hash数据库概述
来源:互联网 发布:巨库微信群发软件 编辑:程序博客网 时间:2024/05/16 14:05
tokyocabinet1.4.19阅读笔记(一)hash数据库概述
开始正式的研究key-value形式的持久化存储方案了,第一个阅读的项目是tokyo cabinet,版本号是1.4.19.
tokyo cabinet支持几种数据库形式,包括hash数据库,B+树数据库,fix-length数据库,table数据库。目前我仅看了第一种hash数据库的实现。之所以选择这个,是因为第一这种类型的数据库似乎是TC中使用的最多的一种,其次它的算法比之B+树又更简单一些而效率上的表现也丝毫不差。
看看TC中代码的组织。关于上面几个分类的数据库实现,实际上在TC项目的代码组织中各自以单个文件的形式出现,比如hash数据库的代码全都集中在 tchdb.c/h中,也只不过4000多行罢了。除去这几种数据库的实现文件,其余的代码文件功能可以大体上分为两类,一类是辅助性质的代码,给项目中各个部分使用上的,另一部分就是单独的管理数据库的CLI程序的代码,比如tchmgr.c/h就是用于管理HASH数据库的CLI程序的代码。之所以要交代一下项目中代码的组织,无非是为了说明,其实如果将问题集中在HASH数据库或者其他形式的数据库实现上,起码在TC中,所要关注的代码是不多的。
首先来看数据库文件是如何组织的。
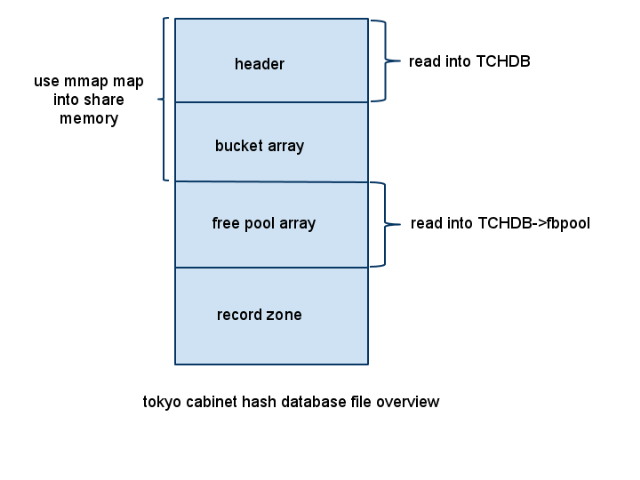
从图中可以看到,hash数据库文件大致分为四个部分:数据库文件头,bucket 数组,free pool数组,最后的是真正存放record的部分。下面对这几部分做一个说明。
1)数据库文件头
数据库文件头部分存放的是关于该数据库的一些总体信息,包括这些内容:
nameoffsetlengthfeaturemagic number032identification of the database. Begins with "ToKyO CaBiNeT"database type321hash (0x01) / B+ tree (0x02) / fixed-length (0x03) / table (0x04)additional flags331logical union of open (1<<0) and fatal (1<<1)alignment power341the alignment size, by power of 2free block pool power351the number of elements in the free block pool, by power of 2options361logical union of large (1<<0), Deflate (1<<1), BZIP2 (1<<2), TCBS (1<<3), extra codec (1<<4)bucket number408the number of elements of the bucket arrayrecord number488the number of records in the databasefile size568the file size of the databasefirst record648the offset of the first recordopaque region128128users can use this region arbitrarily
需要说明的是,上面这个表格来自tokyocabinet的官方文档说明,在这里。同时,数据库文件中需要存放数据的地方,使用的都是小端方式存放的,以下就不再就这点做说明了。从上面的表格可以看出,数据库文件头的尺寸为256 bytes。
在操作hash数据库的所有API中,都会用到一个对象类型为TCHDB的指针,该结构体中存放的信息就包括了所有数据库文件头的内容,所以每次在打开或者创建一个hash数据库的时候,都会将数据库文件头信息读入到这个指针中(函数tchdbloadmeta)。
2)bucket 数组
bucket array中的每个元素都是一个整数,按照使用的是32位还是64位系统,存放的也就是32位或者64位的整数。这个数组存放的这个整数值,就是每次对 key 进行hash之后得到的hash值所对应的第一个元素在数据库文件中的偏移量。
3)free pool数组
free pool数组中的每个元素定义结构体如下:
typedef struct { // type of structure for a free block
uint64_t off; // offset of the block
uint32_t rsiz; // size of the block
} HDBFB;
很明显,仅有两个成员,一个存放的是在数据库文件中的偏移量,一个则是该free block的尺寸。free pool数组用于保存那些被删除的记录信息,以便于回收利用这些数据区,后续会针对free pool相关的操作,API做一个详细的分析。
4)record数据区
每个record数据区的结构如下表:
nameoffsetlengthfeaturemagic number01identification of record block. always 0xC8hash value11the hash value to decide the path of the hash chainleft chain24the alignment quotient of the destination of the left chainright chain64the alignment quotient of the destination of the right chainpadding size102the size of the paddingkey size12varythe size of the keyvalue sizevaryvarythe size of the valuekeyvaryvarythe data of the keyvaluevaryvarythe data of the valuepaddingvaryvaryuseless data
当然,上面这个结构只是该record被使用时的结构图,当某一项record被删除时,它的结构就变为:
nameoffsetlengthfeaturemagic number01identification of record block. always 0xB0block size14size of the block
对比两种情况,首先是最开始的magic number是不同的,当magic number是0XB0也就是该record是已经被删除的free record时,那么紧跟着的4个字节存放的就是这个free record的尺寸,而record后面的部分可以忽略不计了。
分析完了hash数据库文件的几个组成部分,从最开始的数据库文件示意图中还看到,从文件头到bucket array这一部分将通过mmap映射到系统的共享内存中,当然,可以映射的内容可能不止到这里,但是,数据库文件头+bucket array这两部分是一定要映射到共享内存中的,也就是说,hash数据库中映射到共享内存中的内容上限没有限制,但是下限是文件头+bucket array部分。
同时,free pool也会通过malloc分配一个堆上的内存,存放到TCHDB的fbpool指针中。
这几部分(除了record zone),通过不同的方式都分别的读取到内存中,目的就是为了加快查找的速度,后面会详细的进行说明。
uint64_t off; // offset of the block
uint32_t rsiz; // size of the block
} HDBFB;
tokyocabinet1.4.19阅读笔记(二)hash数据库查找key流程
这一节关注TC中的hash数据库如何根据一个key查找到该key所在的record,因为后续的删除,插入记录都是以查找为基础的,所以首先描述这部分内容.
