局部特征
来源:互联网 发布:爱福窝软件 增加隔断 编辑:程序博客网 时间:2024/05/01 10:29
(转载请注明来源:http://blog.csdn.net/jiang1st2010/article/details/7621681)
局部特征(1)——入门篇
局部特征 (local features),是近来研究的一大热点。大家都了解全局特征(global features),就是方差、颜色直方图等等。如果用户对整个图像的整体感兴趣,而不是前景本身感兴趣的话,全局特征用来描述总是比较合适的。但是无法分辨出前景和背景却是全局特征本身就有的劣势,特别是在我们关注的对象受到遮挡等影响的时候,全局特征很有可能就被破坏掉了。而所谓局部特征,顾名思义就是一些局部才会出现的特征,这个局部,就是指一些能够稳定出现并且具有良好的可区分性的一些点了。这样在物体不完全受到遮挡的情况下,一些局部特征依然稳定存在,以代表这个物体(甚至这幅图像),方便接下来的分析。我们可以看下面这个图,左边一列是完整图像,中间一列是一些角点(就是接下来我们要讲的局部特征),右边一列则是除去角点以外的线段。不知道你会不会也觉得你看中间一列的时候能更敏感地把他们想象成左边一列的原始物品呢?一方面说,如果我们用这些稳定出现的点来代替整幅图像,可以大大降低图像原有携带的大量信息,起到减少计算量的作用。另一方面,当物体受到干扰时,一些冗余的信息(比如颜色变化平缓的部分和直线)即使被遮挡了,我们依然能够从未被遮挡的特征点上还原重要的信息。

把局部特征说的这么好听,你也许会问怎样的特征能够被当做局部特征点呢?我们不妨来看下面的这幅图:

我们选择了3个部分:边缘的点、边缘的线、变化缓慢的天空,当我在左边的图像中选择哪个部分的时候,你最有可能从右边的图像中找到对应的部分来呢?很显然是边缘的点吧-------天空,那么多都是一样的;而边缘,一条直线往左看往右看都是差不多的,你让我选哪个点(这也叫做aperture problem);而顶点相比之下更具有唯一性,所以局部特征最初的研究也就是从角点开始的(比如Harris Corner)。
一种定量的检测方法,就是通过SSD去比较两个块区域以定义一个相似度,值越小,两个块越相似:
![]()
当然我们应该知道,检测出的块应该和周围有一定的区分性,如何体现这种区分性,不妨做个试验:当前块和它的邻域做匹配,显然自己和自己匹配的时候值最小,而如果周围一定范围的值都特别小,那我们岂不是自己和自己都无法找到匹配,那还拿他当特征干啥?所以如果下式有明显极值,就可以把它当做特征点了。(式中的Δu表示当前块与比较邻域之间的位移)

