一网打尽中文编码转换---6种编码30个方向的转换
来源:互联网 发布:网络手游金币修改 编辑:程序博客网 时间:2024/05/16 23:46
1.问题提出
在学编程序时,曾经有人问过“你可以编一个记事本程序吗?”当时很不屑一顾,但是随着学习MFC的深入,了解到记事本程序也并非易事,难点就是四种编码之间的转换。
对于编码,这是一个令初学者头疼的问题,特别是对于编码的转换,更是难以捉摸。笔者为了完成毕业设计中的一个编码转换模块,研究了中文编码和常见的字符集后,决定解决"记事本"程序的编码问题,更进一步完成GB2312、Big5、GBK、Unicode 、Unicode big endian、UTF-8共6种编码之间的任意转换。
2.问题解决
(1)编码基础知识
a.了解编码和字符集
这部分内容,我不在赘述,可参见CSDN Ancky的专栏中《各种字符集和编码详解》
博客地址:http://blog.csdn.net/ancky/article/details/2034809
b.单字节、双字节、多字节
这部分内容,可参见我先前翻译的博文《C++字符串完全指南--第一部分:win32 字符编码》
博客地址:http://blog.csdn.net/ziyuanxiazai123/article/details/7482360
c.区域和代码页
这部分内容,可参见博客 http://hi.baidu.com/tzpwater/blog/item/bd4abb0b60bff1db3ac7636a.html
d.中文编码GB2312、GBK、Big5,这部分内容请参见CSDN lengshine 博客中《GB2312、GBK、Big5汉字编码
》,博客地址:http://blog.csdn.net/lengshine/article/details/5470545
e.Windows程序的字符编码
这部分内容,可参见博客http://blog.sina.com.cn/s/blog_4e3197f20100a6z2.html 中《Windows程序的字符编码》
(2)编码总结
a.六种编码的特点
六种编码的特点如下图所示:

b.编码存储差别
ANSI(在简体中文中默认为GB2312)、Unicode、Unicode big endian 、UTF-8存储存在差别。
以中文"你好"二字为例,他们存贮格式如下图所示:
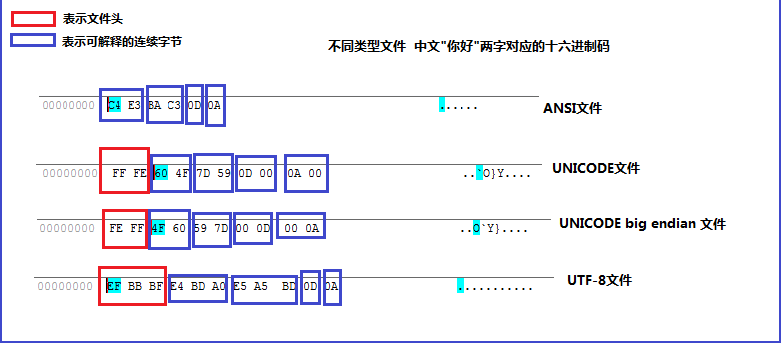
c.GB2312、Big5、GBK编码的区别
三者中汉字均采用二个字节表示,但是字节表示的值范围有所不同,如下图所示:

(3)编码转换方式
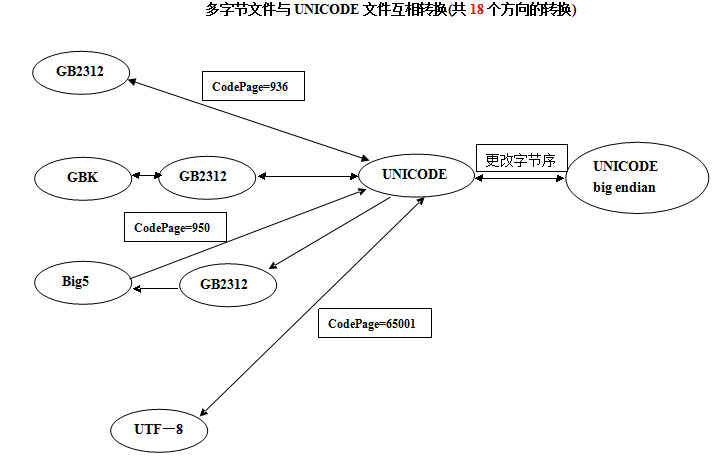
6种编码互相转换,由排列组合知识知道共有30个方向的转换.笔者采用的转换方法,
多字节文件与Unicode文件转换如下图所示:
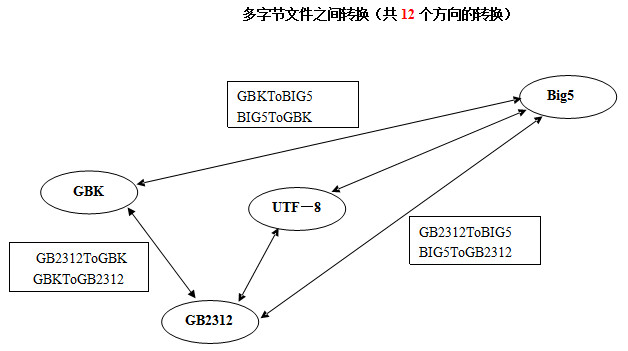
多字节文件之间转换如下图所示:
(4)编码转换使用的三个函数
a.MultiByteToWideChar
该函数完成多字节字符串向Unicode宽字符串的转换.
