计数排序
来源:互联网 发布:慈溪行知职高 编辑:程序博客网 时间:2024/05/16 05:03
曾经在一个不是很正式的面试中,被问到一个问题:怎么对1亿个数字进行排序?当时没加思索就答:快排。毕竟以有限的知识,只能想到伟大的快排了。又被追问,在1亿的数量级下,lgn也是不小的开支,况且是乘,对吧?最后知道答案是计数排序,那疑问就是,它真的有这么快吗?下面就开始美好的学习吧。
首先,我们将比较排序抽象的视为决策树,一颗决策树是满二叉树(in fact,显然不是,因为只能保证除叶子节点外的每个节点都有2个子节点,但是没法保证所有叶子节点都在最后一层,所以没法达到满的状态,这点上同意TankyWoo)以书上决策树为例:
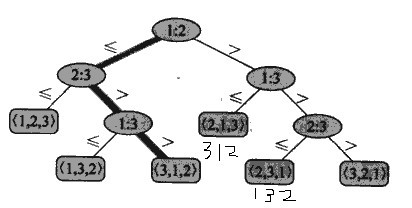 虽然这棵树有俩地方不是按常理从大到小,不过不影响整体效果。
虽然这棵树有俩地方不是按常理从大到小,不过不影响整体效果。
为什么要引入决策树呢,是为了说明,各元素的顺序基于输入元素间比较的这种排序,即比较排序,在最坏情况下需要Ω(nlgn)次比较来进行排序。然后引入几个个排序时间为Θ(n)的排序算法。
从决策树可以看到,要使排序算法能正确地工作,必要条件是n个元素的n!种排列中的每一种都要作为决策树的一个叶子而出现。(当然啦,不到叶子,什么都不输出,那还排什么呢?)从树上还能看到,一个比较排序的最坏情况比较次数,是和决策树的高度相等的。
证明过程如下:

从这个结果来看,堆排序和归并排序是渐进最优的了。
下面正式进入计数排序的学习。
计数排序的基本思想,是对每一个输入元素x,确定出小于x的元素个数。发现了吗?这计数排序就根本不基于比较,蛋疼了吧,直接就超越Θ(nlgn)的下界了,颤抖吧,凡人。
计数排序的一个实现程序如下:
- //============================================================================
- // Name : Count.cpp
- // Author : xia
- // Copyright : NUAA
- // Description : 计数排序的实现
- //============================================================================
- #include <iostream>
- #include <vector>
- #include <algorithm>
- #include <ctime>//rand()
- #include <iomanip>//setw
- #include <climits>//INT_MIN
- using namespace std;
- const int MAX = 1000;
- void CountSort(vector<int> &A , vector<int> &B , int k)
- {
- //for i<-0 to k , C[i]<-0
- vector<int> C(k+1);//初始化为0
- int i;
- for ( i=1 ; i<A.size() ; i++)//C[i]包含等于i的个数
- C[A[i]] = C[A[i]] + 1 ;
- for ( i=1 ; i<=k ; i++)//C[i]包含小于或等于i的元素个数
- C[i] = C[i] + C[i-1];
- for ( i=A.size()-1 ; i>0 ; i--)
- {
- B[C[A[i]]] = A[i] ;
- C[ A[i] ] --;
- }
- }
- int main(int argc, char **argv)
- {
- vector<int> v;
- int i,k=0;
- srand((unsigned)time(NULL));
- for ( i=0 ; i<MAX ; i++)
- {
- v.push_back(rand()%100);//为了造成足够重复数,体现计数
- if (v[i] > k)
- k = v[i] ;
- }
- v.insert(v.begin(),INT_MIN);//插入个负无穷,0位置不用
- vector<int> result(v); //用result来保存结果
- CountSort(v,result,k);
- for (i=1 ; i<result.size() ; i++)
- {
- cout << setw(3) << result[i];
- if (i%25 == 0)
- cout << endl;
- }
- return 0;
- }
//============================================================================// Name : Count.cpp// Author : xia// Copyright : NUAA// Description : 计数排序的实现//============================================================================#include <iostream>#include <vector>#include <algorithm>#include <ctime>//rand()#include <iomanip>//setw#include <climits>//INT_MINusing namespace std;const int MAX = 1000;void CountSort(vector<int> &A , vector<int> &B , int k){//for i<-0 to k , C[i]<-0vector<int> C(k+1);//初始化为0int i;for ( i=1 ; i<A.size() ; i++)//C[i]包含等于i的个数C[A[i]] = C[A[i]] + 1 ;for ( i=1 ; i<=k ; i++)//C[i]包含小于或等于i的元素个数C[i] = C[i] + C[i-1];for ( i=A.size()-1 ; i>0 ; i--){B[C[A[i]]] = A[i] ;C[ A[i] ] --;}}int main(int argc, char **argv){vector<int> v; int