Apache Hadoop: Best Practices and Anti-Patterns
来源:互联网 发布:易企秀是什么软件 编辑:程序博客网 时间:2024/05/21 09:26
Apache Hadoop is a software framework to build large-scale, shared storage and computing infrastructures. Hadoop clusters are used for a variety of research and development projects, and for a growing number of production processes at Yahoo!, EBay, Facebook, LinkedIn, Twitter, and other companies in the industry. It is a key component in several business critical endeavors representing a very significant investment and technology component. Thus, appropriate usage of the clusters and Hadoop is critical in ensuring that we reap the best possible return on this investment.
This blog post represents compendium of best practices for applications running on Apache Hadoop. In fact, we introduce the notion of aGrid Pattern which, similar to a Design Pattern, represents a general reusable solution for applications running on the Grid.
This blog post enumerates characteristics of well behaved applications and provides guidance on appropriate uses of various features and capabilities of the Hadoop framework. It is largely prescriptive in its nature; a useful way to look at this document is to understand that applications that follow, in spirit, the best practices prescribed here are very likely to be efficient, well-behavedin the multi-tenant environment of the Apache Hadoop clusters, and unlikely to fall afoul of most policies and limits.
This blog post also attempts to highlight some of the anti-patterns for applications running on the Apache Hadoop clusters.
Overview
Applications processing data on Hadoop are written using the Map-Reduce paradigm.
A Map-Reduce job usually splits the input data-set into independent chunks, which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
Map-Reduce applications specify the input/output locations and supply map and reduce functions via implementations of appropriate Hadoop interfaces, such as Mapper and Reducer. These, and other job parameters, comprise the job configuration. The Hadoop job client then submits the job (jar/executable, etc.) and configuration to the JobTracker, which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
The Map/Reduce framework operates exclusively on <key, value> pairs — that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
Here is the typical data-flow in a Map-Reduce application:
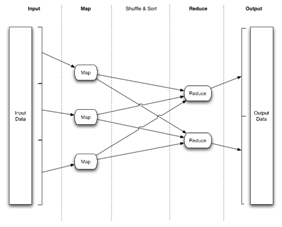
The vast majority of Map-Reduce applications executed on the Grid do not directly implement the low-level Map-Reduce interfaces; rather they are implemented in a higher-level language, such asPig.
Oozie is the preferred workflow management and scheduling solution on the Grid. Oozie supports multiple interfaces for applications (Hadoop Map-Reduce, Pig, Hadoop Streaming, Hadoop Pipes, etc.) and supports scheduling of applications based on either time or data-availability.
Grid Patterns
This section covers the best practices for Map-Reduce applications running on the Grid.
Input
Hadoop Map-Reduce is optimized to process large amounts of data. The maps typically process data in an embarrassingly parallel manner, typically at least 1 HDFS block of data, usually 128MB.
- By default, the framework processes at most 1 HDFS file per-map. This means that if an application needs to processes a very large number of input files, it is better to process multiple files per-map via a special input-format such as MultiFileInputFormat. This is true even for applications processing a small number of tiny input files, processing multiple files per map is significantly more efficient.
- If the application needs to process a very large amount of data, even if they are present in large-sized files, it is more efficient to process more than 128MB of data per-map (see section on Maps).
Grid Pattern: Coalesce processing of multiple small input files into smaller number of maps and use larger HDFS block-sizes for processing very large data-sets.
Maps
The number of maps is usually driven by the total size of the inputs, that is, the total number of blocks of the input files. Thus, if you expect 10TB of input data and have a block-size of 128MB, you'll end up with 82,000 maps.
Task setup takes awhile, so it is best if the maps take at least a minute to execute for large jobs.
As explained in the section above on input of applications, it is more efficient to process multiple-files per map for jobs with very large number of small input files.
Even if an application is processing large input files, such that each map is processing a whole HDFS block of data, it is more efficient to process large chunks of data per-map. For example, one way to process more data per map is to have the application process input data with larger HDFS block size, e.g., 512M or even higher, if appropriate.
As an extreme example the Map-Reduce development team used ~66,000 maps to accomplish the PetaSort, that is, 66,000 maps to process 1PB of data (12.5G per map).
The bottom-line is that having too many maps or lots of maps with very short run-time is anti-productive.
Grid Pattern: Unless the application's maps are heavily CPU bound, there is almost no reason to ever require more than 60,000-70,000 maps for a single application.