函数原型为:
int MultiByteToWideChar( UINT CodePage, // 代码页 DWORD dwFlags, // 转换标志 LPCSTR lpMultiByteStr, // 待转换的字符串 int cbMultiByte, // 待转换字符串的字节数目 LPWSTR lpWideCharStr, // 转换后宽字符串的存储空间 int cchWideChar // 转换后宽字符串的存储空间大小 以宽字符大小为单位);b.WideCharToMultiByte该函数完成Unicode宽字符串到多字节字符串的转换,使用方法具体参见MSDN。以上两个函数可以完成大部分的字符串转换,可以将其封装成多字节和宽字节之间的转换函数:UTF-8转换到Big5编码的效果如下图所示:wchar_t* Coder::MByteToWChar(UINT CodePage,LPCSTR lpcszSrcStr){LPWSTR lpcwsStrDes=NULL;int len=MultiByteToWideChar(CodePage,0,lpcszSrcStr,-1,NULL,0); lpcwsStrDes=new wchar_t[len+1];if(!lpcwsStrDes)return NULL;memset(lpcwsStrDes,0,sizeof(wchar_t)*(len+1)); len=MultiByteToWideChar(CodePage,0,lpcszSrcStr,-1,lpcwsStrDes,len);if(len)return lpcwsStrDes;else{ delete[] lpcwsStrDes;return NULL;}}char* Coder::WCharToMByte(UINT CodePage,LPCWSTR lpcwszSrcStr){char* lpszDesStr=NULL;int len=WideCharToMultiByte(CodePage,0,lpcwszSrcStr,-1,NULL,0,NULL,NULL);lpszDesStr=new char[len+1];memset(lpszDesStr,0,sizeof(char)*(len+1));if(!lpszDesStr)return NULL;len=WideCharToMultiByte(CodePage,0,lpcwszSrcStr,-1,lpszDesStr,len,NULL,NULL);if(len)return lpszDesStr;else{ delete[] lpszDesStr;return NULL;}}
c.LCMapString
依赖于本地机器的字符转换函数,尤其是中文编码在转换时要依赖于本地机器,
直接利用上述a、b中叙述的函数会产生错误,例如直接从GB2312转换到Big5,利用MultiByteToWideChar函数将GB2312转换到Unicode字符串,然后从Unicode字符串利用函数测试程序运行效果如下图所示:WideCharToMultiByte转换成Big5,将会发生错误,错误的结果如下图所示:因此中文编码转换时适当使用LCMapString函数,才能完成正确的转换.例如:
//简体中文 GB2312 转换成 繁体中文BIG5char* Coder::GB2312ToBIG5(const char* szGB2312Str){ LCID lcid = MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC); int nLength = LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,-1,NULL,0); char* pBuffer=new char[nLength+1];if(!pBuffer)return NULL; LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,-1,pBuffer,nLength); pBuffer[nLength]=0; wchar_t* pUnicodeBuff = MByteToWChar(CP_GB2312,pBuffer); char* pBIG5Buff = WCharToMByte(CP_BIG5,pUnicodeBuff); delete[] pBuffer; delete[] pUnicodeBuff; return pBIG5Buff;}(5)编码实现
实现Coder类完成编码转换工作.
