Linux 抓取网页实例(shell+awk)
来源:互联网 发布:理财哪个软件好 编辑:程序博客网 时间:2024/05/01 22:07
要抓取google play游戏排名网页,首先需要分析网页的特点和规律:
1、google play游戏排名网页,是一个就“总-分”形式,即一页网址显示若干排名(如24个),有若干个这样的网页组成全部游戏的总排名
2、每页网址中,点击每个单独的游戏连接,可以查看本游戏的属性信息(如评价星级、发布日期、版本号、SDK版本号、游戏类别、下载量等)
需要解决的问题:
1、如何抓取全部游戏总排名?
2、抓取到总排名后,如何拼接URL来抓取每个单独的游戏网页?
3、抓取到每个单独游戏网页后,如何提取网页中游戏的属性信息(即评价星级、发布日期。。。)?
4、提取到了每个单独游戏属性信息后,如何保存(mysql)、生成每日报表(html)、发送每日报表(email)?
5、根据抓取的游戏属性信息资源,如何查询自己公司的游戏排名(JSP)、如何清晰的展现游戏排名(JFreeChart图表)?
6、更难的是,google play游戏排名,并没有全球统一的排名,google采用本地化策略,几十个国家都有自己的一套排名算法和规则,如何实现12国游戏排名?
设计方案和技术选择
分析完上述的这些问题需求后,如何逐一解决,各个击破,便是需要我们思考、设计和解决的问题(模块流程和技术实现)?
基于上面分析提出的问题,下面将逐一进行模块设计、技术方案选择:

1、为了抓取12国的游戏排名,需要分别在12国租用代理服务器,才能抓取各国的游戏排名(12国游戏排名算法、语言都不同,有中文、英文、日语、俄语、西班牙语...)
2、抓取网页,使用curl+proxy代理的方式;提取下载的网页信息,使用awk文本分析工具(需要对html语法tag、id等元素非常了解,才能准确利用awk提取游戏属性信息)
3、由于IP代理筛选系统、抓取网页程序、提取游戏属性信息等模块全部都是利用脚本完成,为了保持程序语言的一致性,数据库的创建、记录插入也都是用shell脚本实现
4、抓取的每个游戏属性信息,采用html+table以网页的形式展现出来,清晰、直观。其中使用到了shell脚本来拼接html字符串(table + tr + td + info)
5、生成的html网页,每日以邮件形式定时发给产品总监、PM,以及RD和QA,了解公司发布的游戏排名情况,以及全球排名上升最快、最热门的游戏趋势
6、开发一个JSP网页查询系统,根据输入的游戏名称或游戏包名两种方式查询一个游戏的排名及趋势,且在趋势图下面显示该游戏的详细的全部属性信息
模块技术实现
1、IP代理筛选
费用考虑,每个国家租用一台代理服务器(VPN),按市场最低价1000元/月计,一年12000元,12国家总费用为12x12000=144000,即大约需要14万/年的VPN租借费用
基于成本开销的考虑,后来我通过深入调研代理服务器和免费ip,提出了自己设计开发一套免费ip代理服务器筛选系统,来分别抓取12国游戏排名
免费代理IP主要来源于上一篇博客中介绍的两个网站:freeproxylists.net 和xroxy.com
IP代理筛选系统,由于文本预处理和筛选逻辑实现都较为复杂,将在下一篇博客中单独介绍
2、抓取排名网页
仔细分析google play游戏排名网页,可以发现是有规律可循:
第一页Top24网址:https://play.google.com/store/apps/category/GAME/collection/topselling_free
第二页Top48网址:https://play.google.com/store/apps/category/GAME/collection/topselling_free?start=24&num=24
第三页Top72网址:https://play.google.com/store/apps/category/GAME/collection/topselling_free?start=48&num=24
。。。
至此,观察每页网址最后的一段字符串 ?start=24&num=24 ,已经发现规律了吧 ^_^ 其实第一页的网页从start=0开始,也可以写成:
第一页Top24网址:https://play.google.com/store/apps/category/GAME/collection/topselling_free?start=0&num=24
根据上面的规律,就可以通过循环拼接字符串,用curl+proxy来抓取排名网页了(start = 'expr $start + 24')
3、提取游戏链接
排名网页,每页包含24个游戏网址超链接,如何提取到这24个游戏网址超链接?