从上一节的概述中,可以看到record结构体中有两个成员left,right:
typedef struct { // type of structure for a record
uint64_t off; // offset of the record
uint32_t rsiz; // size of the whole record
uint8_t magic; // magic number
uint8_t hash; // second hash value
uint64_t left; // offset of the left child record
uint64_t right; // offset of the right child record
uint32_t ksiz; // size of the key
uint32_t vsiz; // size of the value
uint16_t psiz; // size of the padding
const char *kbuf; // pointer to the key
const char *vbuf; // pointer to the value
uint64_t boff; // offset of the body
char *bbuf; // buffer of the body
} TCHREC;说明,每个record是存放在一个类二叉树的结构中的.
实际上,TC会首先根据一个record的key去算出该key所在的bucket index以及hash index,代码如下:
/* Get the bucket index of a record.
`hdb' specifies the hash database object.
`kbuf' specifies the pointer to the region of the key.
`ksiz' specifies the size of the region of the key.
`hp' specifies the pointer to the variable into which the second hash value is assigned.
The return value is the bucket index. */
static uint64_t tchdbbidx(TCHDB *hdb, const char *kbuf, int ksiz, uint8_t *hp){
assert(hdb && kbuf && ksiz >= 0 && hp);
uint64_t idx = 19780211;
uint32_t hash = 751;
const char *rp = kbuf + ksiz;
while(ksiz--){
idx = idx * 37 + *(uint8_t *)kbuf++;
hash = (hash * 31) ^ *(uint8_t *)--rp;
}
*hp = hash;
return idx % hdb->bnum;
}需要特别提醒的一点是,上面的算法中,根据key算出所在的bucket index,是经过模TCHDB->bnum之后的结果,也就是说,这个值是有限制的---最大不能超过TCHDB初始化时得到的bucket最大数量;而算出的二级hash值,我是没有看出来有数值上的限制的,为什么?看了后面的内容就明白了.
因此,所有根据记录的key算出bucket index相同的记录全都以二叉树的形式组织起来,而每个bucket array元素存放的整型值就是该bucket树根所在记录的offset.
到此,相关的结构体联系都清楚了,下面的流程图给出了查找一个key的记录是否存在的流程:
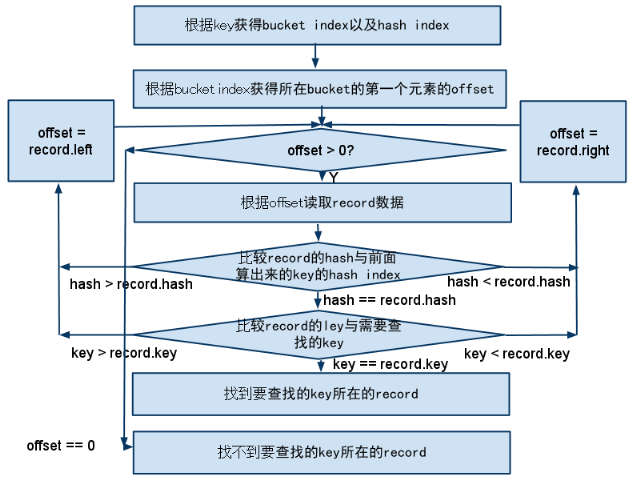
简单的解释一下,这个查找的流程就是首先根据查找的key算出所在的bucket,然后在这个bucket的二叉树中按照条件遍历的过程.
前面提到过,bucket array是整个被mmap映射到共享内存中去的.我们来做一个估计,假设存放bucket array的内存使用了1G,而真正存放record的文件长度有16G,也就是,bucket array的元素与记录大概是1:16的关系,假设所选的hash算法足够的好,以至于每个记录的key可以较为平均的分布在不同的bucket index上,也就是每个bucket array的元素组成的二叉树上平均有16个元素,那么也就最多需要O(4)次读取文件I/O(每次去读取记录的数据都是一次读磁盘操作) + O(1)次内存读操作(因为需要在bucket array中得到树根元素的offset).
但是等等,上面还有一些细节没有交待清楚.
首先,上面的二叉树不是类似AVL,红黑树这样的平衡二叉查找树,也就是说,很可能在极端的情况下演变成一个链表---树的一边没有元素,另一边有全部的元素.
其次,上面的流程图中还有一点就是每次比较首先比较的是hash值,这个值的奥秘就在于解决上面提到的那个问题.既然只是一个普通的二叉树,无法保证平衡,那么就通过算出这个二级的hash值来保证平衡---当然,前提依然是所选择的hash算法足够的好,可以保证key平均的分布.
