Linux Kernel系列
来源:互联网 发布:touch捏脸数据女 编辑:程序博客网 时间:2024/06/05 19:02
Linux Kernel系列一:开篇和Kernel启动概要
前言
最近几个月将Linux Kernel的大概研究了一下,下面需要进行深入详细的分析。主要将以S3C2440的一块开发板为硬件实体。大概包括如下内容:
1 bootloader分析,以uboot为主,结合具体开发板的情况。我的目标是解释清楚uboot的工作原理(说实话,分析过程中不太想被硬件绑架,但是需要以一个实际的例子
来做分析)
2 kernel部分,这就很多内容了。打算从kernel启动的流程开始分析。
3 除kernel本身外,还有很多的知识,例如ld的输入script分析等,这里会一起介绍。
kernel启动流程概要
一:内核Image的组成
1 ES(Embed System)启动的时候,CPU加电,执行的第一条语句是Bootloader,这个非常类似PC机上的BIOS。BL将内核加载后,控制器移交给LK
2 LK执行的第一条语句是什么?vmlinux是单体的内核表示。根据前面说的内核编译连接知识,第一条语句是head.S中(历史原因,MD,有很多文件都叫head.S)
我们需要重新分析一下内核(这里就是zImage了)的组成,(方法很简单,研究make的执行过程,通过make V=1 zImage可以得到几乎全部信息)
- vmlinux,这个是未压缩、未strip的内核模块,ELF结构
- Image:二进制、未压缩、但是strip后的内核
- head.o:ARM相关的,由BL将控制权转交给它。即前面提到的head.S生成
- pigg.gz:Image文件的gzip压缩
- piggy.o:由piggy.S生成,这个S文件通过include Bin方式将Image包含进来。piggy的意思就是背负、肩扛。很形象不是?
- misc.o:从上面看,涉及到一些解压方面的内容,而misc提供一些辅助函数
- vmlinux:悲催.....这个文件是head+pigg+misc构成的vmlinux。名字一样不是?真的很混淆!
- zImage:再由上面这个vmlinux压缩而来
图1很好得展示了这个过程。
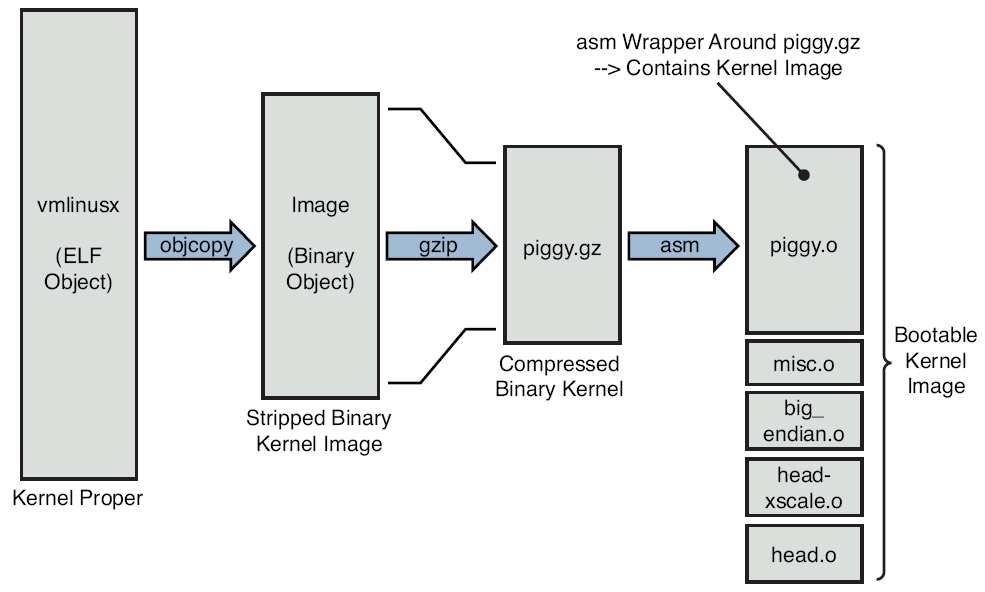
图1 内核的构成
3 piggy的故事
piggy.S很有意思,建立了一个section,并且有一个标志来指示piggy.gz的边界。
piggy对应的是一个叫bootstrap的image,注意,Bootstrap和Bootloader不一样,它是在BL之后的一段代码,用来
解压kernel,设置内存等作用。也可以叫second stage boot。
4 Bootloadre和BootstrapLoader
BL和BSL的区别是什么?
- BL只是初始化硬件,不依赖linux,不处理linux
- BSL在BL后执行,依赖linux,因为要解压linux。另外一个重要点就是BSL需要为LINUX的运行建立环境
BSL的工作包括:
- head.O:初始化CPU等工作
- misc.O:解压,重定位(例如将kernel移动到另外一个位置上) decompress_kernel
- 其他工作
init/main.c:start_kernel
启动调用图见图2.

2 启动调用流程图
下面来分析这个启动流程
1 kernel中的head.o分析:尽量保持CPU系列的通用,例如arm的CPU等初始化都在做。但是具体板子(例如CPU+其他硬件)怎么初始化?这就是由mach目录中的初始化函数做到的。所以,kernel初始化分为:generic CPU初始化+具体板子的初始化。head.o初始化后,跳转到main.o的start_kernel,继续后面的流程
2 start_kernel:(init/main.c):start_kernel的转移由head.O做的,不过代码一般包含在更通用的head_common.S中
以后想做kernel的分析,就从main开始吧. start_kernel做了什么事情呢?
- 刚才只是初始化了cpu相关的,而具体和板子相关的由start_arch执行
3 kernel 参数分析:kernel command line。注意,这个参数是由BL传递给kernel的,不过这个参数又是谁设置的呢?又存在什么地方呢?这个line放在一个global的地方,
另外,kernel如何处理这些参数呢?有一个比较好的办法,__set_up宏,将一些参数和对应的函数指针存在一个特殊的section中,然后循环调用这个section中的函数。(和驱动module中的很像)。定义在init.h中。关于一些特殊参数的取值,在arch/arm/kernel/vmlinux.lds.S中定义。(以后得去看看ld的manual了)__set_up这个宏还有一个flags比如early,表示处理阶段是否在early-stage做。标志有__init的section最终占用的内存会被抛弃..
4 子系统初始化:包括中断、等。?section嵌套section?
5 kernel_init进程:start_kernel最后会fork一个kernel_init进程,而原执行进程变成idle进程了..
6 用户空间的init进程:由kernel_init进程最终通过execve init完成
7 参考文献。ELP这本书给的参考文献都巨强..
Linux Kernel 2:用户空间的初始化 .
分类: Linux Kernel系列 2011-08-21 22:39 1424人阅读 评论(0) 收藏 举报
上篇我们知道,kernel初始化后将启动init进程,那么这个进程将干些什么呢?除此之外,kernel还需要做些什么事情呢?(想想文件系统、根存储设备是在什么时候初始化的呢?)