Coder类的代码清单如下:// Coder.h: interface for the Coder class.////////////////////////////////////////////////////////////////////////#if !defined(AFX_ENCODING_H__2AC955FB_9F8F_4871_9B77_C6C65730507F__INCLUDED_)#define AFX_ENCODING_H__2AC955FB_9F8F_4871_9B77_C6C65730507F__INCLUDED_#if _MSC_VER > 1000#pragma once#endif // _MSC_VER > 1000//-----------------------------------------------------------------------------------------------//程序用途:实现GB2312、big5、GBK、Unicode、Unicode big endian、UTF-8六种编码的任意装换 //程序作者:湖北师范学院计算机科学与技术学院 王定桥 //核心算法:根据不同编码特点向其他编码转换//测试结果:在Windows7 VC6.0环境下测试通过 //制作时间:2012-04-24 //代码版权:代码公开供学习交流使用 欢迎指正错误 改善算法//-----------------------------------------------------------------------------------------------//Windows代码页typedef enum CodeType{ CP_GB2312=936, CP_BIG5=950,CP_GBK=0 //此处特殊处理 CP_GBK仅作一标志 GBK代码页值尚未查得 }CodePages;//txt文件编码typedef enum TextCodeType{ GB2312=0,BIG5=1,GBK=2,UTF8=3,UNICODE=4,UNICODEBIGENDIAN=5,DefaultCodeType=-1}TextCode;class Coder {public:Coder();virtual ~Coder();public://默认一次转换字节大小UINT PREDEFINEDSIZE;//指定转换时默认一次转换字节大小void SetDefaultConvertSize(UINT nCount);//编码类型转换为字符串CString CodeTypeToString(TextCode tc);//文件转到另一种文件BOOL FileToOtherFile(CString filesourcepath, CString filesavepath,TextCode tcTo,TextCode tcCur=DefaultCodeType);//Unicode 和Unicode big endian文件之间转换BOOL UnicodeEndianFileConvert(CString filesourcepath, CString filesavepath,TextCode tcTo);//多字节文件之间的转换BOOL MBFileToMBFile(CString filesourcepath, CString filesavepath,TextCode tcTo,TextCode tcCur=DefaultCodeType);//Unicode和Unicode big endian文件向多字节文件转换BOOL UnicodeFileToMBFile(CString filesourcepath, CString filesavepath,TextCode tcTo);//多字节文件向Unicode和Unicode big endian文件转换BOOL MBFileToUnicodeFile(CString filesourcepath,CString filesavepath,TextCode tcTo,TextCode tcCur=DefaultCodeType);//获取文件编码类型TextCode GetCodeType(CString filepath);//繁体中文BIG5 转换成 简体中文 GB2312char* BIG5ToGB2312(const char* szBIG5Str);//简体中文 GB2312 转换成 繁体中文BIG5 char* GB2312ToBIG5(const char* szGB2312Str);//简繁中文GBK编码转换成简体中文GB2312char* GBKToGB2312(const char *szGBkStr);//简体中文GB2312编码转换成简繁中文GBKchar* GB2312ToGBK(const char *szGB2312Str);//简繁中文GBK转换成繁体中文Big5char* GBKToBIG5(const char *szGBKStr);//繁体中文BIG5转换到简繁中文GBKchar* BIG5ToGBK(const char *szBIG5Str);//宽字符串向多字节字符串转换char* WCharToMByte(UINT CodePage,LPCWSTR lpcwszSrcStr);//多字节字符串向宽字符串转换wchar_t* MByteToWChar(UINT CodePage,LPCSTR lpcszSrcStr);protected://获取编码类型对应的代码页UINT GetCodePage(TextCode tccur);//多字节向多字节转换char* MByteToMByte(UINT CodePageCur,UINT CodePageTo,const char* szSrcStr);//Unicode和Unicode big endian字符串之间的转换void UnicodeEndianConvert(LPWSTR lpwszstr);//文件头常量字节数组const static byte UNICODEBOM[2];const static byte UNICODEBEBOM[2];const static byte UTF8BOM[3]; };#endif // !defined(AFX_ENCODING_H__2AC955FB_9F8F_4871_9B77_C6C65730507F__INCLUDED_)// Coder.cpp: implementation of the Coder class.