前面提到过,非平衡的二叉树只会在极端的情况下才会演变为一个极端不平衡的二叉树--链表,而诸如AVL,红黑树之类的平衡二叉树,算法编码都相对复杂,调试起来也麻烦,出错了要跟进更麻烦,另外还别忘了,这些平衡二叉树之所以能保持平衡,在删除/增加元素时做的让树重新平衡的操作,比如旋转等,都是要涉及到读写树结点的,而这些,目前都是存放在磁盘上的---也就是这是相对较费时的操作,所以问题在于:是不是值得为这一个极端的情况去优化?另外,引入二级hash就是为了部分解决这个极端不平衡问题,它的思路简单也容易实现,但是引入的另外一个问题就是每次查找时根据key去算bucket index的时候,还要耗费时间去算hash index了.
平衡点,还是平衡点.时间还是空间,这是一个问题.
所以,经过对TC的hash数据库查找key流程的分析,最大的感受是:它没有使用复杂的算法与数据结构,而是通过一些巧妙的优化如二级hash的引入,达到了系统效率和编码调试复杂度之间一个较好的平衡.学会"平衡"各种因素,是做项目做事情,都要掌握的一个技能,而这个,只有多经历多想才能慢慢积累了.
好了,简单的回顾整个查找key的关键点:
1) 所有的record是以二叉树的形式组织在同一个bucket上面的.
2) 这个二叉树不是平衡的二叉树
3) 为了解决问题二造成的极端不平衡问题,TC引入了二级hash,以保证这个二叉树尽可能的平衡.
以上,就是TC对记录,bucket的组织情况,以及整个查找算法的流程.可以看到,算法,结构体定义等等都不复杂,但是由于巧妙的构思,既可以使用尽可能简单的算法/数据结构,又能规避可能出现的一些隐患,同时还能保证查找的高效率.
查找是key-value形式存储的核心流程,能够将这个流程优化,对整个系统的性能也有很大的影响.
从上一节的概述中,可以看到record结构体中有两个成员left,right:
typedef struct { // type of structure for a record
uint64_t off; // offset of the record
uint32_t rsiz; // size of the whole record
uint8_t magic; // magic number
uint8_t hash; // second hash value
uint64_t left; // offset of the left child record
uint64_t right; // offset of the right child record
uint32_t ksiz; // size of the key
uint32_t vsiz; // size of the value
uint16_t psiz; // size of the padding
const char *kbuf; // pointer to the key
const char *vbuf; // pointer to the value
uint64_t boff; // offset of the body
char *bbuf; // buffer of the body
} TCHREC;
说明,每个record是存放在一个类二叉树的结构中的.uint64_t off; // offset of the record
uint32_t rsiz; // size of the whole record
uint8_t magic; // magic number
uint8_t hash; // second hash value
uint64_t left; // offset of the left child record
uint64_t right; // offset of the right child record
uint32_t ksiz; // size of the key
uint32_t vsiz; // size of the value
uint16_t psiz; // size of the padding
const char *kbuf; // pointer to the key
const char *vbuf; // pointer to the value
uint64_t boff; // offset of the body
char *bbuf; // buffer of the body
} TCHREC;
实际上,TC会首先根据一个record的key去算出该key所在的bucket index以及hash index,代码如下:
/* Get the bucket index of a record.
`hdb' specifies the hash database object.
`kbuf' specifies the pointer to the region of the key.
`ksiz' specifies the size of the region of the key.
`hp' specifies the pointer to the variable into which the second hash value is assigned.
The return value is the bucket index. */
static uint64_t tchdbbidx(TCHDB *hdb, const char *kbuf, int ksiz, uint8_t *hp){
assert(hdb && kbuf && ksiz >= 0 && hp);
uint64_t idx = 19780211;
uint32_t hash = 751;
const char *rp = kbuf + ksiz;
while(ksiz--){
idx = idx * 37 + *(uint8_t *)kbuf++;
hash = (hash * 31) ^ *(uint8_t *)--rp;
}
*hp = hash;
return idx % hdb->bnum;
}
需要特别提醒的一点是,上面的算法中,根据key算出所在的bucket index,是经过模TCHDB->bnum之后的结果,也就是说,这个值是有限制的---最大不能超过TCHDB初始化时得到的bucket最大数量;而算出的二级hash值,我是没有看出来有数值上的限制的,为什么?看了后面的内容就明白了.`hdb' specifies the hash database object.
`kbuf' specifies the pointer to the region of the key.
`ksiz' specifies the size of the region of the key.
`hp' specifies the pointer to the variable into which the second hash value is assigned.
The return value is the bucket index. */
static uint64_t tchdbbidx(TCHDB *hdb, const char *kbuf, int ksiz, uint8_t *hp){
assert(hdb && kbuf && ksiz >= 0 && hp);
uint64_t idx = 19780211;
uint32_t hash = 751;
const char *rp = kbuf + ksiz;
while(ksiz--){
idx = idx * 37 + *(uint8_t *)kbuf++;
hash = (hash * 31) ^ *(uint8_t *)--rp;
}
*hp = hash;
return idx % hdb->bnum;
}
因此,所有根据记录的key算出bucket index相同的记录全都以二叉树的形式组织起来,而每个bucket array元素存放的整型值就是该bucket树根所在记录的offset.
到此,相关的结构体联系都清楚了,下面的流程图给出了查找一个key的记录是否存在的流程:
简单的解释一下,这个查找的流程就是首先根据查找的key算出所在的bucket,然后在这个bucket的二叉树中按照条件遍历的过程.