当时考虑过使用xml解析,因为html都是层级组织起来的类xml格式,但有些网页也不全是标准的html格式(如左括号后没有右括号闭包),这会导致xml无法正确解析
后来结合自己学过的html和js知识,分析抓取排名网页的内容结构,发现每个游戏链接前面都还有一个唯一的 class="title" 具体格式如下(Basketball Shoot 为例):
- <a class="title" title="Basketball Shoot" data-a="1" data-c="1"href="/store/apps/details?id=com.game.basketballshoot&feature=apps_topselling_free">Basketball Shoot</a>
这样,可以顺利通过awk来提取 class="title" 附近的文本内容,具体实现如下:
- # split url_24
- page_key='class="title"'
- page_output='output_page.log'
- page_output_url_start='https://play.google.com/store/apps/'
- page_output_url='output_top800_url.log'
- function page_split(){
- grep $page_key $(ls $url_output* | sort -t"_" -k6 -n) > tmp_page_grepURL.log # use $url_output
- awk -F'[<>]' '{for(i=1;i<=NF;i++){if($i~/'$page_key'/){print $i}}}' tmp_page_grepURL.log > tmp_page_titleURL.log
- awk -F'["""]' '{print $4 $10}' tmp_page_titleURL.log >$page_output
- rm -rf tmp_page_grepURL.log
- rm -rf tmp_page_titleURL.log
- merge top800 url
- rm -rf $page_output_url
- touch $page_output_url
- awk -F'["/"]' '{for(i=1;i<=NF;i++){if($i~/'details'/){print $i}}}'$page_output > tmp_top800_url.log
- index=1
- while read line
- do
- echo $line
- echo $index
- echo -e $page_output_url_start$line >>$page_output_url
- index=`expr $index + 1`
- done < tmp_top800_url.log
- rm -rf tmp_top800_url.log
- }
脚本功能说明:
grep,首先对下载的排名网页文件,按照编号从小到大排列,保证游戏的排名顺序;然后利用grep提取我们需要的某些行到临时文件,大大减少我们需要分析的文件内容
awk,指定多个分隔符“<>”来格式化输入的文本(awk -F'[<>]')为多个子字符串数组,通过循环判断分割的子字符串数组中是否包含有$page_key字符串(if($i~/'$page_key'/))。如果有,则把此子字符串全部输出到另一临时文件中tmp_page_titleURL.log中;如果没有,则舍弃。
格式化后提取的游戏超链接如下:

上图,文本处理后包含游戏的名称(title)和游戏的超链接(href),接下来就是提取游戏名称(title)和游戏超链接(href),最后拼接href和域名组成一个完整的超链接
awk,指定分隔符“”“来格式化上图的文本(awk -F'["""]')为多个子字符串数组,然后提取数组的第4个和第10个字段(awk分割的字段以下标1开始),提取结果如下:

上图,进一步文本处理后,提取出了游戏名称(title)和游戏链接(href),接着再提取我们真正需要的链接信息(details后的字符串)
通过临时文件保存了我们文本处理的中间结果,处理完后可以把创建的临时文件删除(rm -rf ***)
awk,指定分隔符”/“来格式化上图的文本(awk -F'["/"]')为多个子字符串数组,通过循环判断分割的子字符串数组中是否包含有'details'字符串(if($i~/'details'/))。如果有,则把此子字符串全部输出到临时文件中tmp_top800_url.log中;如果没有,则舍弃。
格式化后提取的游戏超链接如下:
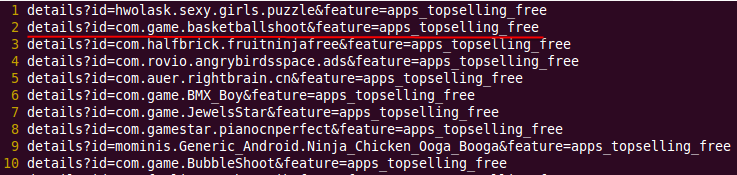