Also, when processing larger blocks per-map, it is important ensure they have sufficient memory for the sort-buffer to speed up the map-side sort (please see the documentation for io.sort.mband io.sort.record.percent). The performance of the application can improve dramatically if it can be arranged such that the majority of the map-output can be held in the map's sort-buffer, this will entail larger heap-sizes for the map JVM. It is important to remember that the in-memory footprint of deserialized input might significantly vary from the on-disk footprint; for example, certain class of Pig applications result in 3x-4x blow up of on-disk data in-memory. In such cases, applications might need significantly large heap-sizes for the JVM to ensure the map-input-records and map-output-records can be kept in memory.
Grid Pattern: Ensure maps are sized so that all of map-outputs can be sorted in one pass by keeping all of them in the sort-buffer.
Having the right number of maps has the following advantages for applications:
- It reduces the scheduling overhead; having fewer maps means task-scheduling is easier and availability of free-slots in the cluster is higher.
- It means the map-side is more efficient; provided there is sufficient memory to accommodate the map-outputs in the sort-buffer in the map.
- It reduces the number of seeks required to shuffle the map-outputs from the maps to the reduces — remember that each map produces output for each reduce, thus the number of seeks is
m * rwhere m is #maps and r is #reduces. - Each shuffled segment is larger, resulting in reducing the overhead of connection-establishment when compared to the 'real' work done, that is, moving bytes across the network.
- It means that the reduce-side merge of the sorted map-outputs is more efficient, since the branch-factor for the merge is lesser, that is, fewer merges are needed since there are fewer sorted segments of map-outputs to merge.
The caveat to the above guidelines is that processing too much data per-map is bad for failure recovery, a single failed map might hurt the latency of the application.
Grid Pattern: Applications should use fewer maps to process data in parallel, as few as possible without having really bad failure recovery cases.
Combiner
Applications, which use Combiners appropriately, reap benefits of the map-side aggregation effected by them. The primary benefit of the Combiner is that, when used appropriately, it significantly cuts down the amount of data shuffled from the maps to the reduces.
Shuffle
Applications that use Combiners appropriately reap benefits of the map-side aggregation effected by them. The primary benefit of the Combiner is that, when used appropriately, it significantly cuts down the amount of data shuffled from the maps to the reduces.
It is important to remember that Combiner has a performance penalty since it entails an extra serialization/de-serialization of map-output records. Applications that cannot aggregate the map-output bytes by 20-30% should not be using combiners. Applications can use the combiner input/output records counters to measure the efficacy of the Combiner.
Grid Pattern: Combiners help the shuffle phase of the applications by reducing network traffic. However, it is important to ensure that the Combiner does provide sufficient aggregation.
Reduces
The efficiency of reduces is driven by a large extent by the performance of the shuffle.
The number of reduces configured for the application (r) is, obviously, a crucial factor.
Having too many or too few reduces is anti-productive:
- Too few reduces cause undue load on the node on which the reduce is scheduled — in extreme cases we have seen reduces processing over 100GB per-reduce. This also leads to very bad failure-recovery scenarios since a single failed reduce has a significant, adverse, impact on the latency of the job.
- Too many reduces adversely affects the shuffle crossbar. Also, in extreme cases it results in too many small files created as the output of the job — this hurts both the NameNode and performance of subsequent Map-Reduce applications who need to process lots of small files.
Grid Pattern: Applications should ensure that each reduce should process at least 1-2 GB of data, and at most 5-10GB of data, in most scenarios.
Output
A key factor to remember is that the number of output artifacts of an application is linear w.r.t the number of configured reduces. As discussed in the section on reduces, picking the right number of reduces is very important.
Some other factors to consider:
- Consider compressing the application's output with an appropriate compressor (compression speed v/s efficiency) to improve HDFS write-performance.
- Do not write out more than one output file per-reduce, using side-files is usually avoidable. Typically applications write small side-files to capture statistics and the like; counters might be more appropriate if the number of statistics collected is small.
- Use an appropriate file-format for the output of the reduces. Writing out large amounts of compressed textual data with a codec such as zlib/gzip/lzo is counter-productive for downstream consumers. This is because zlib/gzip/lzo files cannot be split and processed and the Map-Reduce framework is forced to process the entire file in a single map, in the downstream consumer applications. This results in a bad load imbalance and failure recover scenarios on the maps. Using file-formats such as SequenceFile or TFile alleviates these problems since they are both compressed and splittable.
- Consider using a larger output block size (
dfs.block.size) when the individual output files are large (multiple GBs).
Grid Pattern: Application outputs to be few large files, with each file spanning multiple HDFS blocks and appropriately compressed.