前面提到过,bucket array是整个被mmap映射到共享内存中去的.我们来做一个估计,假设存放bucket array的内存使用了1G,而真正存放record的文件长度有16G,也就是,bucket array的元素与记录大概是1:16的关系,假设所选的hash算法足够的好,以至于每个记录的key可以较为平均的分布在不同的bucket index上,也就是每个bucket array的元素组成的二叉树上平均有16个元素,那么也就最多需要O(4)次读取文件I/O(每次去读取记录的数据都是一次读磁盘操作) + O(1)次内存读操作(因为需要在bucket array中得到树根元素的offset).
但是等等,上面还有一些细节没有交待清楚.
首先,上面的二叉树不是类似AVL,红黑树这样的平衡二叉查找树,也就是说,很可能在极端的情况下演变成一个链表---树的一边没有元素,另一边有全部的元素.
其次,上面的流程图中还有一点就是每次比较首先比较的是hash值,这个值的奥秘就在于解决上面提到的那个问题.既然只是一个普通的二叉树,无法保证平衡,那么就通过算出这个二级的hash值来保证平衡---当然,前提依然是所选择的hash算法足够的好,可以保证key平均的分布.
前面提到过,非平衡的二叉树只会在极端的情况下才会演变为一个极端不平衡的二叉树--链表,而诸如AVL,红黑树之类的平衡二叉树,算法编码都相对复杂,调试起来也麻烦,出错了要跟进更麻烦,另外还别忘了,这些平衡二叉树之所以能保持平衡,在删除/增加元素时做的让树重新平衡的操作,比如旋转等,都是要涉及到读写树结点的,而这些,目前都是存放在磁盘上的---也就是这是相对较费时的操作,所以问题在于:是不是值得为这一个极端的情况去优化?另外,引入二级hash就是为了部分解决这个极端不平衡问题,它的思路简单也容易实现,但是引入的另外一个问题就是每次查找时根据key去算bucket index的时候,还要耗费时间去算hash index了.
平衡点,还是平衡点.时间还是空间,这是一个问题.
所以,经过对TC的hash数据库查找key流程的分析,最大的感受是:它没有使用复杂的算法与数据结构,而是通过一些巧妙的优化如二级hash的引入,达到了系统效率和编码调试复杂度之间一个较好的平衡.学会"平衡"各种因素,是做项目做事情,都要掌握的一个技能,而这个,只有多经历多想才能慢慢积累了.
好了,简单的回顾整个查找key的关键点:
1) 所有的record是以二叉树的形式组织在同一个bucket上面的.
2) 这个二叉树不是平衡的二叉树
3) 为了解决问题二造成的极端不平衡问题,TC引入了二级hash,以保证这个二叉树尽可能的平衡.
以上,就是TC对记录,bucket的组织情况,以及整个查找算法的流程.可以看到,算法,结构体定义等等都不复杂,但是由于巧妙的构思,既可以使用尽可能简单的算法/数据结构,又能规避可能出现的一些隐患,同时还能保证查找的高效率.
查找是key-value形式存储的核心流程,能够将这个流程优化,对整个系统的性能也有很大的影响.
tokyocabinet1.4.19阅读笔记(三)hash数据库删除数据流程
这一节关注根据key定位到数据进行删除的整个流程。
先来看这个过程的流程图,其实很简单,包括以下几个按部就班的步骤:

a) 首先,根据key查找对应的记录,这个在上一节已经完整的介绍过了,当时也提到,查找操作是后续进行删除和插入新数据时的基础。
如果没有找到记录,说明原来就没有,那么就不必继续下去了。
假设现在找到了所要删除的数据,接着以下几步:
b) 将该记录的magic number置为0xb0,第一节讲解hash数据库概述的时候提到过,每条记录的头部信息中有两种不同magic number,根据这个判断一条记录是否被删除了,现在将这个magic number置为0xb0就是表示这条记录已经被删除了。
c) 将这条被删除的记录插入到free pool数组中的合适位置,这是下一节的重点,这里先知道这个操作就好。
d) 上一节提到过,同一个bucket index是以二叉树形式组织在一起的,虽然不是平衡的二叉树,但是删除了一个数据之后会破坏二叉树的性质,所以需要在二叉树中找到合适的记录来替换删除这条记录之后剩下的位置。
熟悉数据结构与算法的都知道,一个排序二叉树如果按照中序遍历的话,那么是有序的。所以要在删除一个记录之后仍然保持排序二叉树的有序性,是删除操作的重点,下面就是TC中删除一个记录时的调整算法:
if rec.left is not null and rec.right is null
child = rec.left
else if rec.left is null and rec.right is not null
child = rec.right
else if rec.left is null and rec.right is null
child = null
else
child = rec.left
right = rec.right
rec.right = child
while (rec.right is not null)
rec = rec.right
rec.right = right
replace rec's original place with child
也可以从下图中来理解当删除一个记录时,它的左右子节点都不为空时的处理:
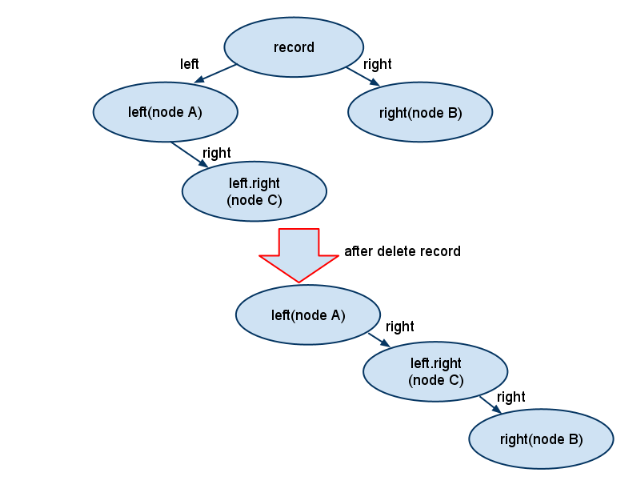