最后,while read line循环,添加域名头($page_output_url_start),拼接出完整超链接地址(echo -e $page_output_url_start$line >> $page_output_url),拼接结果如下:

ok,通过awk强大的文本处理能力,游戏网页超链接处理完毕(千呼万唤始出来呀~~)!下面就是利用 curl+proxy 抓取对应的游戏网页了。。。。 O(∩_∩)O
4、抓取游戏网页
根据模块3提取的游戏超链接,利用上篇博客介绍的curl+proxy方式抓取游戏网页,示例如下:
curl -x 125.69.132.100:8080-o html_2 https://play.google.com/store/apps/details?id=com.game.basketballshoot&feature=apps_topselling_free
利用浏览器打开抓取下来的网页html_2,结果截图如下:
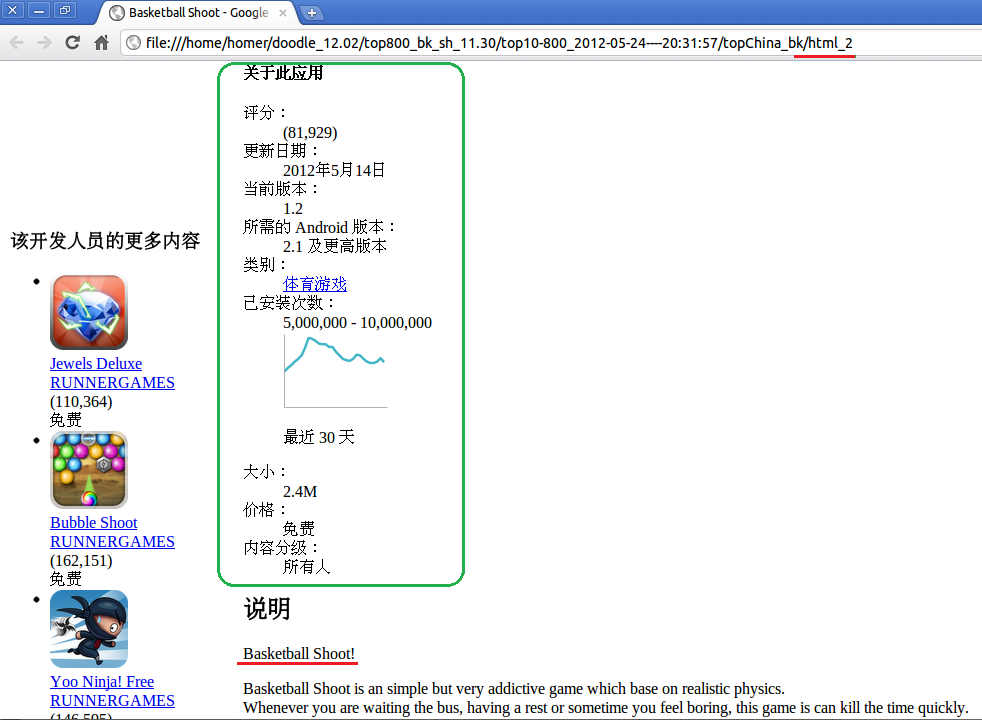
ok,成功抓取到了游戏网页,下一步就是提取每个游戏网页总绿色框内的游戏属性信息即可(提取方式与模块3提取游戏链接方法类似,也是使用awk文本分析处理工具)
不过,这里需要注意几点:
- 在我的脚本程序中通过代理抓取网页的语句,比上面给出的要复杂一些,主要是实际测试中考虑到了连接超时、网速快慢、ip代理突然失效等特殊情况,在此不贴具体代码,感兴趣的同学可以自己研究一下
- 在下载游戏网页的过程中,如果代理ip突然失效,导致无法继续抓取网页,这时该怎么办?(其实上面模块2抓取排名网页,也会遇到此问题,这个问题具体的解决方案,在下篇博客的ip免费代理系统中将做详细介绍)
- 抓取下来的游戏网页,如何确定他们的排名顺序?(其实在模块3中,这个游戏排名问题已经解决了,细心的童靴可以自己去上面模块3的脚本中寻找答案。。。)
5、提取游戏属性
提取抓取游戏网页中的属性信息(即提取上面模块4的html_2中的绿色方框信息),提取方式与模块3提取游戏链接方法类似,也是使用awk文本分析处理工具
通过分析下载的网页内容,找出唯一能够表示属性信息的字段(如id、class、tag等),具体实现代码请参考模块3给出的脚本,在此不再贴出具体实现代码
6、保存属性到数据库
- 要保存提取的游戏属性信息,首先需要创建MySQL数据库和表,shell创建数据库脚本如下:
- # Author : yanggang
- # Datetime : 2011.10.24 21:10:28
- # ============================================================
- #!/bin/sh
- log='SQL_insert_one.sh.log'
- if [ ! -e $log ]; then
- touch $log
- fi
- date=$(date "+%Y-%m-%d__%H:%M:%S")
- echo >> $log
- echo "================= $date ================" >>$log
- # mysql database and table to create
- HOST='localhost'
- PORT='3306'
- USER='root'
- PWD='xxxxxx'
- DBNAME='top800'
- TABLENAME='gametop800'
- mysql_login=''
- mysql_create_db=''
- mysql_create_table=''
- function mysql_create(){
- echo "login mysql $HOST:$PORT ..." >>$log
- mysql_login="mysql -h $HOST -P $PORT -u $USER -p$PWD" # mysql -h host -P port -u root -p pwd
- echo | ${mysql_login}
- if [ $? -ne 0 ]; then
- echo "login mysql ${HOST}:${PORT} failed.." >>$log
- exit 1
- else
- echo "login mysql ${HOST}:${PORT} success!" >>$log
- fi
- echo "create database $DBNAME ..." >>$log
- mysql_create_db="create database if not exists $DBNAME"
- echo ${mysql_create_db} | ${mysql_login}
- if [ $? -ne 0 ]; then
- echo "create db ${DBNAME} failed.." >>$log
- else