////////////////////////////////////////////////////////////////////////#include "stdafx.h"#include "Coder.h"#include "Encoding.h"#ifdef _DEBUG#undef THIS_FILEstatic char THIS_FILE[]=__FILE__;#define new DEBUG_NEW#endif//////////////////////////////////////////////////////////////////////// Construction/Destruction////////////////////////////////////////////////////////////////////////初始化文件头常量/*static*/ const byte Coder::UNICODEBOM[2]={0xFF,0xFE};/*static*/ const byte Coder::UNICODEBEBOM[2]={0xFE,0xFF};/*static*/ const byte Coder::UTF8BOM[3]={0xEF,0xBB,0xBF};Coder::Coder(){ PREDEFINEDSIZE=2097152;//默认一次转换字节大小 2M字节}Coder::~Coder(){ }//繁体中文BIG5 转换成 简体中文 GB2312char* Coder::BIG5ToGB2312(const char* szBIG5Str){ CString msg; LCID lcid = MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC); wchar_t* szUnicodeBuff =MByteToWChar(CP_BIG5,szBIG5Str); char* szGB2312Buff =WCharToMByte(CP_GB2312,szUnicodeBuff); int nLength = LCMapString(lcid,LCMAP_SIMPLIFIED_CHINESE, szGB2312Buff,-1,NULL,0); char* pBuffer = new char[nLength + 1];if(!pBuffer) return NULL;memset(pBuffer,0,sizeof(char)*(nLength+1)); LCMapString(0x0804,LCMAP_SIMPLIFIED_CHINESE,szGB2312Buff,-1,pBuffer,nLength); delete[] szUnicodeBuff; delete[] szGB2312Buff; return pBuffer;}// GB2312 转 GBKchar* Coder::GB2312ToGBK(const char *szGB2312Str){ int nStrLen = strlen(szGB2312Str); if(!nStrLen) return NULL; LCID wLCID = MAKELCID(MAKELANGID(LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED), SORT_CHINESE_PRC); int nReturn = LCMapString(wLCID, LCMAP_TRADITIONAL_CHINESE, szGB2312Str, nStrLen, NULL, 0); if(!nReturn) return NULL; char *pcBuf = new char[nReturn + 1]; if(!pcBuf) return NULL; memset(pcBuf,0,sizeof(char)*(nReturn + 1)); wLCID = MAKELCID(MAKELANGID(LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED), SORT_CHINESE_PRC); LCMapString(wLCID, LCMAP_TRADITIONAL_CHINESE, szGB2312Str, nReturn, pcBuf, nReturn); return pcBuf;}// GBK 转换成 GB2312char* Coder::GBKToGB2312(const char *szGBKStr){int nStrLen = strlen(szGBKStr);if(!nStrLen)return NULL;LCID wLCID = MAKELCID(MAKELANGID(LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED), SORT_CHINESE_BIG5);int nReturn = LCMapString(wLCID, LCMAP_SIMPLIFIED_CHINESE, szGBKStr, nStrLen, NULL, 0);if(!nReturn)return NULL;char *pcBuf = new char[nReturn + 1];memset(pcBuf,0,sizeof(char)*(nReturn + 1));wLCID = MAKELCID(MAKELANGID(LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED), SORT_CHINESE_BIG5);LCMapString(wLCID, LCMAP_SIMPLIFIED_CHINESE, szGBKStr, nReturn, pcBuf, nReturn);return pcBuf;}//简繁中文GBK转换成繁体中文Big5char* Coder::GBKToBIG5(const char *szGBKStr){ char *pTemp=NULL;char *pBuffer=NULL;pTemp=GBKToGB2312(szGBKStr);pBuffer=GB2312ToBIG5(pTemp);delete[] pTemp;return pBuffer;}//繁体中文BIG5转换到简繁中文GBKchar* Coder::BIG5ToGBK(const char *szBIG5Str){ char *pTemp=NULL; char *pBuffer=NULL; pTemp=BIG5ToGB2312(szBIG5Str); pBuffer=GB2312ToGBK(pTemp); delete[] pTemp; return pBuffer;}//简体中文 GB2312 转换成 繁体中文BIG5char* Coder::GB2312ToBIG5(const char* szGB2312Str){ LCID lcid = MAKELCID(MAKELANGID(LANG_CHINESE,SUBLANG_CHINESE_SIMPLIFIED),SORT_CHINESE_PRC); int nLength = LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,-1,NULL,0); char* pBuffer=new