先从文件系统初始化说起。以前一直不明白,有了kernel为何还需要一个文件系统?经过反复琢磨,明白一个道理,kernel加载到内存后,kernel运行起来是没有问题的,但是如果没有Root FS,就好像PC上没有硬盘.....。另外,Linux中很多虚拟文件系统(proc,sys,dev等)都是挂靠在RootFS中的,所以RootFS在Linux中更加关键(必要条件简直就是)。(kernel中的FS是另外一个庞大的部分)
一 根文件系统
1 FHS:File system Hierachy Standard:Linux上文件系统布局的标准,例如 usr目录大概是干吗的,tmp目录大概是干嘛的。有空可以瞧瞧....其实使用LINUX OS多了,自然就理解了。
2 常用的文件夹布局:其实就是ES上普遍的文件目录:
•bin;dev;etc;home;lib;sbin;tmp;usr;var;
二 Post Boot
这里讲的是execve init之前的事情,因为源码中:
•run_init_process("/usr/bin/init"):这个时候已经有FS的布局了,也就是init程序本身必须放在一个FS中。
三 init
init进程很重要,不过android上的init进程的工作流程比较简单。这里介绍非Android上的init。一般它读取的配置文件是/etc/inittab中(ubuntu上似乎没有这个文件了,以后得找个FCore的系统看看)。
另外,这里还有一个叫run level的概念。见图1.
图1 run level
Run level说白了就是将系统运行状态分成几个级别,例如shutdown的时候init需要执行一些操作,reboot的时候需要执行一些操作。
这里关于Init的东西就不介绍了,很多关于linux系统配置的知识都有涉及。(确实比android的init要复杂多了)
四 Initial RAM Disk
LK在早期初始化的过程中,需要mount一个FS,目前有新旧两种方法:
•old方法就是使用initial ram disk,也叫initrd
•new方法就是使用iniramfs
这两个东西非常常见,咱们要好好研究下。
4.1 initrd
这个功能需要配置kernel的编译选项。
ARM支持将前面的initrd和vmlinux打包到一个image中。实际上只有ARM架构支持。(内核编译的时候要选择这一项)。讲了这么多,那么到底怎么用呢?
•initrd也是一个image。由bootloader启动的时候,或者bootloader下载到某个地方
•bootloader把initrd的地址告诉内核。内核启动时候把这个image解压并挂载
•另外一种办法,编译的时候将initrd和kernel放到一个image中,这种方法只有ARM架构支持。使用这种办法话,建议用initramfs。注意,android中使用的就是一个kernel+initramfs的单一image。也就是第二种办法
(这里有很多细节问题,以后我们分析源码再来搞懂它)
BL启动内核的时候,需要给LK传递参数,即告诉LK这个initrd在什么位置...很简单不是?
KL如何使用这个initrd呢?
•KL先根据参数指定的initrd地址,将这个image拷贝到内存中,然后解压,并挂载为/
•找到这个disk中的linuxrc文件,然后执行里边的语句《====这给了我们定制化自己ES的好计划
•处理完linuxrc后,KL unmount这个initrd,并加载真正的root device(看到没,这个initrd就是做些初始化的工作,但是你也可以不umount这个initrd。)这里的处理稍有差异。如果BL在参数中指明root=/dev/ram0,(代码中可见到这些语句),那么KL就不会执行linuxrc,并且也不会umount initrd。也就是这个initrd就是最终的根文件系统了。
那么如何制作这个Initrd呢?
其实就是一个gzip打包的文件夹....
(这部分代码在do_mounts.c中的prepare_namespace函数中)
4.2 initramfs
(详细说明:参考kernel/documentations/filesystems/ramfs-rootfs-initramfs.txt)
kernel默认支持这个initramfs,所以编译的时候,会整一个default的initramfs放到内核中。initramfs是一个cpio的打包文件。我特意查了下cpio的info。一般用法就是:读取一个目录下所有文件的信息及其所有文件的内容(可能是直接read数据到一个buffer中),然后把这些信息写到一个文件中。说白了,可能就是一个序列化的工具。然后LK用同样的方法就可以反序列化,恢复原来目录中的内容了。
前面说,LK编译的时候默认会有一个简单的initramfs目录结构。这个结构由kernel/scripts/gen_initramfs_list.sh脚本生成。这个脚本很简单:
--------------------------------------------------------------------------------
dir /dev 0755 0 0
nod /dev/console/ 0600 0 0 c 5 1
dir /root 0700 0 0
--------------------------------------------------------------------------------
执行的时候,前面加上mk...就生成一个目录了,然后用cpio打包,生成iniramfs,最后由LK解包并挂载
(具体内容,参考ramfs-rootfs-initramfs.txt)
如何制作自己的initramfs呢?
•搞一个文件夹吧,可仿照PC机器上linux的文件结构。也可以把busybox放上去。
•find testramfs -depth -print | cpio -ov > testramfs.cpio cpio的输入是文件名,输出通过>定向到testramfs.cpio。大家可以试试。
•解压的话,cpio -ivd < testramfs.cpio。这样就能还原testramfs文件夹中的内容了。
cpio:-o表示output,-v表示打印一些verbose信息,-i表示input,-d表示建立整个文件夹结构。没有-d的话,会出问题。
不过有了kernel编译的支持,我们不用自己调用cpio了,在编译选项中有一个INITRAMFS_SOURCE,把它指向目标文件夹,编译的时候自然会生成这个initramfs了。
参考文献:
这些参考文献中,最重要的是最后一个,ols2k-9.ps,下载并处理后得到一个pdf,实际上一篇论文。主要介绍了
Linux启动的一些问题。
再三解释一下,为什么需要init ram disk。FS一般安装在存储介质上,而读取这些存储介质需要驱动。内核启动的时候如果把这些驱动都加载的话,会非常麻烦,即使你把驱动静态编译到内核中,也不是一个完美的解决办法。所以。先整一个简单的,基于内存的FS,这样初始化工作都可以顺利进行。最后,等驱动都加载完后,再把实际存储上的FS挂载上来。这里要明白一点,没有一个FS的话,LK是没法正常工作的。
五 U-Boot
全名为Das U-Boot,是一个使用非常广泛的Bootloader。以后会专门撰文介绍UB。这里简单说两个点:
•UB的代码结构,先从CPU的start.S开始,这里会根据不同的CPU进行初始化,大部分代码都不需要我们修改
•再是Board的启动,这个和具体的板子有关。现在改名叫lowlevel_init.S了。
(最难的部分在于各个设备的初始化了,需要结合开发板的datasheet来做)
这里列出以下参考书:
其中,关于SDRAM.pdf,网址已经移到了:http://www.maxwell.com/products/microelectronics/docs/INTRO_TO_SDRAM.PDF
各位看官可以下载看看。
分类: Linux Kernel系列 2011-08-21 22:39 1424人阅读 评论(0) 收藏 举报
上篇我们知道,kernel初始化后将启动init进程,那么这个进程将干些什么呢?除此之外,kernel还需要做些什么事情呢?(想想文件系统、根存储设备是在什么时候初始化的呢?)
先从文件系统初始化说起。以前一直不明白,有了kernel为何还需要一个文件系统?经过反复琢磨,明白一个道理,kernel加载到内存后,kernel运行起来是没有问题的,但是如果没有Root FS,就好像PC上没有硬盘.....。另外,Linux中很多虚拟文件系统(proc,sys,dev等)都是挂靠在RootFS中的,所以RootFS在Linux中更加关键(必要条件简直就是)。(kernel中的FS是另外一个庞大的部分)
一 根文件系统
1 FHS:File system Hierachy Standard:Linux上文件系统布局的标准,例如 usr目录大概是干吗的,tmp目录大概是干嘛的。有空可以瞧瞧....其实使用LINUX OS多了,自然就理解了。
2 常用的文件夹布局:其实就是ES上普遍的文件目录:
•bin;dev;etc;home;lib;sbin;tmp;usr;var;
二 Post Boot
这里讲的是execve init之前的事情,因为源码中:
•run_init_process("/usr/bin/init"):这个时候已经有FS的布局了,也就是init程序本身必须放在一个FS中。
三 init
init进程很重要,不过android上的init进程的工作流程比较简单。这里介绍非Android上的init。一般它读取的配置文件是/etc/inittab中(ubuntu上似乎没有这个文件了,以后得找个FCore的系统看看)。
另外,这里还有一个叫run level的概念。见图1.