从图中可以看出,当所要删除的节点左右子节点都不为空时,会去寻找左子树中的最右边的子节点,然后将待删除记录的右子树变成这个最右子节点的右子树。
需要注意到的是,经典的数据结构算法中,当在排序二叉树中删除一个节点之后,所做的调整与上面的流程有所不同,虽然也是找到的原记录的左子树的最右节点,但是是将这个最右节点直接替换掉原来记录的位置,也就是如下图:
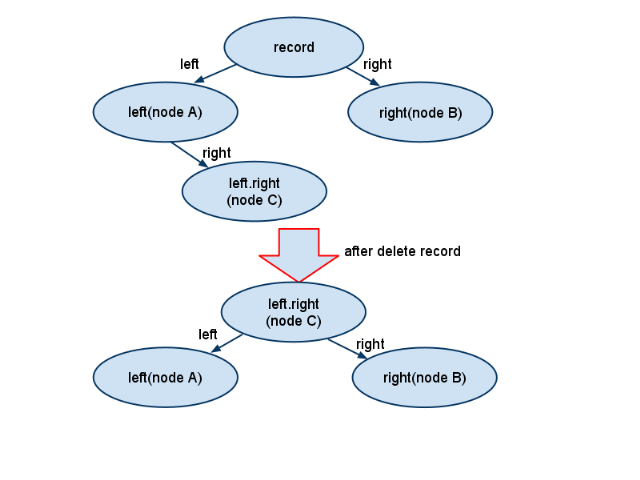
所以,这里出现了一个新的问题,TC中的调整算法是有可能导致删除记录之后二叉树不平衡的,那么为什么不选用第二种方法呢?
我的理解是:
1) 如前一节所述,TC中的二叉树本来就不是必然平衡的,所以TC中的这种调整算法有可能会有“负负得正”的结果。
2)第二种经典的做法中,需要的调整包括:a)将最右子节点从原来的父节点上删除 b)最右子节点要替换原记录的位置,那么要将原记录的左右子树分别赋值变为最右子节点的左右子树。上面的这个调整,每次调整都是需要修改节点的,而每次修改都会有对磁盘的I/O操作。
而第一种做法呢,仅需要一次修改操作-----将原记录的右子树变成最右子节点的右子树即可。
综合这几个因素,TC选择了I/O较少的做法。
我不清楚我的理解是否合理,欢迎补充。
e)删除了记录,也跳整了树的结构之后,最后的工作就是更新数据库文件header的信息---因为当前记录少了一条。
最后分析一下整个删除操作的最坏复杂度,还是以1G的bucket对16G的数据库文件记录为例:
1)首先查找元素,前面一节说了,需要O(4)次磁盘I/O+O(1)读取内存
2)接着置所删除记录的magic number,一次磁盘I/O
3)将删除插入到合适的free pool位置,这个下一节会提到,是在内存中进行的。
4)调整树结构,在所删除记录左右子树都存在的情况下,首先要找到最右子节点,这又是一个O(4)的磁盘I/O操作,最后将原记录的右子树赋值给最右子节点,又是一次磁盘I/O。不过,上面这个推断与前面是有矛盾的,假如在第一步查找中已经需要O(4)的代价才能定位到所删除元素了,那么最后的这个调整根本没有必要了。
先来看这个过程的流程图,其实很简单,包括以下几个按部就班的步骤:
a) 首先,根据key查找对应的记录,这个在上一节已经完整的介绍过了,当时也提到,查找操作是后续进行删除和插入新数据时的基础。
如果没有找到记录,说明原来就没有,那么就不必继续下去了。
假设现在找到了所要删除的数据,接着以下几步:
b) 将该记录的magic number置为0xb0,第一节讲解hash数据库概述的时候提到过,每条记录的头部信息中有两种不同magic number,根据这个判断一条记录是否被删除了,现在将这个magic number置为0xb0就是表示这条记录已经被删除了。
c) 将这条被删除的记录插入到free pool数组中的合适位置,这是下一节的重点,这里先知道这个操作就好。
d) 上一节提到过,同一个bucket index是以二叉树形式组织在一起的,虽然不是平衡的二叉树,但是删除了一个数据之后会破坏二叉树的性质,所以需要在二叉树中找到合适的记录来替换删除这条记录之后剩下的位置。
熟悉数据结构与算法的都知道,一个排序二叉树如果按照中序遍历的话,那么是有序的。所以要在删除一个记录之后仍然保持排序二叉树的有序性,是删除操作的重点,下面就是TC中删除一个记录时的调整算法:
if rec.left is not null and rec.right is null
child = rec.left
else if rec.left is null and rec.right is not null
child = rec.right
else if rec.left is null and rec.right is null
child = null
else
child = rec.left
right = rec.right
rec.right = child
while (rec.right is not null)
rec = rec.right
rec.right = right
replace rec's original place with child
child = rec.left
else if rec.left is null and rec.right is not null
child = rec.right
else if rec.left is null and rec.right is null
child = null
else
child = rec.left
right = rec.right
rec.right = child
while (rec.right is not null)
rec = rec.right
rec.right = right
replace rec's original place with child
也可以从下图中来理解当删除一个记录时,它的左右子节点都不为空时的处理:
从图中可以看出,当所要删除的节点左右子节点都不为空时,会去寻找左子树中的最右边的子节点,然后将待删除记录的右子树变成这个最右子节点的右子树。
需要注意到的是,经典的数据结构算法中,当在排序二叉树中删除一个节点之后,所做的调整与上面的流程有所不同,虽然也是找到的原记录的左子树的最右节点,但是是将这个最右节点直接替换掉原来记录的位置,也就是如下图:
所以,这里出现了一个新的问题,TC中的调整算法是有可能导致删除记录之后二叉树不平衡的,那么为什么不选用第二种方法呢?