- echo "create db ${DBNAME} success!" >>$log
- fi
- echo "create table $TABLENAME ..." >>$log
- mysql_create_table="create table $TABLENAME(
- id char(50) not null,
- url char(255),
- top int,
- name char(100),
- category char(50),
- rating char(10),
- ratingcount char(20),
- download char(30),
- price char(20),
- publishdate char(20),
- version char(40),
- filesize char(40),
- requireandroid char(40),
- contentrating char(40),
- country char(10) not null,
- dtime date not null default \"2011-01-01\",
- primary key(id, country, dtime)
- )"
- echo ${mysql_create_table} | ${mysql_login} ${DBNAME}
- if [ $? -ne 0 ]; then
- echo "create table ${TABLENAME} fail..." >>$log
- else
- echo "create table ${TABLENAME} success!" >>$log
- fi
- }
- 遍历游戏属性信息的文本,全部插入到mysql数据库中,进行统一保存和管理
- # Author : yanggang
- # Datetime : 2011.10.24 21:45:09
- # ============================================================
- #!/bin/sh
- # insert mysql
- file_input='output_top800_url_page'
- file_output='sql_output'
- HOST='localhost'
- PORT='3306'
- USER='root'
- PWD='xxxxxx'
- DBNAME='top800'
- TABLENAME='gametop800'
- col_id=''
- col_url=''
- col_top=1
- col_name=''
- col_category=''
- col_rating=''
- col_ratingcount=''
- col_download=''
- col_price=''
- col_publishdate=''
- col_version=''
- col_filesize=''
- col_requireandroid=''
- col_contentrating=''
- col_country=''
- col_dtime=''
- sql_insert='insert into gametop800 values("com.mobile.games", "url", 3, "minesweeping", "games", "4.8", "89789", "1000000-5000000000", "free", "2011-2-30", "1.2.1", "1.5M", "1.5 up", "middle", "china", "2011-10-10")'
- function mysql_insert(){
- rm -rf $file_output
- touch $file_output
- DBNAME=$1
- col_dtime=$2
- col_country=$3
- echo 'col_dtime========='$col_dtime
- while read line
- do
- col_id=$(echo $line | cut -f 1 -d"%" | cut -f 1 -d "&" | cut -f 2 -d"=")
- col_url=$(echo $line | cut -f 1 -d"%")
- col_name=$(echo $line | cut -f 2 -d"%")
- col_category=$(echo $line | cut -f 3 -d "%")
- col_rating=$(echo $line | cut -f 4 -d"%")
- col_ratingcount=$(echo $line | cut -f 5 -d "%")
- col_download=$(echo $line | cut -f 6 -d"%")
