PostgreSQL 强大的多层表继承--及其在海量数据分类按月分区存储中的应用
来源:互联网 发布:包子冷冻生坯技术 知乎 编辑:程序博客网 时间:2024/04/29 18:45
最近发现大家越来越关注 PostgreSQL了。2008年以来,通过对PostgreSQL的实际使用,发现其对象-关系数据库机制对现实问题非常有帮助。在多重表继承下,对上亿条不同类别的数据条目进行按型号、按月份双层分区管理,既可在总表查阅所有条目的共有字段,也可在各类型字表查询附加字段,非常高效。下面把这种分区机制介绍如下!
实验平台:PostgreSQL 9.1
实验背景:
假设有N种数据收集设备,分别叫做 machine1, machine2...machineN, 各类收集设备从传感器上采集的数据各不相同。但是他们都包括3个共有属性:1、采集时刻 2、一个电压值 3、机器的ID。 这些机器源源不断的从各个传感器收集信息,每类机器还有各自不同的附加数据。比如,machine1有当前最大单元数、当前已使用单元数两个属性。Machine2有前端传感器的ID和取值。数据量约100万条/天,要求数据库容纳至少5年的数据。
设计原则:
由于采集的频率高,每天会有上百万条数据存入,为了考虑缩小索引的规模,提高检索效率,采用按月分区存储。由于各类机器的字段各有区别,使得我们必须设计不同的表结构, 分别存储各类数据。由于要求能够统一检索基本信息、按需检索额外信息,我们采用PostgreSQL的表继承,首先按照机器类型分类,而后各类型机器内按照月份分类。
数据库结构:
全局ID 序列:
CREATE SEQUENCE serial_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 9223372036854775807 START 1 CACHE 1;ALTER TABLE serial_id_seq OWNER TO postgres;
该序列用于保持全局ID的唯一性。PostgreSQL各个继承表中的主键约束仅仅限于本表,在不想通过检查条件确保唯一的情况下,可以通过触发器手工从序列获取新的值,以及限制用户修改ID来保证唯一。基本表(爷爷表),承载了所有机器的共同属性
CREATE TABLE base_table( id bigint NOT NULL, dvalue double precision, sample_time timestamp with time zone, machine_code character varying(32), CONSTRAINT pk_base_table_id PRIMARY KEY (id ))WITH ( OIDS=FALSE);ALTER TABLE base_table OWNER TO postgres;CREATE INDEX idx_sample_time ON base_table USING btree (sample_time );
下面为机器类型1创建按类型分区子表(爸爸表)
CREATE TABLE base_table_machine1( max_res integer, curr_res integer, CONSTRAINT pk_base_table_machine1 PRIMARY KEY (id ))INHERITS (base_table)WITH ( OIDS=FALSE);ALTER TABLE base_table_machine1 OWNER TO postgres;CREATE INDEX idx_base_table_machine1_sample_time ON base_table_machine1 USING btree (sample_time );
同样,为机器2创建按类型分区子表
CREATE TABLE base_table_machine2( manu_id character varying(16), manu_value character varying(16), CONSTRAINT pk_base_table_machine2 PRIMARY KEY (id ))INHERITS (base_table)WITH ( OIDS=FALSE);ALTER TABLE base_table_machine2 OWNER TO postgres;CREATE INDEX idx_base_table_machine2_sample_time ON base_table_machine2 USING btree (sample_time );
其他机器不再赘述。创建完后,我们开始写创建按月分区表的触发器(儿子表)。按月分区会判断每次插入的数据的时刻,按照月份放到分区表中。如果分区表不存在,则自动创建。这里给出机器1、机器2 的触发器
-- Function: on_insert_base_table_machine1()-- DROP FUNCTION on_insert_base_table_machine1();CREATE OR REPLACE FUNCTION on_insert_base_table_machine1() RETURNS trigger AS$BODY$DECLARE --Variable Hold subtable namestr_sub_tablename varchar;--Variable Hold year\month info with timestamlestr_sub_sample_time varchar;str_sql_cmd varchar;str_sub_checkval varchar;BEGIN--The triggle func will be exectued only when BEFORE INSERTIF TG_OP <> 'INSERT' OR TG_TABLE_NAME <>'base_table_machine1' OR TG_WHEN <> 'BEFORE' THENRETURN NULL;END IF;--Generate Table Namestr_sub_sample_time = date_part('year',NEW.sample_time)::varchar || '_' || CASE WHEN date_part('month',NEW.sample_time) <10 THEN '0' ELSE '' END||date_part('month',NEW.sample_time)::varchar;str_sub_tablename = 