图1 run level
Run level说白了就是将系统运行状态分成几个级别,例如shutdown的时候init需要执行一些操作,reboot的时候需要执行一些操作。
这里关于Init的东西就不介绍了,很多关于linux系统配置的知识都有涉及。(确实比android的init要复杂多了)
四 Initial RAM Disk
LK在早期初始化的过程中,需要mount一个FS,目前有新旧两种方法:
•old方法就是使用initial ram disk,也叫initrd
•new方法就是使用iniramfs
这两个东西非常常见,咱们要好好研究下。
4.1 initrd
这个功能需要配置kernel的编译选项。
ARM支持将前面的initrd和vmlinux打包到一个image中。实际上只有ARM架构支持。(内核编译的时候要选择这一项)。讲了这么多,那么到底怎么用呢?
•initrd也是一个image。由bootloader启动的时候,或者bootloader下载到某个地方
•bootloader把initrd的地址告诉内核。内核启动时候把这个image解压并挂载
•另外一种办法,编译的时候将initrd和kernel放到一个image中,这种方法只有ARM架构支持。使用这种办法话,建议用initramfs。注意,android中使用的就是一个kernel+initramfs的单一image。也就是第二种办法
(这里有很多细节问题,以后我们分析源码再来搞懂它)
BL启动内核的时候,需要给LK传递参数,即告诉LK这个initrd在什么位置...很简单不是?
KL如何使用这个initrd呢?
•KL先根据参数指定的initrd地址,将这个image拷贝到内存中,然后解压,并挂载为/
•找到这个disk中的linuxrc文件,然后执行里边的语句《====这给了我们定制化自己ES的好计划
•处理完linuxrc后,KL unmount这个initrd,并加载真正的root device(看到没,这个initrd就是做些初始化的工作,但是你也可以不umount这个initrd。)这里的处理稍有差异。如果BL在参数中指明root=/dev/ram0,(代码中可见到这些语句),那么KL就不会执行linuxrc,并且也不会umount initrd。也就是这个initrd就是最终的根文件系统了。
那么如何制作这个Initrd呢?
其实就是一个gzip打包的文件夹....
(这部分代码在do_mounts.c中的prepare_namespace函数中)
4.2 initramfs
(详细说明:参考kernel/documentations/filesystems/ramfs-rootfs-initramfs.txt)
kernel默认支持这个initramfs,所以编译的时候,会整一个default的initramfs放到内核中。initramfs是一个cpio的打包文件。我特意查了下cpio的info。一般用法就是:读取一个目录下所有文件的信息及其所有文件的内容(可能是直接read数据到一个buffer中),然后把这些信息写到一个文件中。说白了,可能就是一个序列化的工具。然后LK用同样的方法就可以反序列化,恢复原来目录中的内容了。
前面说,LK编译的时候默认会有一个简单的initramfs目录结构。这个结构由kernel/scripts/gen_initramfs_list.sh脚本生成。这个脚本很简单:
--------------------------------------------------------------------------------
dir /dev 0755 0 0
nod /dev/console/ 0600 0 0 c 5 1
dir /root 0700 0 0
--------------------------------------------------------------------------------
执行的时候,前面加上mk...就生成一个目录了,然后用cpio打包,生成iniramfs,最后由LK解包并挂载
(具体内容,参考ramfs-rootfs-initramfs.txt)
如何制作自己的initramfs呢?
•搞一个文件夹吧,可仿照PC机器上linux的文件结构。也可以把busybox放上去。
•find testramfs -depth -print | cpio -ov > testramfs.cpio cpio的输入是文件名,输出通过>定向到testramfs.cpio。大家可以试试。
•解压的话,cpio -ivd < testramfs.cpio。这样就能还原testramfs文件夹中的内容了。
cpio:-o表示output,-v表示打印一些verbose信息,-i表示input,-d表示建立整个文件夹结构。没有-d的话,会出问题。
不过有了kernel编译的支持,我们不用自己调用cpio了,在编译选项中有一个INITRAMFS_SOURCE,把它指向目标文件夹,编译的时候自然会生成这个initramfs了。
参考文献:
这些参考文献中,最重要的是最后一个,ols2k-9.ps,下载并处理后得到一个pdf,实际上一篇论文。主要介绍了
Linux启动的一些问题。
再三解释一下,为什么需要init ram disk。FS一般安装在存储介质上,而读取这些存储介质需要驱动。内核启动的时候如果把这些驱动都加载的话,会非常麻烦,即使你把驱动静态编译到内核中,也不是一个完美的解决办法。所以。先整一个简单的,基于内存的FS,这样初始化工作都可以顺利进行。最后,等驱动都加载完后,再把实际存储上的FS挂载上来。这里要明白一点,没有一个FS的话,LK是没法正常工作的。
五 U-Boot
全名为Das U-Boot,是一个使用非常广泛的Bootloader。以后会专门撰文介绍UB。这里简单说两个点:
•UB的代码结构,先从CPU的start.S开始,这里会根据不同的CPU进行初始化,大部分代码都不需要我们修改
•再是Board的启动,这个和具体的板子有关。现在改名叫lowlevel_init.S了。
(最难的部分在于各个设备的初始化了,需要结合开发板的datasheet来做)
这里列出以下参考书:
其中,关于SDRAM.pdf,网址已经移到了:http://www.maxwell.com/products/microelectronics/docs/INTRO_TO_SDRAM.PDF
各位看官可以下载看看。
Linux Kernel系列三:Kernel编译和链接中的linker script语法详解
分类: Linux Kernel系列 2011-08-29 21:21 2855人阅读 评论(3)收藏 举报
先要讲讲这个问题是怎么来的。(咱们在分析一个技术的时候,先要考虑它是想解决什么问题,或者学习新知识的时候,要清楚这个知识的目的是什么)。
- 我在编译内核的时候,发现arch/arm/kernel目录下有一个这样的文件:vmlinux.lds.S。第一眼看上去,想想是不是汇编文件呢?打开一看,好像不是。那它是干嘛的?而且前面已经说过,make V=1的时候,发现这个文件的用处在ld命令中,即ld -T vmlinux.lds.S,好像是链接命令用的,如下所示
如arm-linux-ld -EL -p --no-undefined -X --build-id -o vmlinux -T arch/arm/kernel/vmlinux.lds。man ld,得到-T的意思是:为ld指定一个Linker script,意思是ld根据这个文件的内容来生成最终的二进制。
- 也许上面这个问题,你从没关注过,但是在研究内核代码的时候,常常有地方说“ __init宏会在最后的模块中生成一个特定的section,然后kernel加载的时候,寻找这个section中的函数”,说白了,上面这句话就是说最后生成的模块中,有一个特定的section,这又是什么东西?
好吧,希望上面的问题勾起你的好奇心。下面我们来扫盲,最后会给一个链接地址,各看官可以去那深造。
一 section是什么?