Distributed Cache
DistributedCache distributes application-specific, large, read-only files efficiently. DistributedCache is a facility provided by the Map/Reduce framework to cache files (text, archives, jars and so on) needed by applications. The framework will copy the necessary files to the slave node before any tasks for the job are executed on that node. Its efficiency stems from the fact that the files are only copied once per job and the ability to cache archives which are un-archived on the slaves. It can also be used as a rudimentary software distribution mechanism for use in the map and/or reduce tasks. It can be used to distribute both jars and native libraries and they can be put on the classpath or native library path for the map/reduce tasks.
The DistributedCache is designed to distribute a small number of medium-sized artifacts, ranging from a few MBs to few tens of MBs. One drawback of the current implementation of the DistributedCache is that there is no way to specify map or reduce specific artifacts.
In rare cases, it might be more appropriate for the tasks themselves to do the HDFS i/o to copy the artifacts than rely on the DistributedCache, for example, if an application has a small number of reduces and need very large artifacts (e.g. greater than 512M) in the distributed-cache.
Grid Pattern: Applications should ensure that artifacts in the distributed-cache should not require more i/o than the actual input to the application tasks.
Counters
Counters represent global counters, defined either by the Map/Reduce framework or applications. Applications can define arbitrary Counters and update them in the map and/or reduce methods. These counters are then globally aggregated by the framework.
Counters are appropriate for tracking few, important, global bits of information. They are definitely not meant to aggregate very fine-grained statistics of applications.
Counters are very expensive since the JobTracker has to maintain every counter of every map/reduce task for the entire duration of the application.
Grid Pattern: Applications should not use more than 10, 15 or 25 custom counters.
Compression
Hadoop Map-Reduce provides facilities for the application-writer to specify compression for both intermediate map-outputs and the output of the application, that is, output of the reduces.
- Intermediate Output Compression: As explained in the section on shuffle, compression of the intermediate map-outputs with an appropriate compression codec yields better performance by saving on network traffic between the maps and the reduces. Lzo is a reasonably optimal choice for compressing map-outputs since it provides reasonable compression at very high CPU efficiencies.
- Application Output Compression: As explained in the section on application output, compression of the outputs with an appropriate compression codec and file-format yields better latency for application. Zlib/Gzip might be an appropriate choice in a majority of cases since it provides high compression at reasonable speeds; bzip2 is usually too slow to be used.
Total Order Outputs
Sampling
Occasionally, applications need to produce totally ordered output, that is, fully-sorted. In such cases, a common anti-pattern is for applications is to use a single-reducer, forcing a single, global aggregation. Clearly, it is very inefficient - this not only puts a significant amount of load on the single node on which the reduce task is executing, but also has very bad failure recovery.
A much better approach is to sample the input and use that to drive a sampling partitioner rather than the default hash partitioner. Thus, one can derive benefits of better load balancing and failure recovery.
Joining Fully Sorted Data-Sets
Another design pattern on the Grid concerns the join of two fully-sorted data-sets whose cardinality is not an exact multiple of the other; for example, one data-set has 512 buckets while the other has 200 buckets.
In such cases, ensuring the input data-sets have a total-order (as described in the previous section) means that the application can use the cardinality of either of the data-sets i.e. 512 or 200 buckets in the above example. Pig handles these joins in the efficient manner described here.
HDFS Operations & JobTracker Operations
The NameNode is a precious resource, applications need to be careful about performing HDFS operations in the Grid. In particular, applications are discouraged from doing non-I/O operations, that is, metadata operations such as stat'ing large directories, recursive stats, and more, from the map/reduce tasks at runtime.
Similarly, applications should not contact the JobTracker for cluster statistics, etc., from the backend.
Grid Pattern: Applications should not perform any metadata operations on the file-system from the backend, they should be confined to the job-client during job-submission. Furthermore, applications should be careful not to contact the JobTracker from the backend.
User Logs
The user task-logs, that is, stdout and stderr, of map/reduce tasks are stored on the local-disk of the compute node on which the task is executed.
Since the nodes are part of the shared infrastructure the Map-Reduce framework implements limits on the amount of task-logs stored on the node.
Web-UI
The Hadoop Map-Reduce framework provides a rudimentary web-ui to track the running jobs, their progress, history of completed jobs, and so on, via the JobTracker.
It is important to remember that the web-ui is meant to be used for humans and not for automated processes.
Implementing automated processes to screen-scrape the web-ui is strictly prohibited. Some parts of the web-ui, such as browsing of job-history, are very resource-intensive on the JobTracker and could lead to severe performance problems when they are screen-scraped.
