Hadoop性能分析工具Hitune的安装(centos)
来源:互联网 发布:成都软件开发 编辑:程序博客网 时间:2024/06/08 03:04
转自:http://blog.csdn.net/jostey/article/details/7078797
简介:
Hitune是建立在chukwa之上的对于hadoop的分析软件,不过hitune的呈现方式是通过excel来展示的,感觉上他对于hadoop的分析更为透彻和具体,下面给几个它分析得到的图片:
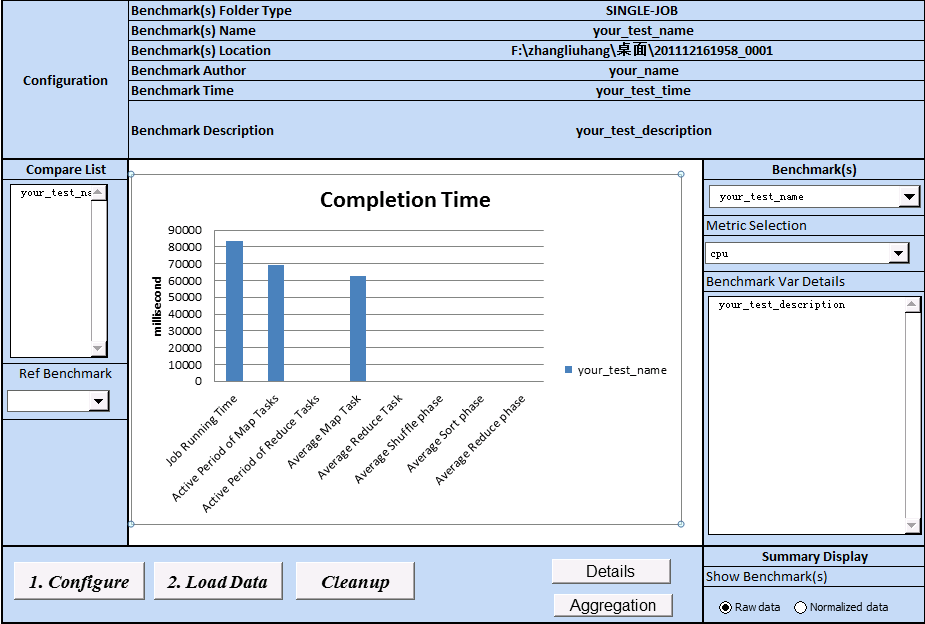
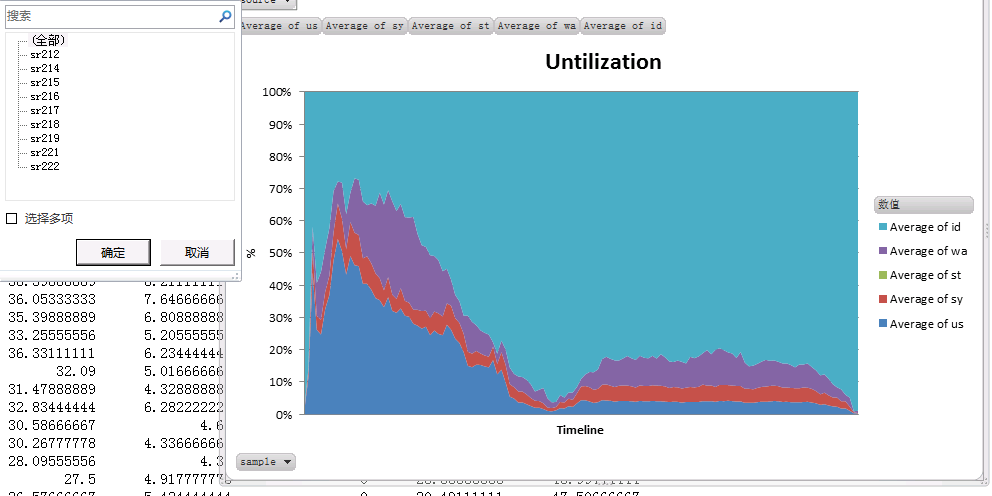
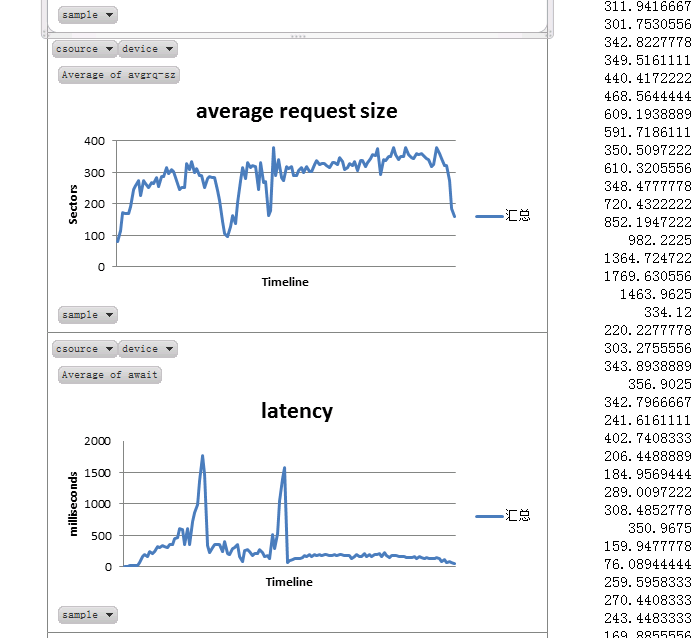
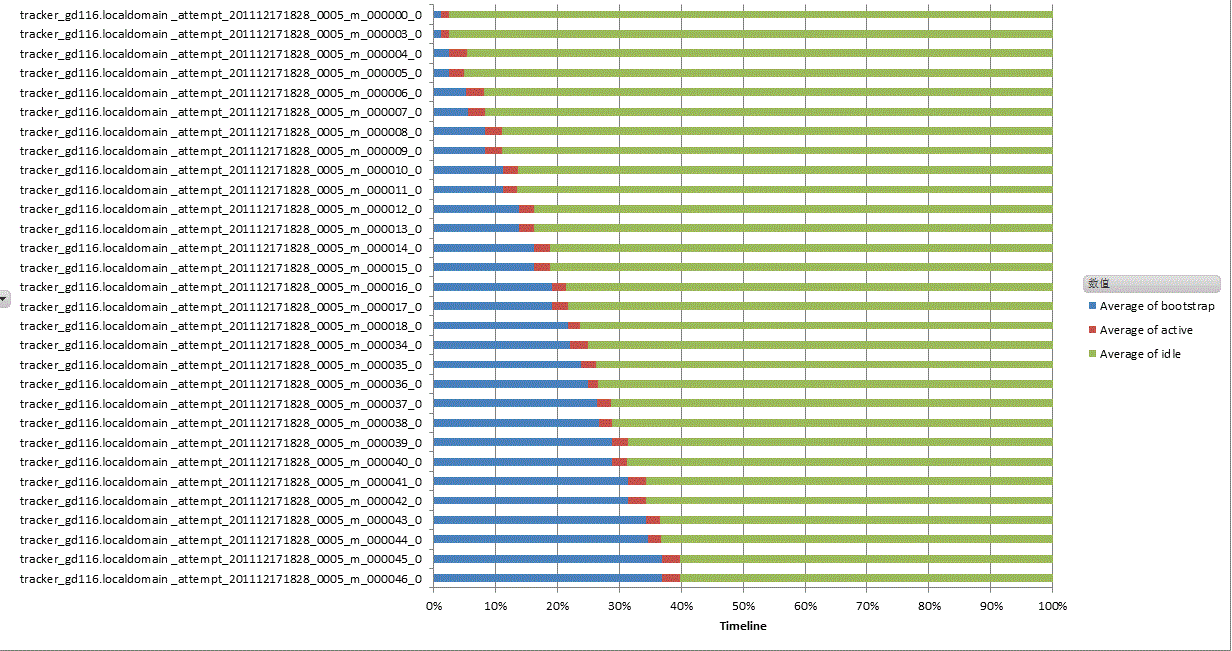
安装流程:
1.装备好hadoop,确保hadoop是正确的
我使用了三个节点,ip分别是10.10.104.115,10.10.104.116,10.10.104.116,其中10.10.104.115作为namenode,他们的映射名称为gd115,gd116,gd117
2.到官网上https://github.com/HiTune/HiTune将hitune下载下来,并且解压到各个节点上面
3.利用NTP调节时钟同步(centos系统)
参考文档http://blog.sina.com.cn/s/blog_5369bee10100aysx.html
(1)安装ntp:安装包可以到官网上下载
http://www.ntp.org/downloads.html
(2)在集群中选择一台作为的时间服务器节点,让其他节点的时间于该时间服务器同步,我用的是10.10.104.115,首先配置该节点设置:
sudo chmod +w /etc/ntp.conf
sudo vi /etc/ntp.conf
(添加一行:
restrict 10.10.104.0 mask 255.255.255.0 nomodify notrap
)
sudo chmod –w /etc/ntp.conf
然后开启服务:
sudo service ntpd start
sudo chkconfig ntpd on
此时可以检测一下其状态:
ntpstat
(3)配置其他节点同步于该节点:
sudo ntpdate 10.10.104.115
上述指令只进行一次同步,为了每分钟同步一次,可以如下操作:
sudo chmod +w /etc/crontab
sudo vi /etc/crontab
(添加一行:
* * * * * root ntpdate 10.10.104.115 && hwclock -w
)
sudo –w /etc/crontab
sudo /etc/rc.d/init.d/crond restart
4.安装 sysstat,版本为:version 9.0.x,因为hitune并不支持7.0.x版本
(1)到官网上http://sebastien.godard.pagesperso-orange.fr/download.html
下载,我下的版本是v9.0.6
(2)安装:
./configure
sudo make
sudo make install
5.关闭hadoop jvm reuse
配置hadoop的mapred-site.xml