好吧,我们需要解释一下平时编译链接生成的二进制可执行程序(比如说ELF,EXE也行),so或者dll,内核(非压缩的,参加本系列第一节内容、vmlinux),或者ko是怎么组织的。
其实,大家或多或少都知道这些二进制中包括有什么text/bss/data节(也叫section)。text节存储的是代码、data存储的是已经初始化的静态变量、bss节存储的是未初始化的什么东西...
上面的东西我就不细究了。反正一点,一个二进制,最终会包含很多section。那么,为什么section叫text/bss/data,能叫别的名字吗?
OK,可以。但是你得告诉ld,那么这些内容就通过-T选项指定一个linker script就行了。这些内容我们放到后面的实例中来介绍。
(再三强调,咱们在理论上只是抛砖引玉,希望有兴趣的看官自己研究,注意和我们分享你的成果就行了。)
二 link script基础知识介绍
linker script中的语法是linker command language(很简单的language,大家不用害怕...)。那么LS的目的是什么呢?
- LS描述输入文件(也就是gcc -c命令产生的.o文件即object文件)中的section最终如何对应到一个输出文件。这个其实好理解,例如一个elf由三个.o文件构成,每个.o文件都有text/data/bss段,但最终的那一个elf就会将三个输入的.o文件的段合并到一起。
好了,下面我们介绍一些基本知识:
- ld的功能是将input文件组装成一个output文件。这些文件内部的都有特殊的组织结构,这种结构被叫做object file format。每一个文件叫做object file(这可能就是.o文件的来历吧。哈哈),输出文件也叫可执行文件(an executable),但是对于ld来说,它也是一种object文件。那么Object文件有什么特殊的地方呢?恩,它内部组织是按照section(段、或者节,以后不再区分二者)来组织的。一句话,object文件内部包含段......
- 每个段都有名字和size。另外,段内部还包含一些数据,这些数据叫做section contents,以后称段内容。每个段有不同的属性。例如text段标志为可加载(loadable),表示该段内的contents在运行时候(当然指输出文件执行的时候)需要加载到内存中。另外一些段中没有contents,那么这些段标示为allocatable,即需要分配一些内存(有时候这些内存会被初始化成0,这里说的应该是BSS段。BSS段在二进制文件中没有占据空间,即磁盘上二进制文件的大小比较小,但是加载到内存后,需要为BSS段分配内存空间。),还有一些段属于debug的,这里包含一些debug信息。
- 既然需要加载到内存中,那么加载到内存的地址是什么呢?loadable和allocable的段都有两个地址,VMA:虚拟地址,即程序运行时候的地址,例如把text段的VMA首地址设置为0x800000000,那么运行时候的首地址就是这个了。另外还有一个LMA,即Load memory address。这个地址是section加载时的地址。晕了吧?二者有啥区别?一般情况下,VMA=LMA。但也有例外。例如设置某数据段的LMA在ROM中(即加载的时候拷贝到ROM中),运行的时候拷贝到RAM中,这样LMA和VMA就不同了。---------》很难搞懂不是?这种方法用于初始化一些全局变量,基于那种ROM based system。(问一个问题,run的时候,怎么根据section中的VMA进行相应设置啊??以后可能需要研究下内核中关于execve实现方面的内容了)。关于VMA和LMA,大家通过objdump -h选项可以查看。
三 简单例子
下面来一个简单例子,
SECTIONS
{. = 0x10000;
.text : { *(.text) }
. = 0x8000000;
.data : { *(.data) }
.bss : { *(.bss) }
}
- SECTIONS是LS语法中的关键command,它用来描述输出文件的内存布局。例如上例中就含text/data/bss三个部分(实际上text/data/bss才是段,但是SECTIONS这个词在LS中是一个command,希望各位看官要明白)。
- .=0x10000; 其中的.非常关键,它代表location counter(LC)。意思是.text段的开始设置在0x10000处。这个LC应该指的是LMA,但大多数情况下VMA=LMA。
- .text:{*(.text)},这个表示输出文件的.text段内容由所有输入文件(*)的.text段组成。组成顺序就是ld命令中输入文件的顺序,例如1.obj,2.obj......
- 此后,由来了一个.=0x800000000;。如果没有这个赋值的,那么LC应该等于0x10000+sizeof(text段),即LC如果不强制指定的话,它默认就是上一次的LC+中间section的长度。还好,这里强制指定LC=0X800000000.表明后面的.data段的开始位于这个地址。
- .data和后面的.bss表示分别有输入文件的.data和.bss段构成。
你看,我们从这个LC文件中学到了什么?
恩,我们可以任意设置各个段的LMA值。当然,绝大部分情况,我们不需要有自己的LS来控制输出文件的内存布局。不过LK(linux kernel)可不一样了......
四 霸王硬上弓---vmlinux.lds.S分析
OK,有了上面的基础知识,下面我们霸王硬上弓,直接分析arch/arm/kernel/vmlinux.lds.S.虽然最终链接用的是vmlinux.lds,但是那个文件
由vmlinux.lds.S(这是一个汇编文件)得到,
arm-linux-gcc -E -Wp,-MD,arch/arm/kernel/.vmlinux.lds.d -nostdinc ...... -D__KERNEL__ -mlittle-endian ......
-DTEXT_OFFSET=0x00008000 -P -C -Uarm -D__ASSEMBLY__ -oarch/arm/kernel/vmlinux.lds arch/arm/kernel/vmlinux.lds.S
所以,我们直接分析vmlinux.lds好了。
/*
一堆注释,这里就不再贴上了,另外,增加//号做为注释标识
* Convert a physical address to a Page Frame Number and back
*/
一堆注释,这里就不再贴上了,另外,增加//号做为注释标识
* Convert a physical address to a Page Frame Number and back
*/
//OUTPUT_ARCH是LS语法中的COMMAND,用来指定输出文件的machine arch。objdump -f可查询所有支持的machine。另外
//这些东西涉及到一种叫BFD的。各位看官可以自己搜索下BFD的内容。
//下面这 表示输出文件基于ARM架构
OUTPUT_ARCH(arm)
OUTPUT_ARCH(arm)
//ENTRY也是一个command,用来设置入口点。这里表示入口点是stext 。根据LD的描述,入口点的意思就是程序运行的第一条指令。内核是一个模块,大家把他想象
//成一个运行在硬件上的大程序就可以了。而我们的程序又是运行在内核至上的。比较下Java虚拟机以及运行在其上的Java程序吧......
ENTRY(stext)
ENTRY(stext)
//设置jiffies为jiffies_64
jiffies = jiffies_64;
jiffies = jiffies_64;
//定义输出文件的段
SECTIONS
{
SECTIONS
{
//设置location count为0xc0008000,这个好理解吧?内核运行的地址全在C0000000以上
. = 0xC0000000 + 0x00008000;
. = 0xC0000000 + 0x00008000;
//定义一个.text.head段,由输入文件中所有.text.head段组成
/*
LS语法中,关于seciton的定义如下:
section [address] [(type)] :
[AT(lma)] [ALIGN(section_align)]
[SUBALIGN(subsection_align)]
[constraint]
{
output-section-command
output-section-command
...
} [>region] [AT>lma_region] [:phdr :phdr ...] [=fillexp]
[AT(lma)] [ALIGN(section_align)]
[SUBALIGN(subsection_align)]
[constraint]
{
output-section-command
output-section-command
...