If there is a need for automated statistics gathering it is better to consult the Grid Solutions, Grid SE, or the Map-Reduce development teams.
Workflows
Oozie is the preferred workflow-management and scheduling system for the Grid. Oozie manages workflows and provides scheduling either based on time or availability of data. Increasingly, latency sensitive production job pipelines are being scheduled and managed through Oozie.
A key factor to keep in mind when designing Oozie workflows is that Hadoop is better suited for batch processing of very large amounts of data. As such, it is advisable for workflows to be comprise of fewer number of medium-to-large sized Map-Reduce jobs, in terms of processing, rather than large number of small Map-Reduce jobs. As an extreme case we have seen single workflows consisting of hundreds and thousands of jobs. This is an obvious anti-pattern. The Hadoop framework, currenty, is not really suited for pipelines of this nature. It would be better tocollapse these hundreds/thousands of Map-Reduce jobs into fewer jobs crunching more data — this will help both performance and latency of the workflows.
Grid Pattern: A single Map-Reduce job in a workflow should process at least a few tens of GB of data.
Anti-Patterns
This section attempts to cover some of the common anti-patterns of applications running on the Grid. These are, usually, not in keeping with the spirit of a large-scale, distributed, batch, data processing system.
This is meant to be a warning to the application developers since the Grid software stack is beinghardened, particularly in the upcoming 20.Fred release, and the Grid stack will be less forgiving of transgressions to the point of rejecting applications which exhibit some of the anti-patterns described here:
- Applications not using a higher-level interface such as Pig unless really necessary.
- Processing thousands of small files (sized less than 1 HDFS block, typically 128MB) with one map processing a single small file.
- Processing very large data-sets with small HDFS block size, that is, 128MB, resulting in tens of thousands of maps.
- Applications with a large number (thousands) of maps with a very small runtime (e.g., 5s).
- Straightforward aggregations without the use of the Combiner.
- Applications with greater than 60,000-70,000 maps.
- Applications processing large data-sets with very few reduces (e.g., 1).
- Pig scripts processing large data-sets without using the PARALLEL keyword
- Applications using a single reduce for total-order amount the output records
- Applications processing data with very large number of reduces, such that each reduce processes less than 1-2GB of data.
- Applications writing out multiple, small, output files from each reduce.
- Applications using the DistributedCache to distribute a large number of artifacts and/or very large artifacts (hundreds of MBs each).
- Applications using tens or hundreds of counters per task.
- Applications performing metadata operations (e.g. listStatus) on the file-system from the map/reduce tasks.
- Applications doing screen scraping of JobTracker web-ui for status of queues/jobs or worse, job-history of completed jobs.
- Workflows comprising hundreds or thousands of small jobs processing small amounts of data.
- Apache Hadoop: Best Practices and Anti-Patterns
- Ajax Patterns and Best Practices
- Core J2EE patterns: best practices and design strategies
- J2EE Best Practices: Java Design Patterns, Automation, and Performance
- Core Security Patterns : Best Practices and Strategies for J2EE(TM), Web Services, and Identity Mana
- Java EE and .NET Interoperability: Integration Strategies, Patterns, and Best Practices
- SharePoint Patterns and Practices 简介
- Pro Java™ EE Spring Patterns: Best Practices and Design Strategies Implementing Java EE Patter
- JSP Examples and Best Practices
- Achievements and Gamerscore: Best Practices
- 《Agile Software Development: Principles, Patterns, and Practices》
- Agile Principles, Patterns, and Practices in C#
- Principles of Service Design: Service Patterns and Anti-Patterns
- 10 Best Practices for Apache Hive
- 《Web 2.0 Principles and Best Practices》
- Best Practices and Requirements for OpenSolaris development
- Advanced Ajax: Architecture and Best Practices
- C++ AMP: Introduction and Best Practices
- web开发状态码合集
- android 在屏幕中隐藏标题栏和状态栏
- 选择排序(直接、堆)
- 我们都一样
- 常用正则表达式汇总
- Apache Hadoop: Best Practices and Anti-Patterns
- Use Microsoft SharePoint Designer 2010 to customize the list view 1
- Netty的ChannelBuffers
- js页面自动跳转
- 探索 Jsoup开源项目,深入解析技术点.(我认为他是一个非常好而很容易上手的工具)
- c++中友元函数访问私有变量及函数
- HDU 1856
- JavaScript世界的一等公民 - 函数(三)
- 使用 Eclipse 的 Maven 2 插件开发一个 JEE 项目