<property>
<name>mapred.job.reuse.jvm.num.tasks</name>
<value>1</value>
</property>
6. enable Java instrumentation
配置hadoop的mapred-site.xml
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx200m -javaagent:/home/zhangliuhang/hitune/chukwa-hitune-dist/hitune/HiTuneInstrumentAgent-0.9.jar=traceoutput=/home/zhangliuhang/hitune/chukwa-hitune-dist/hitune_output,taskid=@taskid@
</value>
</property>
6.安装Hitune
(1)运行./configure,执行过程如下所示:
[zhangliuhang@gd115 hitune]$ ./configure
The role of the cluster - either "hadoop" or "chukwa"[chukwa]:chukwa
The folder to install HiTune[/home/zhangliuhang]:/home/zhangliuhang/hitune
The list of nodes in the Hadoop cluster - multiple nodes can be separated with comma, and can also be specified as hostname1-100 or 192.168.0.1-100[localhost]:gd115-117
The list of collector nodes in the Chukwa cluster - multiple nodes can be separated with comma, and can also be specified as hostname1-100 pattern or 192.168.0.1-100[localhost]:10.10.104.116
The HDFS URI of the Chukwa cluster[hdfs://127.0.0.1:9000]:hdfs://gd115:9989
Java home[/usr]:/usr/java/jdk1.7.0_01
Java platform[Linux-i386-32]:Linux-amd64-64
Hadoop home[/usr/lib/hadoop]:/home/zhangliuhang/hadoop
Hadoop configuration folder[/home/zhangliuhang/hadoop/conf]:
Hadoop core jar file[]:/home/zhangliuhang/hadoop/hadoop-0.20.2-core.jar
Chukwa's log dir - it is strongly recommended to put the Chukwa log folder under the hadoop_log_dir [/var/log/hadoop/chukwa]:/home/zhangliuhang/hadoop/logs