} [>region] [AT>lma_region] [:phdr :phdr ...] [=fillexp]
其中,address为VMA,而AT命令中的为LMA。一般情况,address不会设置,所以它默认等于当前的location counter
*/
.text.head : {
.text.head : {
/*这个非常关键,咱们在内核代码中经常能看到一些变量声明,例如extern int __stext,但是却找不到在哪定义的
其实这些都是在lds文件中定义的。这里得说一下编译链接相关的小知识。咱们这知道大概即可,具体内容可以自己深入研究
假设C代码中定义一个变量 int x = 0;那么
1 编译器首先会分配一块内存,用来存储该变量的值
2 编译器在程序的symbol表中,创建一项,用来存储这个变量的地址
例如,上面的 int x = 0,就在symbol表中创建一x项,这个x项指向一块内存,sizeof(int)大小,存储的值为0。当有地方使用这个x的时候,编译器会生成相应的代码,
首先指向这个x的内存,然后读取内存中的值。
上面的内容是C中一个变量的定义。但是Linker script中也可以定义变量,这时候只会生成一个symbol项,但是没有分配内存。。例如_stext=0x100,那么会
创建一个symbol项,指向0x100的内存,但该内存中没有存储value。所以,我们在C中使用LS中定义的变量的话,只能取它的地址。下面是一个例子:
start_of_ROM = .ROM;end_of_ROM = .ROM + sizeof (.ROM) - 1;start_of_FLASH = .FLASH;上面三个变量是在LS中定义的,分别指向.ROM段的开始和结尾,以及FLASH段的开始。现在在C代码中想把ROM段的内容拷贝到FLASH段中,下面是C代码:extern char start_of_ROM, end_of_ROM, start_of_FLASH;memcpy (& start_of_FLASH, & start_of_ROM, & end_of_ROM - & start_of_ROM);注意其中的取地址符号&。C代码中只能通过这种方式来使用LS中定义的变量. start_of_ROM这个值本身是没有意义的,只有它的地址才有意义。因为它的值没有初始化。
地址就指向.ROM段的开头。
说白了,LS中定义的变量其实就是地址,即_stext=0x100就是C代码中的一个地址 int *_stext=0x100。明白了?
最终的ld中会分配一个slot,然后存储x的地址。也就是说,ld知道这些勾当。那么当然我们在LS中
也可以定义一个变量,然后在C中使用了。所以下面这句话实际上定义了一个_stext变量。在C中通过extern就可以引用了。但是这里有一个
比较关键的问题。C中定义的x=0,其值被初始化为0了。也就是slot...待补充
*/
_stext = .;.
_sinittext = .;
*(.text.head)
}
_stext = .;.
_sinittext = .;
*(.text.head)
}
//定义.init段,由所有的.init.text/.cpuinit.text/.meminit.text组成
//这时的LC的值为.init的开始
.init : { /* Init code and data */
*(.init.text) *(.cpuinit.text) *(.meminit.text)
.init : { /* Init code and data */
*(.init.text) *(.cpuinit.text) *(.meminit.text)
//定义一个变量 _einitext,它的值为当前的LC,即.init的初值+*(.init.text) *(.cpuinit.text) *(.meminit.text)的大小。也就是说变量
//_einitext标示一个结尾。
_einittext = .;
_einittext = .;
//下面这个变量__proc_info_begin标示一个开头
__proc_info_begin = .;
*(.proc.info.init) //所有.proc.info.init段内容在这
__proc_info_end = .;//下面这个变量__proc_info_end标示结尾,它和__proc_info_begin变量牢牢得把输出文件.proc.info.init的内容卡住了。
__proc_info_begin = .;
*(.proc.info.init) //所有.proc.info.init段内容在这
__proc_info_end = .;//下面这个变量__proc_info_end标示结尾,它和__proc_info_begin变量牢牢得把输出文件.proc.info.init的内容卡住了。
//有了上面begin和end的介绍,后面就简单了,大部分都是一个begin+end来卡住一段内容。根据前面的介绍,begin和end又可以在C程序中引用
//也就是我们通过Begin+end,就可以获得卡住的内容了。例如我们把一些初始化的函数指针放到一个begin和end中。然后通过一个循环,不就是
//可以调用这些函数了么。最后我们就来个例子介绍下。
__arch_info_begin = .;
*(.arch.info.init)
__arch_info_end = .;
__tagtable_begin = .;
*(.taglist.init)
__tagtable_end = .;
. = ALIGN(16);
__setup_start = .;
*(.init.setup)
__setup_end = .;
__early_begin = .;
*(.early_param.init)
__early_end = .;
__initcall_start = .;
*(.initcallearly.init)
__arch_info_begin = .;
*(.arch.info.init)
__arch_info_end = .;
__tagtable_begin = .;
*(.taglist.init)
__tagtable_end = .;
. = ALIGN(16);
__setup_start = .;
*(.init.setup)
__setup_end = .;
__early_begin = .;
*(.early_param.init)
__early_end = .;
__initcall_start = .;
*(.initcallearly.init)
__early_initcall_end = .;
*(.initcall0.init) *(.initcall0s.init) *(.initcall1.init) *(.initcall1s.init) *(.initcall2.init) *(.initcall2s.init) *(.initcall3.init) *(.initcall3s.init) *(.initcall4.init) *(.initcall4s.init) *(.initcall5.init) *(.initcall5s.init) *(.initcallrootfs.init) *(.initcall6.init) *(.initcall6s.init) *(.initcall7.init) *(.initcall7s.init)
__initcall_end = .;
__con_initcall_start = .;
*(.con_initcall.init)
__con_initcall_end = .;
__security_initcall_start = .;
*(.security_initcall.init)
__security_initcall_end = .;
. = ALIGN(32);//ALIGN,表示对齐,即这里的Location Counter的位置必须按32对齐
__initramfs_start = .; //ramfs的位置
usr/built-in.o(.init.ramfs)
__initramfs_end = .;
. = ALIGN(4096); //4K对齐
__per_cpu_load = .;
__per_cpu_start = .;
*(.data.percpu.page_aligned)
*(.data.percpu)
*(.data.percpu.shared_aligned)
__per_cpu_end = .;
__init_begin = _stext;
*(.init.data) *(.cpuinit.data) *(.cpuinit.rodata) *(.meminit.data) *(.meminit.rodata)
. = ALIGN(4096);
__init_end = .;
}
*(.initcall0.init) *(.initcall0s.init) *(.initcall1.init) *(.initcall1s.init) *(.initcall2.init) *(.initcall2s.init) *(.initcall3.init) *(.initcall3s.init) *(.initcall4.init) *(.initcall4s.init) *(.initcall5.init) *(.initcall5s.init) *(.initcallrootfs.init) *(.initcall6.init) *(.initcall6s.init) *(.initcall7.init) *(.initcall7s.init)
__initcall_end = .;
__con_initcall_start = .;
*(.con_initcall.init)
__con_initcall_end = .;
__security_initcall_start = .;
*(.security_initcall.init)
__security_initcall_end = .;
. = ALIGN(32);//ALIGN,表示对齐,即这里的Location Counter的位置必须按32对齐
__initramfs_start = .; //ramfs的位置
usr/built-in.o(.init.ramfs)
__initramfs_end = .;
. = ALIGN(4096); //4K对齐
__per_cpu_load = .;
__per_cpu_start = .;
*(.data.percpu.page_aligned)
*(.data.percpu)
*(.data.percpu.shared_aligned)