- col_price=$(echo $line | cut -f 7 -d"%")
- col_publishdate=$(echo $line | cut -f 8 -d"%")
- col_version=$(echo $line | cut -f 9 -d"%")
- col_filesize=$(echo $line | cut -f 10 -d"%")
- col_requireandroid=$(echo $line | cut -f 11 -d "%")
- col_contentrating=$(echo $line | cut -f 12 -d"%")
- sql_insert='insert into '$TABLENAME' values('"\"$col_id\", \"$col_url\", $col_top, \"$col_name\", \"$col_category\", \"$col_rating\", \"$col_ratingcount\", \"$col_download\", \"$col_price\", \"$col_publishdate\", \"$col_version\", \"$col_filesize\", \"$col_requireandroid\", \"$col_contentrating\", \"$col_country\", \"$col_dtime\""');'
- echo $sql_insert >>$file_output
- mysql -h $HOST -P $PORT -u$USER -p$PWD -e "use $DBNAME; $sql_insert"
- col_top=`expr $col_top + 1`
- done < $file_input
- }
通过while read line循环,读取模块5提取的游戏属性信息文本文件,分割每行得到相应的字段(cut -f 2 -d "%"),赋值到插入语句中(sql_insert)
7、生成HTML报表
shell通过拼接字符串table + tr + td + info的形式,生成html网页报表,请详见我先前写的博客:shell 实现txt转换成html
8、邮件发送报表
邮件发送模块,主要采取/usr/bin/mutt方式,邮件正文显示一张html报表(默认是美国),其它国家以附件形式发送,请详见我先前写的博客:linux shell 发送email 附件
邮件定时发送,采用了crontab命令,具体配置和使用方法,请详见我先前写的博客:linux定时运行命令脚本——crontab
9、网页查询报表
通过JSP提取保存在MySQL的游戏属性信息,循环遍历生成游戏排名的网页信息,请参考我先前写的博客:Linux JSP连接MySQL数据库
10、排名趋势图
趋势图,采用了第三方的JFreeChart图表生成工具,请详见我先前的写的博客:JFreeChart学习示例
生成游戏排名趋势图后,需要嵌套到JSP网页中进行显示,完整的排名趋势图,请详见我先前写的博客:JFreeChart项目实例
自动化总控脚本
12国游戏排名系统,从免费ip代理筛选——》网页抓取——》数据库保存——》生成排名报表——》定时发送邮件报表——》游戏排名查询——》趋势图生成
全部都实现了总流程的自动化,下面是各个模块的脚本实现和功能说明:

通过配置服务器的crontab定时运行进程命令,在每天凌晨00:01:00时刻(凌晨零时1分零秒),将会自动启动总控脚本top10_all.sh
每日生成的日报,都是通过总控脚本自动生成一个当天的文件夹,来保存当天的抓取数据、分析数据、结果数据,如下图所示:

注:以上文件夹数据是拷贝的去年测试数据,在我自己的笔记本上没有抓取排名
因为通过远程代理抓取12国排名的前TOP800,是比较耗费网络资源、内存资源和时间,严重影响我上网体验 ~~~~(>_<)~~~~
架构设计与评析
抓取游戏排名系统,设计之初并没有想的这么复杂,当时只用了一周时间搭建了抓取国内google play游戏排名(使用curl抓取国内排名,不需用代理的)
后来,根据提出的各种需求,不断添加、重构、完善的,有点像快速原型的开发流程吧~~ @_@
整套系统,从需求到demo原型,再到邮件发送、网页查看、趋势图查询、免费ip代理设计与实现,前前后后大约花了近两个月(期间还负责开发两款游戏。。。好忙滴~)
总体而言,我当时设计时主要遵循了两个原则:
1、网页抓取、文本处理、数据库保存等数据源信息,全部统一使用脚本实现,开发语言保持纯洁性
2、各个功能模块,划分为子问题独立实现,流程之间采用分层设计,用胶水语言搭积木的组合起来
后来实践证明,这种设计方法和原则,是完全正确的
因为开始给的需求只是抓取10国游戏排名,欧洲和印度两国是后加的,记得当时抓取、测试、发布这两个新增的国家,大约只花了一个晚上两三个小时就搞定!
