[Index]Index Scan
来源:互联网 发布:lte无线网络优化实践 编辑:程序博客网 时间:2024/04/30 09:41
Index B-Tree
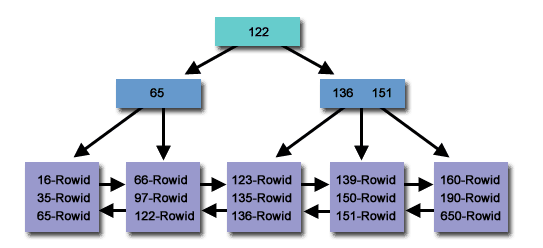
Index的叶节点指向RowID,然后根据RowID再找对应的Block
语法:CREATE INDEX NAME_SALARY_IDX ON PERSON(LAST_NAME ASC,SALARY DESC);
Index Unique Scan
对于unique index来说,如果where条件后面是=,那么就会执行index unique scan。
AskTom:well, the optimizer can look at an index that is unique and say "ah-hah, if you use "where x =:x and y = :y and ...." I'm going to get ONE row back, I can cost that much better" (refer)
Index Unique Scan的条件:
1.Index是唯一性索引;
2.where条件类似于 x = :x and y=: y ...;
Example:
CREATE TABLE PT_TEST AS SELECT * FROM DBA_OBJECTS;CREATE UNIQUE INDEX UNIQUE_IDX ON PT_TEST(OBJECT_ID); --UNIQUE_IDX是唯一索引EXEC DBMS_STATS.GATHER_TABLE_STATS('APPS','PT_TEST', CASCADE=>TRUE ); --重做统计SQL> set auto traceSQL> select * from pt_test where object_id=10;Elapsed: 00:00:00.47Execution Plan----------------------------------------------------------Plan hash value: 2398730171------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 97 | 3 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID| PT_TEST | 1 | 97 | 3 (0)| 00:00:01 ||* 2 | INDEX UNIQUE SCAN | UNIQUE_IDX | 1 | | 2 (0)| 00:00:01 |------------------------------------------------------------------------------------------Predicate Information (identified by operation id):--------------------------------------------------- 2 - access("OBJECT_ID"=10)Statistics---------------------------------------------------------- 0 recursive calls 0 db block gets 4 consistent gets 0 physical reads 0 redo size 1194 bytes sent via SQL*Net to client 338 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processedSQL>Performance:index unique scan的性能非常好。
Index Range Scan
Case 1
基于上面的case,还是以object_id这个唯一性索引列为条件
SQL> select owner from pt_test where object_id<10;8 rows selected.Elapsed: 00:00:00.45Execution Plan----------------------------------------------------------Plan hash value: 1470047708------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1 | 11 | 4 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID| PT_TEST | 1 | 11 | 4 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN | UNIQUE_IDX | 1 | | 3 (0)| 00:00:01 |------------------------------------------------------------------------------------------Predicate Information (identified by operation id):--------------------------------------------------- 2 - access("OBJECT_ID"<10)Statistics---------------------------------------------------------- 1 recursive calls 0 db block gets 6 consistent gets 0 physical reads 0 redo size 388 bytes sent via SQL*Net to client 338 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 8 rows processedSQL>对于上边这个例子,Index Unique Scan和Index Range Scan在B Tree上的搜索路径是一样的,只是Index Unique Scan在找到应该含有要找的Index Key的block后便停止了搜索,因为该键是唯一的。而Index Range Scan还要循着指针继续找下去直到条件不满足时。Case 2
这个时候给owner字段增加一个非唯一性索引
create index ind_owner on pt_test(owner); --给owner字段增加非唯一性索引
SQL> select owner from pt_test where owner='SCOTT';123 rows selected.Elapsed: 00:00:00.80Execution Plan----------------------------------------------------------Plan hash value: 2280863269------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 1472 | 7360 | 6 (0)| 00:00:01 ||* 1 | INDEX RANGE SCAN| IND_OWNER | 1472 | 7360 | 6 (0)| 00:00:01 |------------------------------------------------------------------------------Predicate Information (identified by operation id):--------------------------------------------------- 1 - access("OWNER"='SCOTT')Statistics---------------------------------------------------------- 0 recursive calls 0 db block gets 13 consistent gets 0 physical reads 0 redo size 1653 bytes sent via SQL*Net to client 426 bytes received via SQL*Net from client 10 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 123 rows processedSQL>对于none unique index来说,如果where 条件后面出现了=,>,<,betweed...and...的时候(返回多行值的时候),就有可能执行index range scan。
Performance:It depends ..How selective ? Throw-away later ? single block IO, CF
The problem is that it is impossible to tell how many rows the range scan is scanning. A range scan that scans 5 rows on average will probably be fairly efficient. However a range scan scanning 10000 rows on average will probably be causing grief.
INDEX SKIP SCAN
Reference:http://blog.csdn.net/robinson1988/article/details/4980611
http://www.orafaq.com/tuningguide/range%20scan.html
Oracle Index Access Methods
- [Index]Index Scan
- Index Seek和Index Scan
- index seek与index scan
- index seek与index scan
- index seek与index scan .
- index range scan,index fast full scan,index skip scan
- index unique scan vs index full scan
- Table Scan, Index Scan, Index Seek
- Table Scan, Index Scan, Index Seek
- INDEX SKIP SCAN和INDEX FULL SCAN
- PostgreSQL index scan,bitmap index scan区别
- Table Scan, Index Scan, Index Seek
- INDEX SKIP SCAN 和 INDEX RANGE SCAN
- Index scan for like %%
- 什么是INDEX SKIP SCAN
- 理解index skip scan
- 关于INDEX SKIP SCAN
- index unique scan
- ubuntu 设置软件源
- 一款219字节的JavaScript小游戏:《219 bytes tron》
- 开发中会遇到的一些系统瓶颈
- 理解关于java反射中类的域及修饰符
- Modifying sequence operations:
- [Index]Index Scan
- Android裡使用的dpi 跟 pixel 的轉換
- C#中在文本框TextBox中嵌入日历控件
- Android中Intent对应的category列表大全
- 安装交叉编译工具,执行arm-linux-gcc –v命令出现提示找不到该文件或目录?解决方法
- 函数调用输出一个一维数组中的最大值、最小值、全部元素的和,并将此数组中的值按逆序重新存放。
- 五种I/O 模式——阻塞(默认IO模式),非阻塞(常用语管道),I/O多路复用(IO多路复用的应用场景),信号I/O,异步I/O
- C++ 中string.find() 函数的用法总结
- 个人的命运决定于晚上8点到10点之间(认真看完本篇文章,你的生活将会有很大改变)