__per_cpu_end = .;
__init_begin = _stext;
*(.init.data) *(.cpuinit.data) *(.cpuinit.rodata) *(.meminit.data) *(.meminit.rodata)
. = ALIGN(4096);
__init_end = .;
}
//DISACARD是一个特殊的section,表示符合这个条件的输入段都不会写到输出段中,也就是输出文件中不包含下列段
/DISCARD/ : { /* Exit code and data */
*(.exit.text) *(.cpuexit.text) *(.memexit.text)
*(.exit.data) *(.cpuexit.data) *(.cpuexit.rodata) *(.memexit.data) *(.memexit.rodata)
*(.exitcall.exit)
*(.ARM.exidx.exit.text)
*(.ARM.extab.exit.text)
}
//省略部分内容
/DISCARD/ : { /* Exit code and data */
*(.exit.text) *(.cpuexit.text) *(.memexit.text)
*(.exit.data) *(.cpuexit.data) *(.cpuexit.rodata) *(.memexit.data) *(.memexit.rodata)
*(.exitcall.exit)
*(.ARM.exidx.exit.text)
*(.ARM.extab.exit.text)
}
//省略部分内容
//ADDR为内置函数,用来返回VMA的
/*
这里举个小例子,大家看看VMA和LMA到底有什么作用
SECTIONS
{
.text 0x1000 : { *(.text) _etext = . ; } /.text段的VMA为0x1000,而且LMA=VMA
.mdata 0x2000 : //.mdata段的VMA为0x2000,但是它的LMA却在.text段的结尾
AT ( ADDR (.text) + SIZEOF (.text) )
{ _data = . ; *(.data); _edata = . ; }
.bss 0x3000 :
{ _bstart = . ; *(.bss) *(COMMON) ; _bend = . ;}
}
{
.text 0x1000 : { *(.text) _etext = . ; } /.text段的VMA为0x1000,而且LMA=VMA
.mdata 0x2000 : //.mdata段的VMA为0x2000,但是它的LMA却在.text段的结尾
AT ( ADDR (.text) + SIZEOF (.text) )
{ _data = . ; *(.data); _edata = . ; }
.bss 0x3000 :
{ _bstart = . ; *(.bss) *(COMMON) ; _bend = . ;}
}
看到了么?.mdata段运行的时候在0x2000,但是数据load地址却在.text段后,所以运行的时候需要把.mdata段内容拷贝过去。
extern char _etext, _data, _edata, _bstart, _bend;
char *src = &_etext; //_etext为.text端的末尾 VMA地址,但同时也是.mdata段LMA的开始,有LS种的AT指定
char *dst = &_data; //_data为mdata段的VMA,现在需要把LMA地址开始的内容拷贝到VMA开始的地方
/* ROM has data at end of text; copy it. */
while (dst < &_edata)
*dst++ = *src++; //拷贝....明白了?不明白的好好琢磨
/* Zero bss. */
for (dst = &_bstart; dst< &_bend; dst++)
*dst = 0; //初始化数据区域
char *src = &_etext; //_etext为.text端的末尾 VMA地址,但同时也是.mdata段LMA的开始,有LS种的AT指定
char *dst = &_data; //_data为mdata段的VMA,现在需要把LMA地址开始的内容拷贝到VMA开始的地方
/* ROM has data at end of text; copy it. */
while (dst < &_edata)
*dst++ = *src++; //拷贝....明白了?不明白的好好琢磨
/* Zero bss. */
for (dst = &_bstart; dst< &_bend; dst++)
*dst = 0; //初始化数据区域
*/
.rodata : AT(ADDR(.rodata) - 0) {
__start_rodata = .;
*(.rodata) *(.rodata.*) *(__vermagic) *(__markers_strings) *(__tracepoints_strings)
}
.rodata1 : AT(ADDR(.rodata1) - 0) {
*(.rodata1)
}
......//省略部分内容
.rodata : AT(ADDR(.rodata) - 0) {
__start_rodata = .;
*(.rodata) *(.rodata.*) *(__vermagic) *(__markers_strings) *(__tracepoints_strings)
}
.rodata1 : AT(ADDR(.rodata1) - 0) {
*(.rodata1)
}
......//省略部分内容
_edata_loc = __data_loc + SIZEOF(.data);
.bss : {
__bss_start = .; /* BSS */
*(.bss)
*(COMMON)
_end = .;
}
/* Stabs debugging sections. */
.stab 0 : { *(.stab) }
.stabstr 0 : { *(.stabstr) }
.stab.excl 0 : { *(.stab.excl) }
.stab.exclstr 0 : { *(.stab.exclstr) }
.stab.index 0 : { *(.stab.index) }
.stab.indexstr 0 : { *(.stab.indexstr) }
.comment 0 : { *(.comment) }
}
//ASSERT是命令,如果第一个参数为0,则打印第二个参数的信息(也就是错误信息),然后ld命令退出。
ASSERT((__proc_info_end - __proc_info_begin), "missing CPU support")
ASSERT((__arch_info_end - __arch_info_begin), "no machine record defined")
.bss : {
__bss_start = .; /* BSS */
*(.bss)
*(COMMON)
_end = .;
}
/* Stabs debugging sections. */
.stab 0 : { *(.stab) }
.stabstr 0 : { *(.stabstr) }
.stab.excl 0 : { *(.stab.excl) }
.stab.exclstr 0 : { *(.stab.exclstr) }
.stab.index 0 : { *(.stab.index) }
.stab.indexstr 0 : { *(.stab.indexstr) }
.comment 0 : { *(.comment) }
}
//ASSERT是命令,如果第一个参数为0,则打印第二个参数的信息(也就是错误信息),然后ld命令退出。
ASSERT((__proc_info_end - __proc_info_begin), "missing CPU support")
ASSERT((__arch_info_end - __arch_info_begin), "no machine record defined")
五 内核代码中使用LS中定义的变量
咱们看一个小例子
[-->init/main.c]
extern initcall_t __initcall_start[], __initcall_end[], __early_initcall_end[];//这几个值在LS中定义。大家可以在上面搜索下
static void __init do_initcalls(void)
{
initcall_t *call;
//上面已经定义成数组了,所以下面这些变量直接取的就是指针,和上面例子中使用&一个意思,反正不能用value
for (call = __early_initcall_end; call < __initcall_end; call++)
do_one_initcall(*call);
/* Make sure there is no pending stuff from the initcall sequence */
flush_scheduled_work();
}
{
initcall_t *call;
//上面已经定义成数组了,所以下面这些变量直接取的就是指针,和上面例子中使用&一个意思,反正不能用value
for (call = __early_initcall_end; call < __initcall_end; call++)
do_one_initcall(*call);
/* Make sure there is no pending stuff from the initcall sequence */
flush_scheduled_work();
}
六 总结
关于LS的详细文档,见下面的网址:
http://sourceware.org/binutils/docs/ld/index.html
上面文档写得比较粗,但大家知道两点即可:
- LK源码中那些找不到来源的变量是怎么来的---》在LS定义。
- VMA和LMA是怎么回事。
linux kernel系列四:嵌入式系统中的文件系统以及MTD
分类: Linux Kernel系列 2011-09-22 10:00 3461人阅读 评论(2)收藏 举报
本节介绍File System和MTD技术
一 FS
熟知的FS有ext2,3,4.但是这些都是针对磁盘设备的。而ES中一般的存储设备为Flash,由于Flash的特殊性:
- Flash存储按照Block size进行划分,而一个BLS一般有几十K。(对比磁盘的一个簇才512个字节)。这么大的BLS有什么坏处呢?很明显,擦除一个BL就需要花费很长的时间了。
- 另外,FLASH操作,一次必须针对一个BL,也就是如果我想修改一个字节的话,也必须先擦掉128K。这不是想死吗?