我的理解是:
1) 如前一节所述,TC中的二叉树本来就不是必然平衡的,所以TC中的这种调整算法有可能会有“负负得正”的结果。
2)第二种经典的做法中,需要的调整包括:a)将最右子节点从原来的父节点上删除 b)最右子节点要替换原记录的位置,那么要将原记录的左右子树分别赋值变为最右子节点的左右子树。上面的这个调整,每次调整都是需要修改节点的,而每次修改都会有对磁盘的I/O操作。
而第一种做法呢,仅需要一次修改操作-----将原记录的右子树变成最右子节点的右子树即可。
综合这几个因素,TC选择了I/O较少的做法。
我不清楚我的理解是否合理,欢迎补充。
e)删除了记录,也跳整了树的结构之后,最后的工作就是更新数据库文件header的信息---因为当前记录少了一条。
最后分析一下整个删除操作的最坏复杂度,还是以1G的bucket对16G的数据库文件记录为例:
1)首先查找元素,前面一节说了,需要O(4)次磁盘I/O+O(1)读取内存
2)接着置所删除记录的magic number,一次磁盘I/O
3)将删除插入到合适的free pool位置,这个下一节会提到,是在内存中进行的。
4)调整树结构,在所删除记录左右子树都存在的情况下,首先要找到最右子节点,这又是一个O(4)的磁盘I/O操作,最后将原记录的右子树赋值给最右子节点,又是一次磁盘I/O。不过,上面这个推断与前面是有矛盾的,假如在第一步查找中已经需要O(4)的代价才能定位到所删除元素了,那么最后的这个调整根本没有必要了。
tokyocabinet1.4.19阅读笔记(四)hash数据库freepool的组织与管理
tokyocabinet1.4.19阅读笔记(四)hash数据库freepool的组织与管理
这一节关注freepool的组织,freepool顾名思义,就是负责存放被删除,空闲出来的空间,以便于后面回收利用.
在第一节中已经提到,这一个部分,在初始化的时候会全部读入采用malloc从堆中分配的内存中,所以对它的大部分操作都是直接在内存中进行的---除了要同步到数据库文件中时.
所有的freepool,以数组形式组织在一起,每个freepool元素结构体的定义是:
typedef struct { // type of structure for a free block
uint64_t off; // offset of the block
uint32_t rsiz; // size of the block
} HDBFB;可见,每个freepool关注的仅有两个因素:所保存block在数据库文件中的offset,以及这块block的尺寸.
当需要插入新的记录时,需要在当前的freepool中进行查询,看有没有适合的freepool可以回收利用,因此需要根据尺寸进行查询,所以为了提高查询速率,freepool数组中的元素是根据每个freepool的尺寸进行排序的,这样根据尺寸进行查找时就可以采用二分查找提高效率了,但是要注意到可能出现的找到的尺寸不符合要求,过大了(大于所需尺寸的一倍以上),这个时候会将这块freepool进行拆分,一部分给予使用,剩余的回收到freepool中.另外,如果在freepool中查找所需尺寸出现了很多次失败的情况(一旦失败表示没有符合要求的freepool可以回收利用,这时就需要增加数据库文件大小以加入新的记录了),就需要对freepool进行一次合并操作,将相邻的freepool合并起来形成尽可能大的freepool,而判断是否相邻的依据就是根据在数据库文件中的offset,此时又会将所有的freepool根据offset进行一次排序,然后再进行前面的合并操作.
以上就是freepool数组的大体组织情况,因为它保存在内存里面的,而且会经常有更新,那么就会出现当前的freepool与数据库文件中保存的freepool情况不一致的可能,所以在关闭/拷贝数据库的时候还要将内存中的freepool信息一次性的同步到数据库文件中,但是我注意到,在数据库运行期间是没有这个同步操作的,所以,一旦数据库被非法关闭,那么数据库文件中里面的freepool信息将完全的错乱,我想这也是TC不够安全的一个佐证吧.
下面简单的介绍TC hash数据库中与freepool相关的API:
1)static bool tchdbsavefbp(TCHDB *hdb)
将当前内存中freepool数组信息同步到数据库文件中,仅当关闭/拷贝数据库时被调用.
2) static bool tchdbloadfbp(TCHDB *hdb)
加载数据库文件中的freepool信息到内存中,与tchdbsavefbp是两个互逆的过程.
3) static void tcfbpsortbyoff(HDBFB *fbpool, int fbpnum)
根据offset对freepool数组进行排序
4) static void tcfbpsortbyrsiz(HDBFB *fbpool, int fbpnum)
根据size对freepool数组进行排序
5) static void tchdbfbpmerge(TCHDB *hdb)
将地址相邻的freepool进行合并,内部实现中首先会调用tcfbpsortbyoff对freepool根据offset进行排序,这样才方便合并操作.
6) static void tchdbfbpinsert(TCHDB *hdb, uint64_t off, uint32_t rsiz)
将一块block插入到合适的freepool中,插入之前和插入之后freepool数组都是根据size排序好的.
7) static bool tchdbfbpsearch(TCHDB *hdb, TCHREC *rec)
根据rec所要求的尺寸,查找一块合适的freepool回收利用,如果找到的freepool过大(大于所要求的一倍),那么就分为两份,一份负责插入rec,一份重新插入到合适的freepool中.