char[nLength+1];if(!pBuffer)return NULL; LCMapString(lcid,LCMAP_TRADITIONAL_CHINESE,szGB2312Str,-1,pBuffer,nLength); pBuffer[nLength]=0; wchar_t* pUnicodeBuff = MByteToWChar(CP_GB2312,pBuffer); char* pBIG5Buff = WCharToMByte(CP_BIG5,pUnicodeBuff); delete[] pBuffer; delete[] pUnicodeBuff; return pBIG5Buff;} //获取文件编码类型//Unicode编码文件通过读取文件头判别//中文编码通过统计文件编码类别来判别 判别次数最多为30次 //中文编码的判别存在误差TextCode Coder::GetCodeType(CString filepath){ CFile file;byte buf[3];//unsigned charTextCode tctemp;if(file.Open(filepath,CFile::modeRead)){ file.Read(buf,3);if(buf[0]==UTF8BOM[0] && buf[1]==UTF8BOM[1] && buf[2]==UTF8BOM[2])return UTF8;elseif(buf[0]==UNICODEBOM[0] &&buf[1]==UNICODEBOM[1] )return UNICODE ;elseif(buf[0]==UNICODEBEBOM[0] &&buf[1]==UNICODEBEBOM[1] )return UNICODEBIGENDIAN; else{ int time=30;while(file.Read(buf,2) &&time ){ if ( (buf[0]>=176 && buf[0]<=247) && (buf[1]>=160 && buf[1]<=254) )tctemp=GB2312;elseif ( (buf[0]>=129 && buf[0]<=255) && ( ( buf[1]>=64 && buf[1]<=126) || ( buf[1]>=161 && buf[1]<=254) ) )tctemp=BIG5;elseif ( (buf[0]>=129 && buf[0] <=254) && (buf[1]>=64 && buf[1]<=254))tctemp=GBK;time--;file.Seek(100,CFile::current);//跳过一定字节 利于统计全文}return tctemp;}}elsereturn GB2312;}//多字节文件转换为UNICODE、UNICODE big endian文件BOOL Coder::MBFileToUnicodeFile(CString filesourcepath, CString filesavepath,TextCode tcTo,TextCode tcCur){ TextCode curtc; CFile filesource,filesave;; char *pChSrc=NULL; char *pChTemp=NULL; wchar_t *pwChDes=NULL; DWORD filelength,readlen,len; int bufferlen,strlength; UINT CodePage; //由于存在误差 允许用户自定义转换 if(tcCur!=DefaultCodeType) curtc=tcCur; else curtc=GetCodeType(filesourcepath); if(curtc>UTF8 || tcTo< UNICODE || curtc==tcTo) return FALSE; //源文件打开失败或者源文件无内容 后者保存文件建立失败 均返回转换失败 if(!filesource.Open(filesourcepath,CFile::modeRead) || 0==(filelength=filesource.GetLength())) return FALSE; if( !filesave.Open(filesavepath,CFile::modeCreate|CFile::modeWrite))return FALSE; //预分配内存 分配失败则转换失败 if(filelength<PREDEFINEDSIZE) bufferlen=filelength; else bufferlen=PREDEFINEDSIZE; pChSrc=new char[bufferlen+1]; if(!pChSrc)return FALSE; //根据当前文件类别指定转换代码页 switch(curtc) { case GB2312: CodePage=CP_GB2312; break; case GBK: CodePage=CP_GB2312;//特殊处理 break; case BIG5: CodePage=CP_BIG5; break; case UTF8: CodePage=CP_UTF8; break; default: break;} //UTF8文件跳过文件 if(UTF8==curtc) filesource.Seek(3*sizeof(byte),CFile::begin); //写入文件头 if(UNICODEBIGENDIAN==tcTo) filesave.Write(&UNICODEBEBOM,2*sizeof(byte)); else filesave.Write(&UNICODEBOM,2*sizeof(byte)); //读取文件 分段转换知道结束 while(filelength>0) { memset(pChSrc,0, sizeof(char)*(bufferlen+1)); if(filelength>PREDEFINEDSIZE) len=PREDEFINEDSIZE; else len=filelength; readlen=filesource.Read(pChSrc,len); if(!readlen)break; //GBK转换为GB2312处理 if(GBK==curtc) { pChTemp=pChSrc; pChSrc=GBKToGB2312(pChSrc); } pwChDes=MByteToWChar(CodePage,pChSrc); if(pwChDes) { if(UNICODEBIGENDIAN==tcTo) UnicodeEndianConvert(pwChDes); strlength=wcslen(pwChDes)*2;//这里注意写入文件的长度 filesave.Write(pwChDes,strlength); filesave.Flush(); filelength-=readlen; } else