- FLASH每个BL擦写次数是有限的,例如2百万次?如果每次都操作同一个BL的话,很快这个BL就会死掉。
所以,针对FLASH的特性,整出了一个Journaling Flash File System(JFFS2,第二版)。它的特点就是:
- 损耗均衡,也就是每次擦写都不会停留在一个BL上。例如BL1上写一个文件,那么再来一个新文件的时候,FS就不会选择BL1了,而是选择BL2。这个技术叫weal leveling:损耗均衡
(apt-get install mtd-tools,下载不少好工具,另外,可见往flash设备写log,可能会导致flash短命喔)
一些伪文件系统:proc/sysfs,systool工具用来分析sysfs。
ES中常用的FS还有ramfs/rootfs/tmpfs,都是基于内存的FS。这个和前面讲的initramfs有什么关系?实际上这些是基于Initramfs的。
这里要解释一下几个比如容易混淆的东西:
- ram disk:这个是一个基于ram的disk,用来模拟block设备的,所以它是建立在一个虚拟的BLOCK设备上的,至于上面的FS用什么,无所谓.这样就引起效率等的问题。毕竟你的read等操作还是要传递到驱动的,并且如果该设备上构造了一个EXT2 FS的话,还得有相应的ext2-FS模块。麻烦..
- ramfs:这是一个基于内存的FS,而不是一个基于真实设备的FS。ramfs的特点就是用户可以死劲写内存,直到把系统内存搞空。
- 为了控制一下上面这个缺点,引出了tmpfs,可以指定tmpfs的size。(这个又好像和真实设备有点类似,因为真实设备的存储空间也是有限的)
- rootfs是一种特殊的ramfs或者tmpfs(看LK中是否启用了tmpfs),另外,rootfs是不能被umount的
下面介绍一下如何利用mount loop创建一个虚拟的基于文件的BLOCK设备。
- 先创建一个全是0的文件,利用dd命令:dd if=/dev/zero of=../fstest bs=1024 count=512 这个解释如下:从if中拷贝数据到of,每次拷贝字节为1024,拷贝总次数为512. 各位可用十六制工具看看,生成的文件里边全是0X00
- 在这个文件中创建FS,mkfs.ext2fs ../fstest。现在,FS就存在于这个文件了。其实FS也就是一些组织结构,例如superblock,inode等信息
- 如何把这个带有FS信息的文件挂载呢?其实也就是如何把这个文件当做一个Block device呢?利用mount的loop选项,mount -t ext2 -o loop fstest /tmp/。这样这个文件就被当做一个虚拟Block设备挂载到tmp了。
二 MTD技术
MTD全称是Memory Technology Device,内存技术设备?实际上是一个虚拟设备驱动层,类似Virtual File System。它提供标准API给那些操作Raw Flash的device driver。那么Flash device和普通的Block device的区别是什么呢?
- 普通的BLD只有两种操作:read和write
- 而Flash Device有三种操作:read,write和erase,另外,还需要一种wear leveling算法来做损耗均衡
这里要重点指出的是:
SD/MMC卡、CF(Compact Flash)卡、USB Flash等并不是MTD设备,因为这些设备中已经有一个内置的Flash Translation Layer,这个layer处理erase、wear leveling事情了(这个TL应该是固件中支持的)。所以这些设备直接当做普通的Block Device使用
(上面的描述还是没能说清楚MTD到底是怎么用的,以后会结合源码分析一下)
2.1 内核中启用MTD支持
这个很简单,make menuconfig的时候打开就行了,有好几个选项。

图1 LK中MTD支持的配置选项
其中:
- MTC_CHAR和MTD_BLOCK用来支持CHAR模式和BLOCK模式读写MTD设备。这个和普通的char以及block设备意思一样
- 最后两个是在内核中设置一个MTD test驱动。8192K用来设置总大小,第二个128用来设置block size。就是在内核中搞了一个虚拟的Flash设备,用作测试
ES中又如何配置MTD及其相关的东西呢?
- 为Flash Disk设置分区(也可以整个Device就一个分区。BTW,我一直没彻底搞清楚分区到底是想干什么,这个可能是历史原因啦....)
- 设置Flash的类型以及location。Flash设备分为NOR和NAND,本节最后会简单介绍下二者的区别。
- 为Flash芯片选择合适的driver
- 为LK配置driver
下面先看看分区的设置
可对Flash分区,这里有一些稍微重要的内容:如何把Flash分区的信息传递给LK呢?有两种方法:
- 将整个device的分区情况存在一个BLock中,这样BootLoader启动的时候,根据这个BLock中的内容建立相应信息等。好像只有Red Boot支持。所以叫RedBoot Partition Table。另外,LK可以识别这种分区,通过CFI(Command Flash Interface)读取这个分区的信息。
- Kernel Command Line Partitioning:通过Kernel启动的时候传入参数,不过KL必须配置一下。Command格式如下:
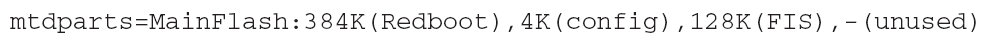
图2
再看看Driver的Mapping,也就是将MTD和对应的Flash Driver配对...
kernel/drivers/mtd/maps......,以后要分析
Flash芯片本身的Driver呢?
kernel/drivers/mtd/chips,目前比较流行的是CFI接口
三 一些参考资料和补充知识
http://www.linux-mtd.infradead.org/
MTD的本意是:
We're working on a generic Linux subsystem for memory devices, especially Flash devices.
The aim of the system is to make it simple to provide a driver for new hardware, by providing a generic interface between the hardware drivers and the upper layers of the system.
Hardware drivers need to know nothing about the storage formats used, such as FTL, FFS2, etc., but will only need to provide simple routines for read, write and erase. Presentation of the device's contents to the user in an appropriate form will be handled by the upper layers of the system.
The aim of the system is to make it simple to provide a driver for new hardware, by providing a generic interface between the hardware drivers and the upper layers of the system.
Hardware drivers need to know nothing about the storage formats used, such as FTL, FFS2, etc., but will only need to provide simple routines for read, write and erase. Presentation of the device's contents to the user in an appropriate form will be handled by the upper layers of the system.
MTD overview
MTD subsystem (stands for Memory Technology Devices) provides an abstraction layer for raw flash devices. It makes it possible to use the same API when working with different flash types and technologies, e.g. NAND, OneNAND, NOR, AG-AND, ECC'd NOR, etc.
MTD subsystem does not deal with block devices like MMC, eMMC, SD, CompactFlash, etc. These devices are not raw flashes but they have a Flash Translation layer inside, which makes them look like block devices. These devices are the subject of the Linux block subsystem, not MTD. Please, refer to this FAQ section for a short list of the main differences between block and MTD devices. And the raw flash vs. FTL devices UBIFS section discusses this in more details.
MTD subsystem has the following interfaces.
MTD subsystem (stands for Memory Technology Devices) provides an abstraction layer for raw flash devices. It makes it possible to use the same API when working with different flash types and technologies, e.g. NAND, OneNAND, NOR, AG-AND, ECC'd NOR, etc.