8) static bool tchdbfbpsplice(TCHDB *hdb, TCHREC *rec, uint32_t nsiz)
查看紧跟着rec的数据库文件空间是否是空闲的,如果是就合并进来,也就是加大rec的尺寸,以满足nsiz大小的要求.
9) static bool tchdbwritefb(TCHDB *hdb, uint64_t off, uint32_t rsiz)
将一块block置位空闲的(就是写它的magic number为0xb0)
总体来看,freepool是TC hash数据库中操作很频繁的一块数据区,在删除一条记录时需要将这条记录放到合适的freepool中,而新增记录时还需要从当前的freepool中查找合适的block,但是由于freepool是保存在内存中的,而且又进行过排序因此可以使用二分查找算法,所以对它进行的管理操作还是较为高效的.
这一节关注freepool的组织,freepool顾名思义,就是负责存放被删除,空闲出来的空间,以便于后面回收利用.
在第一节中已经提到,这一个部分,在初始化的时候会全部读入采用malloc从堆中分配的内存中,所以对它的大部分操作都是直接在内存中进行的---除了要同步到数据库文件中时.
所有的freepool,以数组形式组织在一起,每个freepool元素结构体的定义是:
typedef struct { // type of structure for a free block
uint64_t off; // offset of the block
uint32_t rsiz; // size of the block
} HDBFB;可见,每个freepool关注的仅有两个因素:所保存block在数据库文件中的offset,以及这块block的尺寸.
当需要插入新的记录时,需要在当前的freepool中进行查询,看有没有适合的freepool可以回收利用,因此需要根据尺寸进行查询,所以为了提高查询速率,freepool数组中的元素是根据每个freepool的尺寸进行排序的,这样根据尺寸进行查找时就可以采用二分查找提高效率了,但是要注意到可能出现的找到的尺寸不符合要求,过大了(大于所需尺寸的一倍以上),这个时候会将这块freepool进行拆分,一部分给予使用,剩余的回收到freepool中.另外,如果在freepool中查找所需尺寸出现了很多次失败的情况(一旦失败表示没有符合要求的freepool可以回收利用,这时就需要增加数据库文件大小以加入新的记录了),就需要对freepool进行一次合并操作,将相邻的freepool合并起来形成尽可能大的freepool,而判断是否相邻的依据就是根据在数据库文件中的offset,此时又会将所有的freepool根据offset进行一次排序,然后再进行前面的合并操作.
以上就是freepool数组的大体组织情况,因为它保存在内存里面的,而且会经常有更新,那么就会出现当前的freepool与数据库文件中保存的freepool情况不一致的可能,所以在关闭/拷贝数据库的时候还要将内存中的freepool信息一次性的同步到数据库文件中,但是我注意到,在数据库运行期间是没有这个同步操作的,所以,一旦数据库被非法关闭,那么数据库文件中里面的freepool信息将完全的错乱,我想这也是TC不够安全的一个佐证吧.
下面简单的介绍TC hash数据库中与freepool相关的API:
1)static bool tchdbsavefbp(TCHDB *hdb)
将当前内存中freepool数组信息同步到数据库文件中,仅当关闭/拷贝数据库时被调用.
2) static bool tchdbloadfbp(TCHDB *hdb)
加载数据库文件中的freepool信息到内存中,与tchdbsavefbp是两个互逆的过程.
3) static void tcfbpsortbyoff(HDBFB *fbpool, int fbpnum)
根据offset对freepool数组进行排序
4) static void tcfbpsortbyrsiz(HDBFB *fbpool, int fbpnum)
根据size对freepool数组进行排序
5) static void tchdbfbpmerge(TCHDB *hdb)
将地址相邻的freepool进行合并,内部实现中首先会调用tcfbpsortbyoff对freepool根据offset进行排序,这样才方便合并操作.
6) static void tchdbfbpinsert(TCHDB *hdb, uint64_t off, uint32_t rsiz)
将一块block插入到合适的freepool中,插入之前和插入之后freepool数组都是根据size排序好的.
7) static bool tchdbfbpsearch(TCHDB *hdb, TCHREC *rec)
根据rec所要求的尺寸,查找一块合适的freepool回收利用,如果找到的freepool过大(大于所要求的一倍),那么就分为两份,一份负责插入rec,一份重新插入到合适的freepool中.
8) static bool tchdbfbpsplice(TCHDB *hdb, TCHREC *rec, uint32_t nsiz)
查看紧跟着rec的数据库文件空间是否是空闲的,如果是就合并进来,也就是加大rec的尺寸,以满足nsiz大小的要求.
9) static bool tchdbwritefb(TCHDB *hdb, uint64_t off, uint32_t rsiz)
将一块block置位空闲的(就是写它的magic number为0xb0)
总体来看,freepool是TC hash数据库中操作很频繁的一块数据区,在删除一条记录时需要将这条记录放到合适的freepool中,而新增记录时还需要从当前的freepool中查找合适的block,但是由于freepool是保存在内存中的,而且又进行过排序因此可以使用二分查找算法,所以对它进行的管理操作还是较为高效的.
uint64_t off; // offset of the block
uint32_t rsiz; // size of the block
} HDBFB;
tokyocabinet1.4.19阅读笔记(五)hash数据库插入数据流程
tokyocabinet1.4.19阅读笔记(五)hash数据库插入数据流程
有了前面的基础,本节讲解插入数据的流程.
插入数据的实现代码,在函数tchdbputimpl中,首先这个函数会查找要插入记录的key是否已经存在,如果存在了,有很多case需要处理,在这里就不一一关注了,仅关注缺省的行为:如果key已经存在,那么覆盖原来的记录.否则,就插入新的记录.
所以,这里仅关注最简单的两种情况:如果存在就覆盖,如果不存在则插入新的记录.
