Trie树
来源:互联网 发布:ios软件开发入门 编辑:程序博客网 时间:2024/06/06 04:38
1、 概述
Trie树,又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构,如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树。
Trie一词来自retrieve,发音为/tri:/ “tree”,也有人读为/traɪ/ “try”。
Trie树可以利用字符串的公共前缀来节约存储空间。如下图所示,该trie树用10个节点保存了6个字符串tea,ten,to,in,inn,int:

在该trie树中,字符串in,inn和int的公共前缀是“in”,因此可以只存储一份“in”以节省空间。当然,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存,这也是trie树的一个缺点。
Trie树的基本性质可以归纳为:
(1)根节点不包含字符,除根节点意外每个节点只包含一个字符。
(2)从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
(3)每个节点的所有子节点包含的字符串不相同。
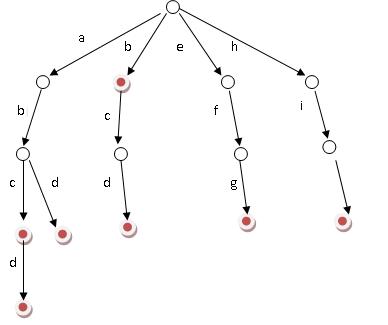
下图是一个trie树的例子:
从图中可以知道,从跟节点开始遍历树的话,在一个路径上会生成单词(当然不一定遍历到叶子节点,图中是叶子节点才形成一个单词,但实际中并不一定这样的。可以在路径中的某个子路径上形成一个单词,当然这样的话需要通过一定的标记来说明一个单词已经形成了)

可以通过下面的结构来定义trie树:
#define MAX_CHILD 26 //这里使用26,我们只用来分析小写的英文字母构成的trie树,不考虑数字等其他字符,如果要考虑这些的话,可以将MAX_CHILD定义为256,这样就包括了所有的ascii码了
typedef struc trie_node
{
int count; //用于标记在该节点是否可以形成一个单词;如果count不等于0则表示从跟节点到该节点的路径构成一个单词
struct trie_node *child[MAX_CHILD];//用来标记孩子节点,例如child[0]就表示字符’a’;child[1]表示‘b’等。这里就可以看作是用位置来表示一个字符,如果该位置的指针不为空,那么就表示该字符是存在的。
}node, *tree;
考虑下图的话:对于根节点,他的第0、1、4、7个子节点是不为空的,表示字符a、b、e、h是在trie树中的。同理对于子节点a来说,他的第1个子节点是不为空的,因此字符b在子节点a构成的trie树中的。其他的同理。
这样的话就表示字符串abcd是在trie树中的。等等。
在下图中有用红色标记的节点,这个可以理解为count不为0的节点,即到该节点为止,可以形成一个单词。因此下图中也包含b、abc、abd这些单词。
上面基本是对trie树的一个整体介绍。
2、trie树的操作
对trie树的操作主要包括插入、查找等操作。对trie树插入一个字符串,其实就是遍历该字符串,然后将每一位分别插入到相应的位置。
insert操作:
void insert_node(tree *root, char *str)
{
if(str == NULL)//如果str为空,那么直接返回
{
return;
}
node *t = *root;
char *p = str;
while(*p != ‘/0’)
{
if(NULL == t->child[*p – ‘a’]) //如果对应子节点为空(这里计算出位置),同时这里只考虑小写字母
{
node *temp = malloc(sizeof(node));
memset(temp, 0, sizeof(node));
t->child[*p – ‘a’] = temp;
}
t = t->child[*p – ‘a’];
p++;
}
t->count++; //这里表示一个字符串的遍历已经结束,需要做一个标记来标识树中字符串的结尾
}
上面就是trie树的插入操作一个简单实现。
下面给出查找一个字符串是否在trie中的实现:
void search_str(tree root, const char *str)
{
if(NULL == root)
{
printf(“tree is empty./n”);
return;
}
char *p = str;
node *t = root;
while(*p != ‘/0’)
{
if(t->child[*p – ‘a’] != NULL)
{
t = t->child[*p – ‘a’];
}
else
{
break;
}
}
if(*p == ‘/0’)
{
if(t->count == 0)//字符串已经遍历完,但对于的节点count != 0,则说明字符串是不存在trie树中的
{
//字符串不存在在trie中,但字符串是树中某个单词的前缀。
}
else
{
//说明字符串是在树中的
}
}
else
{
//这里说明是从break出来的,说明字符串是不在树中的,因为字符串中的某些字符是不在路径中的。
}
}
通过上面的操作就可以简单的进行字符串查找的工作了。逐步判断字符串的每个字符是否可以构成trie树的一个路径。
3、trie树应用
从trie树的定义中,我们很容易发现trie的典型应用就是判断一个字符串是否在某个集合中。例如给定一个字典,里面包含了所有的英文单词,现在任意给一个字符串,判断该字符串是否是一个英文单词。当然可以通过遍历字典集合来判断字符串是否在字典中。另外一种方法就是通过将字典的单词集合建立一棵trie树,然后在trie树中查找字符串是否存在,这是一个用空间换时间的操作。
下面给出一些trie树的应用:
3.1
POJ2503问题:
Description
You have just moved from Waterloo to a big city. The people here speak an incomprehensible dialect of a foreign language. Fortunately, you have a dictionary to help you understand them.