'machine1_' || str_sub_sample_time;--Check if table not createdselect * from pg_tables where schemaname = 'public' and tablename=str_sub_tablename into str_sql_cmd;IF NOT FOUND THEN--Create table Cmdstr_sql_cmd = 'CREATE TABLE '||str_sub_tablename||' (CONSTRAINT pk_'|| str_sub_tablename||' PRIMARY KEY (id ),CONSTRAINT chk_'|| str_sub_tablename||' CHECK(date_part(''year''::text, sample_time) = '|| date_part('year',NEW.sample_time)::varchar|| '::double precision AND date_part(''month''::text, sample_time) = '|| date_part('month',NEW.sample_time)::varchar||' ))INHERITS (base_table_machine1)WITH ( OIDS=FALSE );ALTER TABLE '||str_sub_tablename||' OWNER TO postgres;CREATE INDEX idx_'|| str_sub_tablename||'_sample_timeON '|| str_sub_tablename||'USING btree (sample_time );';EXECUTE str_sql_cmd;END IF;--insert Datastr_sql_cmd = 'INSERT INTO '||str_sub_tablename||' ( id,dvalue,sample_time,machine_code,max_res,curr_res) VALUES ( nextval(''serial_id_seq''),$1,$2,$3,$4,$5);';EXECUTE str_sql_cmd USINGNEW.dvalue,NEW.sample_time,NEW.machine_code,NEW.max_res,NEW.curr_res;--return null because main table does not really contain datareturn NULL;END;$BODY$ LANGUAGE plpgsql VOLATILE COST 100;ALTER FUNCTION on_insert_base_table_machine1() OWNER TO postgres;-- Function: on_insert_base_table_machine2()-- DROP FUNCTION on_insert_base_table_machine2();CREATE OR REPLACE FUNCTION on_insert_base_table_machine2() RETURNS trigger AS$BODY$DECLARE --Variable Hold subtable namestr_sub_tablename varchar;--Variable Hold year\month info with timestamlestr_sub_sample_time varchar;str_sql_cmd varchar;str_sub_checkval varchar;BEGIN--The triggle func will be exectued only when BEFORE INSERTIF TG_OP <> 'INSERT' OR TG_TABLE_NAME <>'base_table_machine2' OR TG_WHEN <> 'BEFORE' THENRETURN NULL;END IF;--Generate Table Namestr_sub_sample_time = date_part('year',NEW.sample_time)::varchar || '_' || CASE WHEN date_part('month',NEW.sample_time) <10 THEN '0' ELSE '' END||date_part('month',NEW.sample_time)::varchar;str_sub_tablename = 'machine2_' || str_sub_sample_time;--Check if table not createdselect * from pg_tables where schemaname = 'public' and tablename=str_sub_tablename into str_sql_cmd;IF NOT FOUND THEN--Create table Cmdstr_sql_cmd = 'CREATE TABLE '||str_sub_tablename||' (CONSTRAINT pk_'|| str_sub_tablename||' PRIMARY KEY (id ),CONSTRAINT chk_'|| str_sub_tablename||' CHECK(date_part(''year''::text, sample_time) = '|| date_part('year',NEW.sample_time)::varchar|| '::double precision AND date_part(''month''::text, sample_time) = '|| date_part('month',NEW.sample_time)::varchar||' ))INHERITS (base_table_machine2)WITH ( OIDS=FALSE );ALTER TABLE '||str_sub_tablename||' OWNER TO postgres;CREATE INDEX idx_'|| str_sub_tablename||'_sample_timeON '|| str_sub_tablename||'USING btree (sample_time );';EXECUTE str_sql_cmd;END IF;--insert Datastr_sql_cmd = 'INSERT INTO '||str_sub_tablename||' ( id,dvalue,sample_time,machine_code,manu_id,manu_value) VALUES ( nextval(''serial_id_seq''),$1,$2,$3,$4,$5);';EXECUTE str_sql_cmd USINGNEW.dvalue,NEW.sample_time,NEW.machine_code,NEW.manu_id,NEW.manu_value;--return null because main table does not really contain datareturn NULL;END;$BODY$ LANGUAGE plpgsql VOLATILE COST 100;ALTER FUNCTION on_insert_base_table_machine2() OWNER TO postgres;最后,为各个爸爸表设置触发器
