:仓廪实而知礼节的意思 编辑:程序博客网 时间:2024/06/02 07:28
我们都知道mysql有个query cache,可以缓存上次查询的结果,可实际上帮不上太多的忙,下面是mysql quety cache的不足:
1、只能有一个实例
2、意味着你能存储内容的上限就是你服务器的可用内存,一台服务器能有多少内存?你又能存多少呢?
3、只要有写操作,mysql的query cache就失效,只要数据库内容稍有改变,那怕改变的是其他行,mysql的query cache也会失效
4、mysql的query cache只能缓存数据库数据行,意味着其他内容都不行,比如数组,比如对象,而memcached理论上可以缓存任何内容,甚至文件。
Slab Allocation机制:整理内存以便重复使用
slab机制是把内存分配成大小相等的部分以减少碎片。最近的memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。而且,slab allocator还有重复使用已分配的内存的目的。也就是说,分配到的内存不会释放,而是重复利用。

the primary goal of the slabs subsystem in memcached was toeliminate memory fragmentation issues totally by using fixed-sizememory chunks coming from a few predetermined size classes.
也就是说,Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
Slab Allocation的原理相当简单。 将分配的内存分割成各种尺寸的块(chunk),并把尺寸相同的块分成组(chunk的集合)。
而且,slab allocator还有重复使用已分配的内存的目的。也就是说,分配到的内存不会释放,而是重复利用。
在给要缓存的内容分配内存的时候,需要找到最合适的那个chunk,然后分配给他:

Slab Allocator的缺点
Slab Allocator解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题。
这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。查看memcached内部状态
memcached有个名为stats的命令,使用它可以获得各种各样的信息。执行命令的方法很多,用telnet最为简单:telnet 主机名 端口号
连接到memcached之后,输入stats再按回车,即可获得包括资源利用率在内的各种信息。
使用growth factor进行调优
memcached在启动时指定 Growth Factor因子(通过-f选项),就可以在某种程度上控制slab之间的差异。默认值为1.25。但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。
让我们用以前的设置,以verbose模式启动memcached试试看:
$ memcached -f 2 -vv
下面是启动后的verbose输出:
slab class 1: chunk size 128 perslab 8192
slab class 2: chunk size 256 perslab 4096
slab class 3: chunk size 512 perslab 2048
slab class 4: chunk size 1024 perslab 1024
slab class 5: chunk size 2048 perslab 512
slab class 6: chunk size 4096 perslab 256
slab class 7: chunk size 8192 perslab 128
slab class 8: chunk size 16384 perslab 64
slab class 9: chunk size 32768 perslab 32
slab class 10: chunk size 65536 perslab 16
slab class 11: chunk size 131072 perslab 8
slab class 12: chunk size 262144 perslab 4
slab class 13: chunk size 524288 perslab 2
可见,从128字节的组开始,组的大小依次增大为原来的2倍。这样设置的问题是,slab之间的差别比较大,有些情况下就相当浪费内存。
memcached在数据删除方面有效利用资源
数据不会真正从memcached中消失。上次介绍过,memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible,透明),其存储空间即可重复使用。hibernate有懒加载机制,这里memcached有懒删除机制。Lazy Expiration,memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