i,k=0;srand((unsigned)time(NULL));for ( i=0 ; i<MAX ; i++){v.push_back(rand()%100);//为了造成足够重复数,体现计数if (v[i] > k)k = v[i] ;}v.insert(v.begin(),INT_MIN);//插入个负无穷,0位置不用vector<int> result(v); //用result来保存结果CountSort(v,result,k);for (i=1 ; i<result.size() ; i++){cout << setw(3) << result[i];if (i%25 == 0)cout << endl;}return 0;} 计数排序的精髓,在于引入计数的数组C[k+1],在第一次将CountSort的前2个循环执行完后,对每个A[i],C[A[i]]即为A[i]在输出数组上的最终位置,in为共有C[A[i]]个元素小于等于A[j],由于每个元素可能不一定不同,所以每将一个值A[i]放入数组B时,都要减少C[A[i]]的值。不过说实话,看到
- B[C[A[i]]] = A[i] ;
计数排序,第一个for消耗Θ(k),第二个for消耗Θ(n),第三个for消耗Θ(k),第四个for消耗Θ(n),那总共消耗就是 Θ(n)。所以,在时间中,当k=O(n),常常采用计数排序,这个时候运行时间为Θ(n)。
本例的运行结果如下:
其实理论上, 我们对于A和B的0元素也是可以使用的,这里为了切合源代码,弃之不用,插入个负无穷数字,当我们采用0元素时,即如下所示时:
- void CountSort(vector<int> &A , vector<int> &B , int k)
- {
- vector<int> C(k+1);//初始化为0
- int i;
- for ( i=1 ; i<A.size() ; i++)//C[i]包含等于i的个数
- C[A[i]] = C[A[i]] + 1 ;
- for ( i=1 ; i<=k ; i++)//C[i]包含小于或等于i的元素个数
- C[i] = C[i] + C[i-1];
- for ( i=A.size()-1 ; i>=0 ; i--)
- {
- B[C[A[i]]] = A[i] ;
- C[ A[i] ] --;
- }
- }
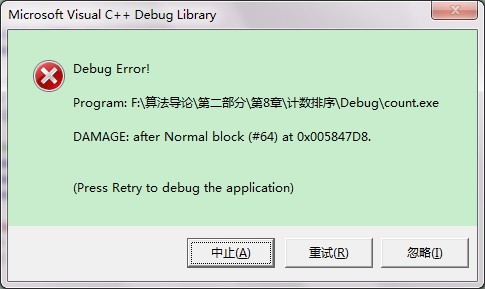
void CountSort(vector<int> &A , vector<int> &B , int k){vector<int> C(k+1);//初始化为0int i;for ( i=1 ; i<A.size() ; i++)//C[i]包含等于i的个数C[A[i]] = C[A[i]] + 1 ;for ( i=1 ; i<=k ; i++)//C[i]包含小于或等于i的元素个数C[i] = C[i] + C[i-1];for ( i=A.size()-1 ; i>=0 ; i--){B[C[A[i]]] = A[i] ;C[ A[i] ] --;}}也能输出最终结果。不过最上面的程序和这个,有时候都会出这个错,概率现象呢么?不解,莫非是重复删除内存空间了?先不管吧。
另外,由于C数组下标 i 就是A 的值,所以我们不需要保留A中原来的数了,可以考虑u如下代码实现,好处是减少了一个数组B
- void CountSort(vector<int> &A , int k)
- {
- vector<int> C(k+1);//初始化为0
- int i;
- for ( i=1 ; i<A.size() ; i++)//C[i]包含等于i的个数
- C[A[i]] = C[A[i]] + 1 ;
- int z=1;
- for (i=0 ; i<=k ; i++)
- {
- while (C[i]-- > 0)
- A[z++] = i;
- }
- }
void CountSort(vector<int> &A , int k){vector<int> C(k+1);//初始化为0int i;for ( i=1 ; i<A.size() ; i++)//C[i]包含等于i的个数C[A[i]] = C[A[i]] + 1 ;int z=1;for (i=0 ; i<=k ; i++){while (C[i]-- > 0)A[z++] = i;}}参考自:http://www.cnblogs.com/eaglet/archive/2010/09/16/1828016.html。经验证,结果正确且不崩。
另外,可以参考http://www.cppblog.com/tanky-woo/archive/2011/04/24/144890.html,TankyWoo的代码,他的数组是用全局保存,所以没有传参过程,测试案例为书上P99页的图,也比较具体。
与快速排序的比较结果,是比较惊人
vc6下:
1w
10w
100w
快速排序
10
127
1048
计数排序
3
31
309
gcc下:
1w
10w
100w
快速排序
3
24
288
计数排序
0
4
39
看到这个结果,我很受伤。难道这就是传说中的“所谓一山还有一山高”吗?
本节最后,还能看到计数排序的重要性质是它的稳定的:具有相同值的元素在输出中的相对次序与在输入数组中的次序相同。那么,在怎么保证稳定性的呢?应该是最后一个for循环从length[A]减到1,而且C[A[i]]--构成,因为在第二个for中加入A元素的时候,从小到大,可以看做一个入栈和出栈的过程,保证了相同元素的相同位置。计数排序的稳定性对基数排序的正确性,是非常关键的,等着看看吧,嘿嘿。。。
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 计数排序
- 20120904-加载MSComm控件的方法
- 基数排序、桶排序
- eXosip入门(一):vs2008编译osip/eXosip
- exit
- C++学习笔记之——c++多态性的类指针总结
- 计数排序
- Java程序员应该知道的10个调试技巧
- Power of Cryptography 数学题 注意double能表示的最大范围
- Perl For Window
- ARM状态和Thumb状态间的切换
- Factstone Benchmark hoj 数学题
- eXosip入门(二):osip库的验证
- Gcov单元测试覆盖率
- PHP常用开发函数解析之数组篇