Input
Input consists of up to 100,000 dictionary entries, followed by a blank line, followed by a message of up to 100,000 words. Each dictionary entry is a line containing an English word, followed by a space and a foreign language word. No foreign word appears more than once in the dictionary. The message is a sequence of words in the foreign language, one word on each line. Each word in the input is a sequence of at most 10 lowercase letters.
Output
Output is the message translated to English, one word per line. Foreign words not in the dictionary should be translated as "eh".
Sample Input
dog ogday
cat atcay
pig igpay
froot ootfray
loops oopslay
atcay
ittenkay
oopslay
Sample Output
cat
eh
loops
Hint
Huge input and output,scanf and printf are recommended.
这是问题的描述,简单的说其实就是一个翻译功能,给一个你不熟悉的语言单词,把他翻译成对应的英文(这里假设你熟悉的是英文)。
其实这个问题有多种解法:
a、可以使用c++中的map进行求解map<Foreign words , english>这样进行查找
b、利用hash。将foreign words进行hash,对应的hash位置保存该foreigh words对应的english单词,这样也可以,不过需要处理冲突。
c、当然也可以先对序列进行排序,然后进行查找。比如快排+二分查找也是可以的。
当然这篇文章主要讲的是trie树,这个问题肯定也可以利用trie树来解决。
d、利用trie树解决。用foreign word的字符序列作为trie树的节点,在序列结束的位置用对应的英文单词来标记即可。具体结构如下:
typedef struct trie_node
{
char english[LEN]; //用来保存对应的英文单词
struct trie_node *child[26];
};
其实就是将上面的insert_node操作的count改成了english标识
void insert_node(tree *root, char *str)
{
if(str == NULL)//如果str为空,那么直接返回
{
return;
}
node *t = *root;
char *p = str;
while(*p != ‘/0’)
{
if(NULL == t->child[*p – ‘a’]) //如果对应子节点为空(这里计算出位置),同时这里只考虑小写字母
{
node *temp = malloc(sizeof(node));
memset(temp, 0, sizeof(node));
t->child[*p – ‘a’] = temp;
}
t = t->child[*p – ‘a’];
p++;
}
memcpy(t->english, english);//这里表示一个字符串的遍历已经结束,需要做一个标记来标识树中字符串的结尾,这个标记是该foreign word对应的english单词,这里用english表示。
}
这就是主要的插入操作,在查找时,匹配完一个查找序列后查看该节点的english域是否为空,如果为空,那么就说明要查找的序列是不在树中的,否则是在树中的。
3.2)判断一个字符串是否是另外一个字符串的前缀
这个问题也可以利用trie树来解决。
其实很多前缀的问题都可以利用trie树来解决。
3.3)其他应用
其他应用后续再慢慢增加
4、总结:
trie树是一种比较高效的数据结构,主要思想是利用空间来换取时间;同时trie树存储了序列中的公共部分,其实空间上也有所减少。trie树在序列匹配、序列查找、前缀匹配、信息检索等有很多好的应用,是一个很值得学习和掌握的数据结构。同时与trie树类似的还有其他的一些数据结构,我会在后续的文章中进行学习和分析。
5、参考
下面是主要的参考资料:
http://dongxicheng.org/structure/trietree/
http://blog.csdn.net/jiqiren007/article/details/6554456
http://www.cnblogs.com/galaxyprince/ 这篇文章介绍了3种不同的trie树
http://acm.sdut.edu.cn/bbs/read.php?tid=1091 //这篇介绍了POJ2503的题目,以及给出了一个具体的实现。
http://www.cnblogs.com/springfield/archive/2010/06/16/1758450.html //这篇文章给出了一个前缀的例子
http://www.allisons.org/ll/AlgDS/Tree/Trie/ //这里也有介绍
http://en.wikipedia.org/wiki/Trie //当然wiki里面有比较详细的介绍
博文《字典树的简介及实现》:
http://hi.baidu.com/luyade1987/blog/item/2667811631106657f2de320a.html
论文《浅析字母树在信息学竞赛中的应用》
论文《Trie图的构建、活用与改进》
博文《An Implementation of Double-Array Trie》:
http://linux.thai.net/~thep/datrie/datrie.html
论文《An Efficient Implementation of Trie Structures》:
http://www.google.com.hk/url?sa=t&source=web&cd=4&ved=0CDEQFjAD&url=http%3A%2F%2Fciteseerx.ist.psu.edu%2Fviewdoc%2Fdownload%3Fdoi%3D10.1.1.14.8665%26rep%3Drep1%26type%3Dpdf&ei=qaehTZiyJ4u3cYuR_O4B&usg=AFQjCNF5icQbRO8_WKRd5lMh-eWFIty_fQ&sig2=xfqSGYHBKqOLXjdONIQNVw
- hihoCoder1014 Trie树 [Trie]
- TRIE树
- TRIE树
- TRIE树
- trie 树
- Trie树
- Trie树
- Trie树
- Trie树
- trie树
- trie树
- Trie 树
- Trie树
- Trie 树
- trie 树
- Trie树
- Trie树
- Trie树
- [转]Chrome+GoAgent+SwitchySharp教程
- fastcgi协议分析
- 如何制作动态图表
- 美化ComboBox下拉
- SQL Server 2005 控制用户权限访问表
- Trie树
- SQL解发器与SQL游标实例
- 双链表实现
- Nginx代理服务器
- 归并排序
- linux解压和压缩命令大全
- JDBC和Ibatis中的Date,Time,Timestamp处理
- Linux的几个常用小功能
- Java 如何根据指定的范围获取随机数