LRU:从缓存中有效删除数据的原理
当memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。 从缓存的实用角度来看,该模型十分理想。
不过,有些情况下LRU机制反倒会造成麻烦。memcached启动时通过“-M”参数可以禁止LRU,如下所示:
$ memcached -M -m 1024
启动时必须注意的是,小写的“-m”选项是用来指定最大内存大小的。不指定具体数值则使用默认值64MB。
指定“-M”参数启动后,内存用尽时memcached会返回错误。 话说回来,memcached毕竟不是存储器,而是缓存,所以推荐使用LRU。
memcached的分布式
memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。 服务器端仅包括内存存储功能,其实现非常简单。 至于memcached的分布式,则是完全由客户端程序库实现的。 这种分布式是memcached的最大特点。
memcached实现的分布式是靠客户端来做的,比如说这里有三台memcached服务器,要存储一个单词,那么客户端程序先要决定将它存储在哪里,然后到相应的服务器上去存储:
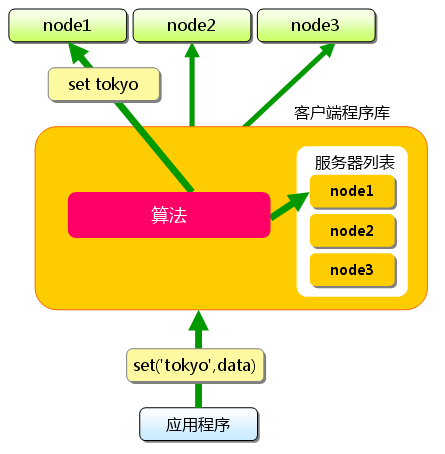
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。 函数库通过与数据保存时相同的算法,根据“键”选择服务器。 使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。 只要数据没有因为某些原因被删除,就能获得保存的值。
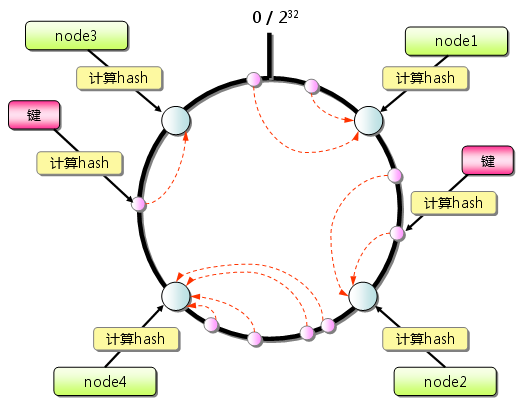
这里就有一个问题了。现在memcached服务器是三台,假设使用了取模的方式来决定使用哪台服务器,是有效的。如果三台服务器不够用了,要增加一台呢?那么现有的三台服务器上的数据都要重新取模存储了。也就是说,原来的三台的数据都无效了。这就引入了一致性哈希算法。
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
在以往的余数算法中,我们能够了解到,如果增加服务器,那么会导致所有服务器上的数据受到影响。但是在一致性哈希中,我们可以看到,增加一台服务器,受到影响的,只有这台服务器的下游那一台服务器,因为本身要映射到这个下游服务器的数据现在有一些需要映射到新增的服务去器上了。如下图:
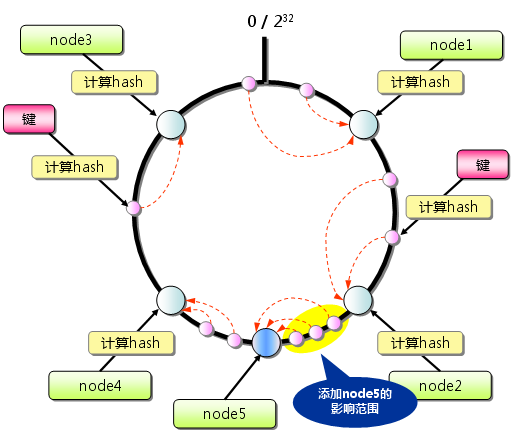
因此,Consistent Hashing最大限度地抑制了键的重新分布。
from:http://kb.cnblogs.com/page/42735/
命令总结:
在telnet中,执行以下命令
stats:查看memcached服务器情况
stats reset:清空cache中的数据
stats items:列出cache中的记录情况
在java代码中,cache.flushAll();只是把记录标记为过期,并没有删除数据,但是此时从memcached中get不到这些数据了。数据还是存在内存中的。只有在stats reset的时候,数据才被清除。
total_items的数据每次add一个item,就会增加一次,不管在这个数据是不是之前已经add过。
curr_items记录了Memcached中distinct之后的item的数量。
- Memcached初探
- Memcached初探
- Memcached初探
- Memcached初探手记
- mysql memcached 初探
- memcached内存分配及回收初探
- memcached内存分配及回收初探
- Memcache初探(一) ---- CentOS下安装memcached
- Key/Value之王Memcached初探:二、Memcached在.Net中的基本操作
- Key/Value之王Memcached初探:三、Memcached解决Session的分布式存储场景的应用
- Key/Value之王Memcached初探:一、掀起Memcached的盖头来
- Memcached
- memcached
- Memcached
- memcached
- Memcached
- memcached
- memcached
- error C2220: 警告被视为错误 - 没有生成“object”文件
- c++ vector
- FME教程--pdf下载
- ios判断邮箱是否合法的代码
- ListView 实现索引
- Memcached初探
- ebs workflow历史记录清楚程序
- 3D图形矩阵变换总结
- 黑马程序员三、多线程
- jquery中val,text,html,attr的区别
- Poj 3468 A Simple Problem with Integers 相关的8种解法
- 思考:矩阵及变换,以及矩阵在DirectX和OpenGL中的运用
- Boost 入门及其VS2005下编译boost库
- shell ip扫描