基于上述的架构设计,新添加一个国家,只需要简单几步(以添加印度india为例):
a、去freeproxylists.net 查找对应国家(印度)免费的ip代理,放到免费代理筛选系统(testProxy)相应目录下,简单添加上这个国家信息即可(下一篇博客详细讲解)
b、复制中国的脚本为印度 cp top800_proxy_china.sh top800_proxy_india.sh,并把 top800_proxy_india.sh 中全部的china修改为india,批量修改命令如下:
sed -i "s/china/india/g" top800_proxy_india.sh
c、在12国总控脚本(top800_proxy_all.sh)中,添加上印度的网页抓取脚本 top800_proxy_india.sh,并在邮件附加中,添加上印度的html附件
d、在数据库脚本(sql_insert_x_country.sh)中,添加上印度的抓取网页文件夹,保存印度的游戏信息到mysql;在JSP网页和查询选项中,都添加上印度一项即可
e、ok,添加完毕!
总体评析这套系统架构
优点:
1、功能模块相对独立,便于功能扩充和维护
2、开发语言全采用shell+awk,模块流程之间便于调用和组合
3、添加新的国家排名,仅仅修改几处配置即可,不需要了解模块内部实现过程
4、趋势图工具JFreeChart也是Java实现,便于JSP调用和嵌套,清晰的显示游戏排名趋势
5、异地备份mysql数据库,在自动化总控脚本中采用了每天异地备份(scp),降低了历史数据丢失的概率(异地备份需建立两机的信任关系,详见我先前的博客)
需要进一步完善:
1、抓取生成的12国游戏排名报表,包含了近10种各国语言,有中文、英语、日语、俄语、西班牙语、韩语、法语、德语、意大利语。。。貌似八国联军。。。哈
后期可以考虑调用google的translate翻译API接口,把报表的10种语言全部翻译成中文或英文,方便查看,不用再去手动一个一个游戏查词典了。。。
2、目前搭在一台服务器上,同时在后台运行多个网页抓取脚本(./xxx.sh &),12国TOP800排名,抓取下载的数据量比较大时间较长,后期改进为多台服务器同时抓取
3、这套系统,虽然实现了全流程控制,我也写了对应模块的功能说明文档(readme),但后期他人维护仍然时有问题,毕竟学习脚本会有时间、精力成本,而且脚本语言不够直观,命令参数语法简洁的同时也有点苦涩,不是那么好懂理解,后期看用什么好的图形界面(GUI)封装起来,方便维护
4、现在android开发竞争很激烈,掌握游戏排名特别是游戏发展趋势非常重要,后期看能不能把这套系统封装起来,做成一个商业应用软件 $^_^$
总结
这整套系统,全部是由我自己独立设计、实现、测试、上线、维护、完成。
回头看一看,这套系统涉及到的知识点和技术比较多,有好多我从前都没接触过,如awk、JSP、Tomcat、mutt、crontab、JFreeChart
但正是有这样的机遇和挑战,才更能考研一个人独立思考、分析问题和解决问题的能力,特别是快速再学习的能力
下面谈谈我在设计和实现这套系统过程中,所遇到的困难、走过的弯路,以及解决问题的经验心得体会:
遇到的困难
1、不清楚该选择哪套实施方案
抓取网页排名,开始不知道应该选择应用程序实现,还是脚本实现,因为创业团队非常注重效率和成本,而且要求尽快看到原型和效果,显然脚本开发较快
2、抓取网页后的内容提取
内容提取,到底是使用xml解析整套html文件,还是有其它更好的替代方案。曾做过xml解析,开始我就选了xml方式分析提取,后来发现我错了,因为某些html非标准结构
3、linux下的邮件发送和定时运行进程,该怎么实现呢?