break; } delete[] pChSrc; delete[] pChTemp; delete[] pwChDes; return TRUE;}//wchar_t* Coder::MByteToWChar(UINT CodePage,LPCSTR lpcszSrcStr){LPWSTR lpcwsStrDes=NULL;int len=MultiByteToWideChar(CodePage,0,lpcszSrcStr,-1,NULL,0); lpcwsStrDes=new wchar_t[len+1];if(!lpcwsStrDes)return NULL;memset(lpcwsStrDes,0,sizeof(wchar_t)*(len+1)); len=MultiByteToWideChar(CodePage,0,lpcszSrcStr,-1,lpcwsStrDes,len);if(len)return lpcwsStrDes;else{ delete[] lpcwsStrDes;return NULL;}}char* Coder::WCharToMByte(UINT CodePage,LPCWSTR lpcwszSrcStr){char* lpszDesStr=NULL;int len=WideCharToMultiByte(CodePage,0,lpcwszSrcStr,-1,NULL,0,NULL,NULL);lpszDesStr=new char[len+1];memset(lpszDesStr,0,sizeof(char)*(len+1));if(!lpszDesStr)return NULL;len=WideCharToMultiByte(CodePage,0,lpcwszSrcStr,-1,lpszDesStr,len,NULL,NULL);if(len)return lpszDesStr;else{ delete[] lpszDesStr;return NULL;}} //Unicode 和Unicode big endian之间字节序的转换void Coder::UnicodeEndianConvert(LPWSTR lpwszstr){ wchar_t wchtemp[2]; long index; int len=wcslen(lpwszstr); if(!len) return; //交换高低字节 直到遇到结束符 index=0; while( index<len) { wchtemp[0]=lpwszstr[index]; wchtemp[1]=lpwszstr[index+1]; unsigned char high, low; high = (wchtemp[0] & 0xFF00) >>8; low = wchtemp[0] & 0x00FF; wchtemp[0] = ( low <<8) | high; high = (wchtemp[1] & 0xFF00) >>8; low = wchtemp[1] & 0x00FF; wchtemp[1] = ( low <<8) | high; lpwszstr[index]=wchtemp[0]; lpwszstr[index+1]=wchtemp[1]; index+=2; }}//Unicode和Unicode big endian文件向多字节文件转换BOOL Coder::UnicodeFileToMBFile(CString filesourcepath, CString filesavepath,TextCode tcTo){ TextCode curtc;CFile filesource,filesave;;char *pChDes=NULL;char *pChTemp=NULL;wchar_t *pwChSrc=NULL;DWORD filelength,readlen,len;int bufferlen,strlength;UINT CodePage;curtc=GetCodeType(filesourcepath);//文件转换类型错误 则转换失败if(curtc<=UTF8 || tcTo>UTF8 || curtc==tcTo)return FALSE; //源文件打开失败或者源文件无内容 后者保存文件建立失败 均转换失败 if(!filesource.Open(filesourcepath,CFile::modeRead) || 0==(filelength=filesource.GetLength()))return FALSE;if( !filesave.Open(filesavepath,CFile::modeCreate|CFile::modeWrite))return FALSE;//预分配内存 分配失败则转换失败if(filelength<PREDEFINEDSIZE)bufferlen=filelength;elsebufferlen=PREDEFINEDSIZE;pwChSrc=new wchar_t[(bufferlen/2)+1];if(!pwChSrc)return FALSE;//预先决定代码页switch(tcTo){ case GB2312:CodePage=CP_GB2312;break;case GBK:CodePage=CP_GB2312;//特殊处理break;case BIG5: CodePage=CP_GB2312;//特殊处理break;case UTF8:CodePage=CP_UTF8;break;default:break;}filesource.Seek(sizeof(wchar_t),CFile::begin);while(filelength>0){memset(pwChSrc,0,sizeof(wchar_t)*((bufferlen/2)+1));if(filelength>PREDEFINEDSIZE)len=PREDEFINEDSIZE;elselen=filelength;readlen=filesource.Read(pwChSrc,len);if(!readlen)break;if(UNICODEBIGENDIAN==curtc)UnicodeEndianConvert(pwChSrc);pChDes=WCharToMByte(CodePage,pwChSrc);//GBK无法直接转换 BIG5直接转换会产生错误 二者均先转到GB2312然后再转到目的类型if(GBK==tcTo){pChTemp=pChDes;pChDes=GB2312ToGBK(pChDes);}if(BIG5==tcTo){pChTemp=pChDes;pChDes=GB2312ToBIG5(pChDes);}if(pChDes){ strlength=strlen(pChDes);filesave.Write(pChDes,strlength);filesave.Flush();filelength-=readlen;}elsebreak;} delete[] pChDes;delete[] pChTemp;delete[] pwChSrc;return TRUE;}//多字节文件转为多字节文件//多字节转为多字节时,一般先转为UNICODE类型,再转换到指定目的类型,实行两次转换BOOL Coder::MBFileToMBFile(CString filesourcepath, CString filesavepath,TextCode tcTo,TextCode tcCur){BOOL bret=FALSE;TextCode curtc;CFile filesource,filesave;char *pChDes=NULL;char *pChSrc=NULL;DWORD filelength,readlen,len;int bufferlen,strlength;UINT CodePageCur,CodePageTo;//由于存在误差 允许用户自定义转换if(DefaultCodeType!