Hadoop history log folder - it is usually under /history/done[/var/log/hadoop/history/done]:/home/zhangliuhang/hadoop/logs/history
(注)此时在hitune的安装目录下会生成一个名为chukwa-cluster.conf的文件,该文件中就包含了前面所配置的内容,其实可以在里面自行更改
(2)将文件chukwa-cluster.conf传送到各个节点上,然后执行
./configure –f chukwa-cluster.conf
(3)在各个节点上执行
./install -f chukwa-cluster.conf –r chukwa
(注,安装好后,会在安装目录得到一个chukwa-hitune-dist/目录,我将$CHUKWA_HOME=安装目录/chukwa-hitune-dist/假如按照上面的配置,那么应该是$CHUKWA_HOME=/home/zhangliuhang/hitune/chukwa-hitune-dist/)
(4)在$CHUKWA_HOME目录下手动新建一个hitune_output目录,因为hitune似乎自己不会新建这个目录
(5)将$CHUKWA_HOME/chukwa-hadoop-0.4.0-client.jar拷贝到$HADOOP/lib/,
将$CHUKWA_HOME/chukwa-agent-0.4.0.jar拷贝到$HADOOP/lib/,
将$CHUKWA_HOME/tools-0.4.0.jar拷贝到$HADOOP/lib
(6)将$CHUKWA_HOME/conf/hadoop_log4j.properties 覆盖掉$HADOOP_HOME/conf/log4j.properties
将$CHUKWA_HOME/conf/hadoop_metries.properties覆盖掉$HADOOP_HOME/conf/hadoop_metries.properties
(注:装好后,如果用的不是root用户,最好改动几个地方,使得他们不要把数据写到/tmp目录下,因为可能没有权限,改动的地方有:
1.$HADOOP_HOME/conf/core-site.xml中的tmp目录属性
2.$HADOOP_HOME/conf/hadoop-env.sh中的pid目录
3.$CHUKWA_HOME/conf/chukwa_env.sh中的pid目录)
8.使用hitune
(1)启动hadoop,启动collectors,再启动agents和processor
(2)提交一个job给hadoop执行,此时记住运行该job时的代号:
例如:
[zhangliuhang@gd115 testbench]$ bash sort.sh
Running on 2 nodes to sort from hdfs://gd115:9989/user/zhangliuhang/randomdata into hdfs://gd115:9989/user/zhangliuhang/sortdata with 3 reduces.
Job started: Fri Dec 16 20:30:32 CST 2011
11/12/16 20:30:33 INFO mapred.FileInputFormat: Total input paths to process : 2