1) 覆盖原记录
这里又区分两种情况:
a) 原有记录的尺寸不够插入新的记录,比如原有的记录是10个字节,但是新的记录需要20字节.这时候,首先会去调用上一节提到的tchdbfbpsplice函数去尝试着合并该记录邻近的空闲记录形成一个更大尺寸的记录块,上一节中没有仔细说明这个函数.tchdbfbpsplice的伪码大致如下:当还有空闲块可以合并
继续合并空闲块
如果合并之后的尺寸仍然不能满足要求,返回false
如果合并之后的尺寸大于所要求尺寸的两倍
将多余的部分写入合适的freepool中
返回true,表示找到合适的块
所以,假如合并成功有足够的尺寸,那么就直接将新的记录写入就好了.
否则,如果不能够满足又合并不到更大的块,则会将原先的记录块首先写入到freepool中(tchdbwritefb函数),接着直接在当前的freepool中查找合适的块(tchdbfbpsearch函数),如果找到合适的块,那么也写入新的记录即可.否则,上面的合并和查找空闲块的操作都失败了,则需要增加数据库文件的尺寸插入新的记录了.
b) 原有记录足够插入新的记录
这种情况下,还要判断旧的尺寸对于新的记录是不是过大了,过大的话也需要调整.
2) 新增新的记录
这种情况的处理很简单了,可以看作是上面的情况a)的一种情况,即接着直接在当前的freepool中查找合适的块(tchdbfbpsearch函数),如果找到合适的块,那么也写入新的记录即可.否则,则需要增加数据库文件的尺寸插入新的记录了.
注意,在上面的查找freepool过程中,如果失败的话,将增加一个计数,当这个计数大于一个值时,将对整个freepool做一个调整,调整算法前一节已经提及.
以上,就是插入新纪录的两种最简单情况的流程,如果对之前的freepool管理很清楚的话,理解起来不是难事,因为插入新的记录主要还是考虑如何回收利用原有的空闲块罢了.
有了前面的基础,本节讲解插入数据的流程.
插入数据的实现代码,在函数tchdbputimpl中,首先这个函数会查找要插入记录的key是否已经存在,如果存在了,有很多case需要处理,在这里就不一一关注了,仅关注缺省的行为:如果key已经存在,那么覆盖原来的记录.否则,就插入新的记录.
所以,这里仅关注最简单的两种情况:如果存在就覆盖,如果不存在则插入新的记录.
1) 覆盖原记录
这里又区分两种情况:
a) 原有记录的尺寸不够插入新的记录,比如原有的记录是10个字节,但是新的记录需要20字节.这时候,首先会去调用上一节提到的tchdbfbpsplice函数去尝试着合并该记录邻近的空闲记录形成一个更大尺寸的记录块,上一节中没有仔细说明这个函数.tchdbfbpsplice的伪码大致如下:当还有空闲块可以合并
继续合并空闲块
如果合并之后的尺寸仍然不能满足要求,返回false
如果合并之后的尺寸大于所要求尺寸的两倍
将多余的部分写入合适的freepool中
返回true,表示找到合适的块
所以,假如合并成功有足够的尺寸,那么就直接将新的记录写入就好了.
否则,如果不能够满足又合并不到更大的块,则会将原先的记录块首先写入到freepool中(tchdbwritefb函数),接着直接在当前的freepool中查找合适的块(tchdbfbpsearch函数),如果找到合适的块,那么也写入新的记录即可.否则,上面的合并和查找空闲块的操作都失败了,则需要增加数据库文件的尺寸插入新的记录了.
b) 原有记录足够插入新的记录
这种情况下,还要判断旧的尺寸对于新的记录是不是过大了,过大的话也需要调整.
2) 新增新的记录
这种情况的处理很简单了,可以看作是上面的情况a)的一种情况,即接着直接在当前的freepool中查找合适的块(tchdbfbpsearch函数),如果找到合适的块,那么也写入新的记录即可.否则,则需要增加数据库文件的尺寸插入新的记录了.
注意,在上面的查找freepool过程中,如果失败的话,将增加一个计数,当这个计数大于一个值时,将对整个freepool做一个调整,调整算法前一节已经提及.
以上,就是插入新纪录的两种最简单情况的流程,如果对之前的freepool管理很清楚的话,理解起来不是难事,因为插入新的记录主要还是考虑如何回收利用原有的空闲块罢了.
继续合并空闲块
如果合并之后的尺寸仍然不能满足要求,返回false
如果合并之后的尺寸大于所要求尺寸的两倍
将多余的部分写入合适的freepool中
返回true,表示找到合适的块
- hash数据库概述
- tokyocabinet1.4.19阅读笔记(一)hash数据库概述
- 数据库概述
- 数据库概述
- 数据库概述
- 数据库概述
- 数据库概述
- 数据库概述
- 数据库概述
- 数据库概述
- 数据库概述
- 数据库概述
- 数据库的hash索引
- 数据库-4 Hash算法
- 关于数据库、Hash 存储、 Hash表
- 分布式数据库概述
- [转]分布式数据库概述
- 分布式数据库概述
- java随机函数用法Random
- source insight打开工程挂掉问题和彻底删除source insigh的解决办法
- php检测上传excel文件类型
- Android4.0.3修改启动动画和开机声音
- The given object has a null identifier解决之法
- hash数据库概述
- 在myeclipse上部署没有java源文件的程序
- Android和ios哪个前景更好
- Ubuntu 安装配置 RabbitVCS
- ubuntu如何切换中文语言及中文输入法
- 17-4 奇数因子
- IOS 基础
- 大数据、云及解析
- Unity 角色模型优化要点