=tcCur) curtc=tcCur;elsecurtc=GetCodeType(filesourcepath);//转换类型错误 则返回转换失败if(curtc>UTF8 || tcTo>UTF8 || curtc==tcTo)return FALSE;//源文件打开失败或者源文件无内容 后者保存文件建立失败 均返回转换失败 if(!filesource.Open(filesourcepath,CFile::modeRead) || 0==(filelength=filesource.GetLength()))return FALSE;if( !filesave.Open(filesavepath,CFile::modeCreate|CFile::modeWrite))return FALSE;//预分配内存 分配失败则转换失败if(filelength<PREDEFINEDSIZE)bufferlen=filelength;elsebufferlen=PREDEFINEDSIZE; pChSrc=new char[bufferlen+1];if(!pChSrc)return FALSE;if(UTF8==curtc)filesource.Seek(3*sizeof(byte),CFile::begin);CodePageCur=GetCodePage(curtc); CodePageTo=GetCodePage(tcTo);while(filelength>0){ memset(pChSrc,0,sizeof(char)*(bufferlen+1)); if(filelength>PREDEFINEDSIZE)len=PREDEFINEDSIZE;elselen=filelength;readlen=filesource.Read(pChSrc,len);if(!readlen)break;pChDes=MByteToMByte(CodePageCur,CodePageTo,pChSrc);if(pChDes){ strlength=strlen(pChDes);filesave.Write(pChDes,strlength);filelength-=readlen;}elsebreak;}delete[] pChSrc;delete[] pChDes;return TRUE;}//Unicode 和Unicode big endian文件之间转换BOOL Coder::UnicodeEndianFileConvert(CString filesourcepath, CString filesavepath,TextCode tcTo){TextCode curtc=GetCodeType(filesourcepath);if(curtc!=UNICODE && curtc!=UNICODEBIGENDIAN)return FALSE;if(curtc==tcTo)return FALSE;CFile filesource,filesave;;wchar_t *pwChDes;DWORD length; if(!filesource.Open(filesourcepath,CFile::modeRead) || !filesave.Open(filesavepath,CFile::modeCreate|CFile::modeWrite))return FALSE;length=filesource.GetLength();if(!length)return FALSE;pwChDes=new wchar_t[(length/2)+1];if(!pwChDes)return FALSE;memset(pwChDes,0,sizeof(wchar_t)*((length/2)+1));filesource.Read(pwChDes,length);UnicodeEndianConvert(pwChDes);length=wcslen(pwChDes)*2;if(UNICODE==tcTo) filesave.Write(&UNICODEBOM,2*sizeof(byte));elsefilesave.Write(&UNICODEBEBOM,2*sizeof(byte));filesave.Write(pwChDes,length);filesave.Flush();delete[] pwChDes;return TRUE;}//文件转到另一种文件//6种格式文件两两转换 共计30种转换BOOL Coder::FileToOtherFile(CString filesourcepath, CString filesavepath, TextCode tcTo,TextCode tcCur){ TextCode curtc;BOOL bret=FALSE;if(DefaultCodeType!=tcCur) curtc=tcCur;else curtc=GetCodeType(filesourcepath);if(curtc==tcTo)return FALSE;//UNICODE和UNICODE big endian文件之间转换 共2种if(curtc>=UNICODE&& tcTo>=UNICODE)bret=UnicodeEndianFileConvert(filesourcepath,filesavepath,tcTo);else//多字节文件向 UNICODE和UNICODE big endian文件之间转换 共8种if(curtc<UNICODE && tcTo>=UNICODE)bret=MBFileToUnicodeFile(filesourcepath,filesavepath,tcTo,curtc);else//UNICODE和UNICODE big endian文件向多字节文件转换 共8种if(curtc>=UNICODE && tcTo<UNICODE)bret=UnicodeFileToMBFile(filesourcepath,filesavepath,tcTo);else//多字节文件之间转换 