请教技术高手,得到了肯定答复:linux某些命令肯定是可以实现,于是自己去网上查找、验证,发现有成熟的方案(网上有些解决方法行不通,当时综合了好几种方法)
4、生成游戏趋势的图表,是采用第三方开源引擎呢?还是直接使用Java自带的图形工具绘制?
从开发效率角度讲,肯定首选开源或免费的第三方图形工具,当时通过查资料调研发现:JChart和JFreeChart都可以实现,且都是用Java编写开发
经验心得体会
1、知识面要非常广
系统采用了多种不同的工具,如shell脚本、代理服务器、MySQL数据库、HTML网页、mutt邮件发送、JSP网站及搭建、JFreeChart调研(详见我的百度博客)
既有前端开发(HTML、JSP),又有后台服务(Tomcat网站搭建、数据库连接),还有脚本语言(shell、awk)、图形工具(JFreeChart),像开杂货店铺,存货要多
2、快速再学习能力
当年在百度学了一些shell脚本,但是设计开发全shell实现的排名系统,显然还需要加强学习和积累,在项目实现的过程中我是需要什么技术就立刻去学什么技术
大学和研一,都做过网站开发,熟悉一些html/css、asp.net,去百度头一个月也跟着师傅学了几招js,于是拼接table、html不在话下,学习jsp也很轻松,毕竟有一些内功
mysql数据库秘籍,都修炼了四五年,就不用说了,很简单;搭建tomcat,在网上搜索了一篇教程,三加五除二就搞定,原理跟IIS和Apache都差不多,解析网页的服务端
JChart和JFreeChart都是Java图形生成工具,但需从费用、易学习、文档示例、通用性等多个角度综合考量,最终选择了JFreeChart图形方案
3、虚心多学多积累
遇到技术方案选择和知识盲区时,需要多去查阅资料,调研已有成熟的技术解决方案,拿来自己用;如果找不到,虚心多向技术大牛请教,大牛们一般都会很热心点拨你
然后根据大牛们提示的思路,自己去寻找解决问题的途径;问题解决后,需要多思考多总结,为什么自己当时想不到呢。。。然后积累下来,久而久之,经验沉淀就多了
- Linux 抓取网页实例(shell+awk)
- Linux 抓取网页实例(shell+awk)
- Linux 抓取网页实例(shell+awk)
- Linux 抓取网页实例(shell+awk)
- Linux 抓取网页实例(shell+awk)
- Linux 抓取网页实例(shell+awk)
- Linux 抓取网页实例(shell+awk)
- linux-网页抓取(2)
- curl+awk抓取并分析网页
- linux shell用法(5)-- awk命令
- Linux学习---shell编程(08-awk)
- Linux Shell脚本(正则/Sed/AWK)
- linux shell awk 命令
- linux shell awk用法
- Linux Shell 命令--awk
- linux shell awk 语法
- linux shell awk 语法
- linux shell awk 语法
- android学习 豆瓣 整体架构
- 解决java网络编程IPv6问题
- running step of Make
- 日期转换(西历转和历)
- Android 中的 Menu
- Linux 抓取网页实例(shell+awk)
- 10054 - The Necklace
- ORACLE存储过程基础
- 兄弟郊游问题
- ORACLE笔记
- Linux 抓取网页方式(curl+wget)
- 软件工程的总结
- bitmap解析
- SQL拾遗