11/12/16 20:30:33 INFO mapred.JobClient: Running job: job_201112161958_0014
那么代号就是201112161958_0014
(3)当job结束的时候可以选择关闭各个节点上的agents
(4)执行脚本,对之前run的job各种性能进行分析
$INSTALL_DIR/chukwa-hitune-dist/hitune/bin/HiTuneAnalysis.sh -id 201112161958_0014
其中$INSTALL_DIR对应于6.(1)步进行配置时的安装hitune路径
(5)执行上述脚本后,默认会在hdfs的目录:/chukwa/report下生成对应的文件,以job id号命名,(例如/chukwa/report/201112161958_0014)我们需将该目录下载到本地(带有windows的操作系统,并且装有excel),事先最好将$INSTALL_DIR/chukwa-hitune-dist/hitune/visualreport/目录也下载到本地。
(6)将本地visualreport/TYPE文件拷贝到本地201112161958_0014目录中,然后运行本地visualreport/ AnalysisReport.xlsm,接着按照打开的内容就可以进行分析了,这个打开后是图形化界面,操作很方便,就不多说了。
- Hadoop性能分析工具Hitune的安装(centos)
- Hadoop性能分析工具Hitune的安装(centos)
- Hadoop性能分析工具Hitune的安装(centos)
- 关于mapreduce性能profile工具Hitune的over head
- 用Hitune+chukwa 进行mapreduce 程序的性能调优
- CentOS hadoop 的安装
- php性能分析工具工具xhprof的安装与使用
- hadoop性能分析工具vaidya学习
- php轻量级的性能分析工具xhprof的安装使用
- centos下hadoop的安装
- 安装网页性能分析工具yslow中遇到的问题
- 性能分析工具的使用
- TraceView性能分析的工具
- oracle 性能分析工具statpack安装使用
- hadoop中使用hprof工具进行性能分析
- 在64位的CentOS 6.8上安装系统性能监测工具Monitorix
- CentOS性能监控工具
- CentOS性能监控工具
- 线上服务经常性死机问题分析总结
- 关于EDM邮件涉及的MX记录、A记录和反向解析
- biancheng
- preview
- 使用guava读取ANSI类型的文件,避免中文乱码
- Hadoop性能分析工具Hitune的安装(centos)
- windows XP查看系统信息
- CABasicAnimation animationWithKeyPath 一些规定的值(Layer层动画)
- Objective C内存管理——如何理解autorelease
- C++ Internals: VC RTTI - 基本数据结构
- JavaScript中的try...catch和异常处理
- div限制字数
- hp-ux下磁盘配额攻略
- java 从jar中读取文件 三种方法<Enumeration>