共12种if(curtc<UNICODE && tcTo<UNICODE)bret=MBFileToMBFile(filesourcepath,filesavepath,tcTo,curtc);return bret;}//编码类型转换为字符串CString Coder::CodeTypeToString(TextCode tc){ CString strtype; switch(tc) { case GB2312: strtype=_T("GB2312"); break; case BIG5: strtype=_T("Big5"); break; case GBK: strtype=_T("GBK"); break; case UTF8: strtype=_T("UTF-8"); break; case UNICODE: strtype=_T("Unicode"); break; case UNICODEBIGENDIAN: strtype=_T("Unicode big endian"); break; } return strtype;}//多字节向多字节转换char* Coder::MByteToMByte(UINT CodePageCur, UINT CodePageTo, const char* szSrcStr){char *pchDes=NULL;char *pchTemp=NULL;wchar_t *pwchtemp=NULL;//三种中文编码之间转换if(CodePageCur!=CP_UTF8 && CodePageTo!=CP_UTF8){switch(CodePageCur){case CP_GB2312:{if(CP_BIG5==CodePageTo) pchDes=GB2312ToBIG5(szSrcStr);else pchDes=GB2312ToGBK(szSrcStr);break;}case CP_BIG5:{ if(CP_GB2312==CodePageTo)pchDes=BIG5ToGB2312(szSrcStr);elsepchDes=BIG5ToGBK(szSrcStr); break;}case CP_GBK:{ if(CP_GB2312==CodePageTo)pchDes=GBKToGB2312(szSrcStr);elsepchDes=GBKToBIG5(szSrcStr); break;}}}else{ //从UTF-8转到其他多字节 直接转到GB2312 其他形式用GB2312做中间形式 if(CP_UTF8==CodePageCur) { pwchtemp=MByteToWChar(CodePageCur,szSrcStr);if(CP_GB2312==CodePageTo){pchDes=WCharToMByte(CP_GB2312,pwchtemp);}else{ pchTemp=WCharToMByte(CP_GB2312,pwchtemp); if(CP_GBK==CodePageTo)pchDes=GB2312ToGBK(pchTemp); elsepchDes=GB2312ToBIG5(pchTemp);} } //从其他多字节转到UTF-8 else { if(CP_GBK==CodePageCur) { pchTemp=GBKToGB2312(szSrcStr); pwchtemp=MByteToWChar(CP_GB2312,pchTemp); } elsepwchtemp=MByteToWChar(CodePageCur,szSrcStr); pchDes=WCharToMByte(CodePageTo,pwchtemp); }} delete[] pchTemp;delete[] pwchtemp;return pchDes;}//获取编码类型对应的代码页UINT Coder::GetCodePage(TextCode tccur){ UINT CodePage; switch(tccur) { case GB2312: CodePage=CP_GB2312; break; case BIG5: CodePage=CP_BIG5; break; case GBK: CodePage=CP_GBK; break; case UTF8: CodePage=CP_UTF8; break; case UNICODEBIGENDIAN: case UNICODE: break;} return CodePage;}//指定转换时默认一次转换字节大小void Coder::SetDefaultConvertSize(UINT nCount){ if(nCount!=0)PREDEFINEDSIZE=nCount;}
3.运行效果
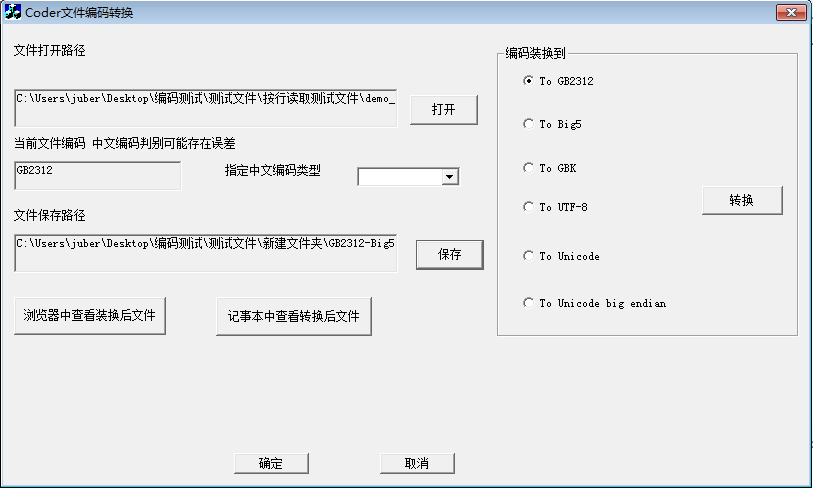
在win7 VC 6.0下测试六种编码的转换测试通过,30个方向的转换如下图所示:
GB2312转换到GBK编码效果如下图所示:

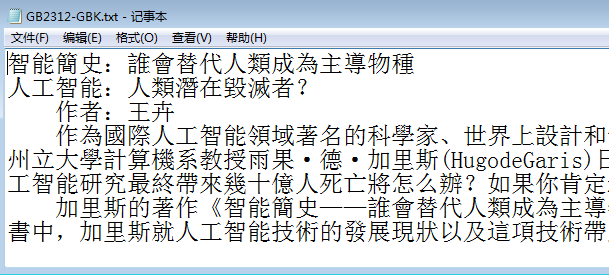

本文代码及转码程序下载 :http://download.csdn.net/user/ziyuanxiazai123
4.尚未解决的问题
(1)LCMapString函数的理解还不完全熟悉,其中参数偏多,理解需要一定基础知识。
(2)为什么记事本程序的转码后存在些乱码,乱码是正确的吗?因为我的程序使用了中间过渡形式,因此没有任何乱码。
(3)是否有更简单和清晰的方式实现编码转换,待进一步研究。
转自:http://blog.csdn.net/ziyuanxiazai123/article/details/7495690
- 一网打尽中文编码转换---6种编码30个方向的转换
- 一网打尽中文编码转换---6种编码30个方向的转换
- 一网打尽中文编码转换
- 中文编码转换---6种编码30个方向的转换
- 中文编码转换---6种编码30个方向的转换
- 6种编码30个方向的转换
- 中文编码的转换
- 中文编码规则一网打尽
- 中文编码规则一网打尽
- 中文编码规则一网打尽
- 中文编码规则一网打尽
- 中文编码之间的转换
- 中文编码转换说明
- 中文编码转换工具
- 中文编码转换说明
- url中文编码转换
- 中文编码转换技巧
- 中文乱码,转换编码
- 模拟一个信号灯的软件
- 李彦宏:牛人小的时候就很牛了——李彦宏早年顶级论文曝光
- Cookie多应用共享使用
- Eclipse安装插件支持jQuery智能提示
- linux哲学引发的(一)
- 一网打尽中文编码转换---6种编码30个方向的转换
- [深入理解C++(二)]理解接口继承规则
- OSI的七层协议
- /C++ 指针的指针:
- eclipse各种常用插件在线安装.txt
- Windows程序的窗口和消息 -- 一个Windows程序从生到死
- lucene预研
- android 点9 启动方法
- Java调用外部程序解决方案