MTD subsystem does not deal with block devices like MMC, eMMC, SD, CompactFlash, etc. These devices are not raw flashes but they have a Flash Translation layer inside, which makes them look like block devices. These devices are the subject of the Linux block subsystem, not MTD. Please, refer to this FAQ section for a short list of the main differences between block and MTD devices. And the raw flash vs. FTL devices UBIFS section discusses this in more details.
MTD subsystem has the following interfaces.
- MTD character devices - usually referred to as /dev/mtd0, /dev/mtd1, and so on. These character devices provide I/O access to the raw flash. They support a number of ioctl calls for erasing eraseblocks, marking them as bad or checking if an eraseblock is bad, getting information about MTD devices, etc. /dev/mtdx竟然是char device!!
- The sysfs interface is relatively newer and it provides full information about each MTD device in the system. This interface is easily extensible and developers are encouraged to use the sysfs interface instead of older ioctl or /proc/mtd interfaces, when possible.
- The /proc/mtd proc file system file provides general MTD information. This is a legacy interface and the sysfs interface provides more information.
MTD subsystem supports bare NAND flashes with software and hardware ECC, OneNAND flashes, CFI (Common Flash Interface) NOR flashes, and other flash types.
Additionally, MTD supports legacy FTL/NFTL "translation layers", M-Systems' DiskOnChip 2000 and Millennium chips, and PCMCIA flashes (pcmciamtd driver). But the corresponding drivers are very old and not maintained very much.
MTD Block Driver:
The mtdblock driver available in the MTD is an archaic tool which emulates block devices on top of MTD devices. It does not even have bad eraseblock handling, so it is not really usable with NAND flashes. And it works by caching a whole flash erase block in RAM, modifying it as requested, then erasing the whole block and writing back the modified. This means that mtdblock does not try to do any optimizations, and that you will lose lots of data in case of power cuts. And last, but not least, mtdblock does not do any wear-leveling.
Often people consider mtdblock as general FTL layer and try to use block-based file systems on top of bare flashes using mtdblock. This is wrong in most cases. In other words, please, do not use mtdblock unless you know exactly what you are doing.
There is also a read-only version of this driver which doesn't have the capacity to do the caching and erase/writeback, mainly for use with uCLinux where the extra RAM requirement was considered too large
Often people consider mtdblock as general FTL layer and try to use block-based file systems on top of bare flashes using mtdblock. This is wrong in most cases. In other words, please, do not use mtdblock unless you know exactly what you are doing.
There is also a read-only version of this driver which doesn't have the capacity to do the caching and erase/writeback, mainly for use with uCLinux where the extra RAM requirement was considered too large
These are the modules which provide interfaces that can be used directly from userspace. The user modules currently planned include:
- Raw character access: A character device which allows direct access to the underlying memory. Useful for creating filesystems on the devices, before using some of the translation drivers below, or for raw storage on infrequently-changed flash, or RAM devices.
- Raw block access :A block device driver which allows you to pretend that the flash is a normal device with sensible sector size.It actually works by caching a whole flash erase block in RAM, modifying it as requested, then erasing the whole block and writing back the modified data.
This allows you to use normal filesystems on flash parts. Obviously it's not particularly robust when you are writing to it - you lose a whole erase block's worth of data if your read/modify/erase/rewrite cycle actually goes read/modify/erase/poweroff. But for development, and for setting up filesystems which are actually going to be mounted read-only in production units, it should be fine. There is also a read-only version of this driver which doesn't have the capacity to do the caching and erase/writeback, mainly for use with uCLinux where the extra RAM requirement was considered too large. - Flash Translation Layer (FTL):NFTL,Block device drivers which implement an FTL/NFTL filesystem on the underlying memory device. FTL is fully functional. NFTL is currently working for both reading and writing, but could probably do with some more field testing before being used on production systems.
- Journalling Flash File System, v2:This provides a filesystem directly on the flash, rather than emulating a block device. For more information, see sources.redhat.com.
- MTD hardware device drivers
These provide physical access to memory devices, and are not used directly - they are accessed through the user modules above.
On-board memory:Many PC chipsets are incapable of correctly caching system memory above 64M or 512M. A driver exists which allows you to use this memory with the linux-mtd system. - PCMCIA devices:PCMCIA flash (not CompactFlash but real flash) cards are now supported by the pcmciamtd driver in CVS.
- Common Flash Interface (CFI) onboard NOR flash:This is a common solution and is well-tested and supported, most often using JFFS2 or cramfs file systems.
- Onboard NAND flash:NAND flash is rapidly overtaking NOR flash due to its larger size and lower cost; JFFS2 support for NAND flash is approaching production quality.
- M-Systems' DiskOnChip 2000 and Millennium:The DiskOnChip 2000, Millennium and Millennium Plus devices should be fully supported, using their native NFTL and INFTL 'translation layers'. Support for JFFS2 on DiskOnChip 2000 and Millennium is also operational although lacking proper support for bad block handling.
这里牵扯到NOR和NAND,那么二者有啥区别呢?
Beside the different silicon cell design, the most important difference between NAND and NOR Flash is the bus interface. NOR Flash is connected to a address / data bus direct like other memory devices as SRAM etc. NAND Flash uses a multiplexed I/O Interface with some additional control pins. NAND flash is a sequential access device appropriate for mass storage applications, while NOR flash is a random access device appropriate for code storage application. NOR Flash can be used for code storage and code execution. Code stored on NAND Flash can't be executed from there. It must be loaded into RAM memory and executed from there.
- NOR可以直接和CPU相连,就好像内存一样。NAND不可以,因为NAND还需要别的一些I/O控制接口。所以NAND更像磁盘,而NOR更像内存
- NOR比NAND贵,并且,NAND支持顺序读取,而NOR支持随机读取。
- 所以,NOR中可存储代码,这样CPU直接读取就在其中运行。NAND不可以(主要还是因为CPU取地址的时候不能直接找到NAND)
全文来自:http://blog.csdn.net/innost/article/details/6799518
- Linux Kernel系列
- Linux Kernel系列
- Linux Kernel系列
- Linux kernel 系列 汇编
- 初探Linux kernel系列一
- 初探Linux kernel系列二
- Linux Kernel - 文件系统系列纲要
- Linux Kernel系列一:开篇和Kernel启动概要
- Linux Kernel系列一:开篇和Kernel启动概要
- Linux Kernel系列一:开篇和Kernel启动概要
- Linux Kernel系列一:开篇和Kernel启动概要
- Linux Kernel系列一:开篇和Kernel启动概要
- Linux基础系列-Kernel 初始化宏
- Linux Kernel系列 - VFS核心数据结构
- linux kernel系列四:嵌入式系统中的文件系统以及MTD
- linux kernel系列四:嵌入式系统中的文件系统以及MTD
- Linux Kernel系列 - 牛X的内核代码注释
- Linux Kernel 系列2:用户空间的初始化
- linux:如何修改用户的密码
- 能上QQ但不能上网问题精解
- Solr学习总结-命令行添加索引
- bitmap思想和2-Bitmap 实现
- CSplitterWnd中的各个CView是怎么和CDocument联系(attach)的?
- Linux Kernel系列
- 使用(Drawable)资源
- 数组最长递增子序列
- css hack for ie
- mysql查询昨天是哪一天
- (DEBUG相关)使用调试C运行时间库(DCRT)进行检查
- 问题:Activity里面添加多个ViewPager(Fragment),ViewPager里面继续添加Fragment,无法显示
- android AsyncTask介绍
- android 之开发资源