CREATE TRIGGER triggle_on_insert_machine1 BEFORE INSERT ON base_table_machine1 FOR EACH ROW EXECUTE PROCEDURE on_insert_base_table_machine1();
CREATE TRIGGER triggle_machine2 BEFORE INSERT ON base_table_machine2 FOR EACH ROW EXECUTE PROCEDURE on_insert_base_table_machine2();
到此为止,我们可以分别向各个爸爸表(按类型分区表)插入数据,而后通过爷爷表(总表)检索基本信息,通过爸爸表检索详细信息。对总表的操作会遍历反馈到所有子表,试图利用子表的索引进行查询。由于按月存储,插入工作只限于本月,所以检索历史数据效率很高。
当然了,这只是简单的实验,实际字段要比上述字段复杂很多。PostgreSQL的对象-关系数据库对解决上述问题非常有帮助,也全面的运用到我公司的各个环节,达到工业化标准的系统非常稳定,尽管设置了备份,但4年来从未真正用到。我们目前使用 16核心机架服务器,8GB内存,Ubuntu 12.04 LTS,优化配置(Postgresql.conf) 采用设置共享段shared_buffers 512MB, work_mem 32MB,维护maintenance_work_mem 512MB,checkpoint_segments = 16,获得了稳定而持久的生产力提升。
测试:
插入4条数据
insert into base_table_machine1 (dvalue,sample_time,machine_code,max_res,curr_res) values (22.17273,'2012-06-01 11:22:11','SC3010-192.168.1.12',1,2);insert into base_table_machine1 (dvalue,sample_time,machine_code,max_res,curr_res) values (12.8273,'2012-07-12 10:23:01','SC3010-192.168.1.14',1,2);insert into base_table_machine2 (dvalue,sample_time,machine_code,manu_id,manu_value) values (4412.1928,'2011-01-21 02:08:34','PK937-192.168.1.113','TP1','E54DF');insert into base_table_machine2 (dvalue,sample_time,machine_code,manu_id,manu_value) values (4412.1928,'2011-12-31 04:21:31','PK937-192.168.1.112','TP2','CB67D');
看看 select 语句的结果
select * from base_table;
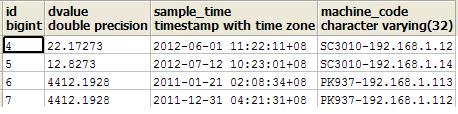
select * from base_table_machine2;

select * from base_table_machine1;

explain select * from base_table where sample_time >='2012-06-21 00:00:00' and sample_time <='2012-07-21 00:00:00';

自动使用索引关联到每个子表。
- PostgreSQL 强大的多层表继承--及其在海量数据分类按月分区存储中的应用
- PostgreSQL 强大的多层表继承--及其在海量数据分类按月分区存储中的应用
- PostgreSQL 强大的多层表继承--及其在海量数据分类按月分区存储中的应用
- PostgreSQL 强大的多层表继承--及其在海量数据分类按月分区存储中的应用
- Oracle海量数据优化-02分区在海量数据库中的应用-更新中
- 按月添加分区的存储过程
- MySQL 按月给表分区存储过程
- PostgreSQL(表的继承和分区)
- 桶排序在海量数据中的应用
- MongoDB数据库的海量数据存储应用
- mysql存储过程按月创建表分区 方式一
- mysql存储过程按月创建表分区 方式二
- 一道SQL题...(关于树型结构的在关系表中的存储及其应用处理)
- PostgreSQL学习手册(表的继承和分区)
- PostgreSQL学习笔记3之表的继承和分区
- PostgreSQL学习手册(表的继承和分区)
- PostgreSQL学习手册(表的继承和分区)
- PostgreSQL学习手册(表的继承和分区)
- 第12章多态
- 关于匈牙利算法+二分匹配和KM算法的链接
- 网络流专辑 转自notonlysuccess
- Cannot create a server using the selected type (Eclipse中新建一个服务器)
- n阶幻方
- PostgreSQL 强大的多层表继承--及其在海量数据分类按月分区存储中的应用
- ASIHTTPRequest类库简介和使用说明
- 《JAVA与模式》之责任链模式
- 实时操作系统的特点
- 2011——2012年度总结
- android面试题整理 .
- java 时间格式转换
- 比较容易理解的iPhone多视图
- Android四大组件