这个过程就是早期的Harris Corner的核心思想(如果读者想了解Harris Corner的具体细节,请参见该系列的下一篇博客)。
总结一下,好的特征应该具有以下几个特点:
1、重复性:不同图像相同的区域应该能被重复检测到,而且不受到旋转、模糊、光照等因素的影响;
2、可区分性:不同的检测子,应该可以被区分出来,而为了区分它们,应运而生的就是与检测对应的描述子了;
3、数量适宜:检测子可别太多,不然啥阿猫阿狗都能出来混,但也不能太少,要求太高可就招不到人才了;
4、高定位(尺度和位置):是在哪出现的,最好就在哪被找到,可别跑偏了;
5、有效性:检测速度越快越好。
在接下来的几篇文章里,我主要针对局部特征,特别是目前使用的特别火热的SIFT特征和SURF特征进行一些描述和总结。这两个特征都是鲁棒性特别好的局部特征,被广泛应用在模式识别方面。
关于局部特征的更多介绍,请见http://download.csdn.net/download/jiang1st2010/4343689 ,下载ppt查看(免积分)。
局部特征(2)——Harris角点
在入门篇中偶尔谈到了Harris Corner,在这里我们就重点聊一聊Harris Corner。
Harris Corner是最典型的角点检测子Corner Detector。角点经常被检测在边缘的交界处、被遮挡的边缘、纹理性很强的部分。满足这些条件一般都是稳定的、重复性比较高的点,所以实际上他们是不是角点并不重要(因为我们的目标就是找一些稳定、重复性高的点以作为特征点)。
Harris Corner基于二阶矩阵:
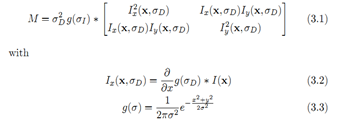
这个矩阵描述了局部邻域内梯度的分布情况。矩阵的两个特征值可以用来描述两个主要方向上信号的变化,因此特征值可以用来判决是否为特征点。Harris采用的判别方法是:
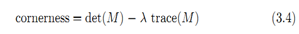
显而易见,cornerness的值越大,对应的两个特征值都应该很大,其中λ取0.04,是为了抑制比较明显的直线。最后对整幅图像得到的cornerness做一个非极大抑制,得到最后的特征点。Harris角点具有的优点是平移不变、旋转不变,能克服一定光照变化。可以先从一个例子上观察Harris Corner实现的过程:
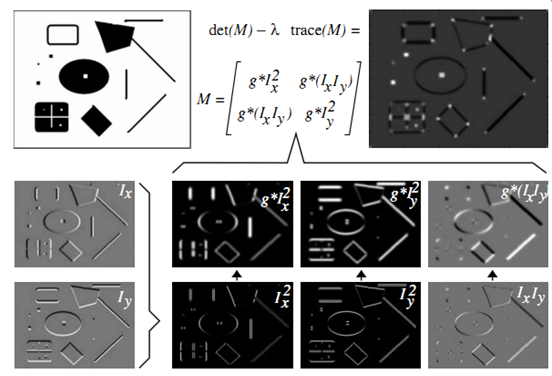
现在有几个问题:首先为什么3.1式矩阵的两个特征值可以用来描述两个主要方向上信号的变化;另外一个问题是为什么3.4式用来决定是否为角点。
要知道为什么3.1可以作为这个矩阵,我们了解一下具体怎么推出这个式子的,那这又要从Moravec算子说起,步骤如下:
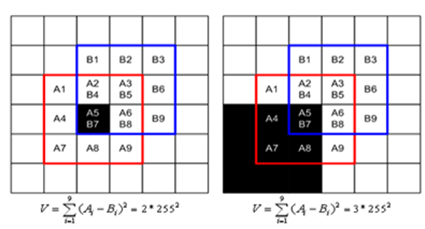
0)将要判断的点置于一个3*3或5*5的图像块的中心,如下图用红色的线环绕的图像块。
1)将红色的框朝8个方向移动一格,得到蓝色的框(下图为向右上角移动)。导致一个缺点:响应是各向异性的(啥意思?)
2)将红色的框和蓝色的框的相同坐标值的点的像素值相减,并求平方和,可以得到8个值。
3)将8个值中的最小的值作为角点像素的变化值。(因为角点应该在x、y方向上变化都比较大;而在边缘上只可能一个方向大、另一个方向小)
4)求出每一个像素点的角点像素变化值,在局部图像块中,该值最大的点为角点。
Harris算子将Moravec算子做了两个推广:
1)用像素的变化梯度代替像素值相减并引入高斯窗函数(举个x方向上变化的例子为证)。
引入高斯窗是为了滤除噪声的干扰。
 [-1,0,1]:x方向上的偏导,[-1,0,1]T:y方向上的偏导。
[-1,0,1]:x方向上的偏导,[-1,0,1]T:y方向上的偏导。
2)推广出了一个公式这样可以计算任意方向上的像素值变化,而不在是8个固定的方向。

(这里的u、v表示x/y方向的位移)
因为Vuv(x,y)的最小值才是这个点需要被考虑的值,因此我们重写以上表达式:

看到M矩阵的形式了么?这就是Harris算子的那个原始矩阵,我想推到这里,你也就应该了解Harris矩阵为什么是这样子的了。
第二个问题:为什么3.4可以用来描述是否为角点。
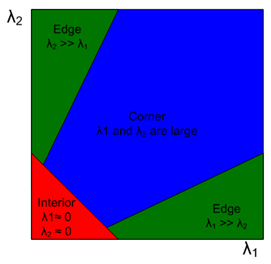
可以参考这样一个图:描述了不同纹理下α和β的取值情况:
a)没有什么纹理的情况下,两个值都很小(很小的正值)
b)边缘的点,一个值大,另外一个值小(由于k取了很小的值,所以3.4的结果为一个小负值)
c)角点:两个值都比较大(比较大的正值)
这样,当我们把目标函数定义为3.4式的时候,得到的结果就会尽力满足两个特征值都比较大了。当然,除此之外,还有Harmonic mean等方式实现更理想的组合方式达到检测出的两个特征值都尽可能大。
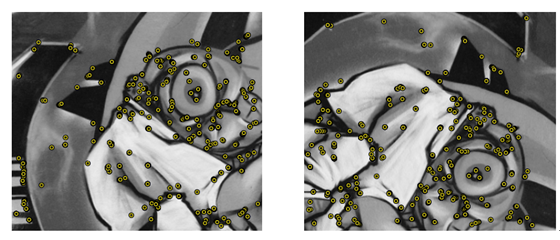
检测效果图(右图进行了旋转)
局部特征(3)——SURF特征总结
第一部分:兴趣点的检测
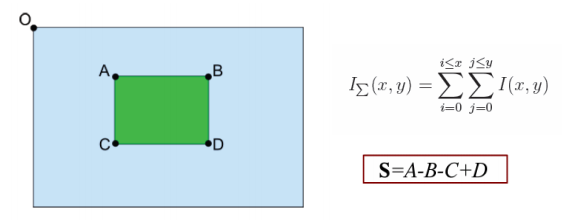
1、 建立积分图。
优点:任何一个垂直矩形区域的面积只需要进行3次 +/-法就能计算。一阶的haar小波响应只要5次+/-法就能计算。计算的时间和区域大小无关。
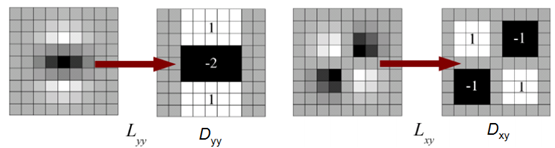
2、 建立图像的尺度空间(应该分别有Dxx、Dxy、Dyy 三个尺度金字塔):
用box filters代替二阶高斯差分模板。
保持图像的大小不变,对box filters进行尺度变换:建立高斯金字塔,金字塔分为多个Octaves,每个Octave分为4个Scale levels。第一级的Octave的模块大小为9、15、21、27(相差6),第二级为15、27、39、51(相差12),第三级为27、51、75、99(相差24)。每一级第一个level的大小为上一级第二个level的大小。继续建立高斯金字塔,直到filter的大小大于原图像的大小为止(问题是大于每一Octave的第一个mask大小还是最后一个mask的大小?)。
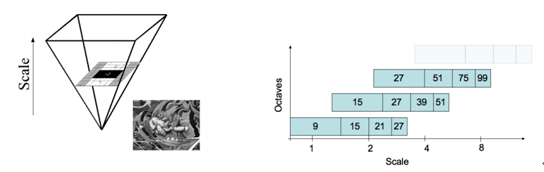
尺度变换的方法,与每个Octave第一个scale level的size(L)/3有关,例如第一个Octave的L为9,L/3=9/3=3,则对于每行/列,连续出现L/3个相同的值,则再插入2个相同的值。若某连续3行同时为1,则再插入两行0。若只连续1行为1,则1*(2/3)=1(四舍五入)。插入的行/列要求左右/上下对称。
3、 对于尺度空间中的每一个box filter,与图像卷积,计算每一点上的Dxx、Dyy、Dxy,再计算每一点Hessian矩阵的行列式。(卷积可以用积分图实现快速计算。)
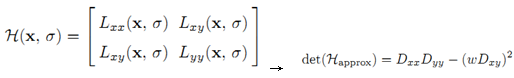
其中w是因为box filters只是高斯二阶差分的近似,为了使行列式的值大致相等,乘以这个权值,取0.9。注意,每Octave提高一级,计算行列式的时候,采样的间隔提高一倍。例如第一个Octave,每个点都计算,到了第二个Octave,隔一个点计算一个……(用增大模板大小,对图像上的点采样计算的方法,等同于实现对图像进行下采样并改变模板尺度的大小。)
对于每一个Octave,对计算出行列式的值设一个阈值,大于该阈值的列为候选兴趣点。对候选极值点进行非极大抑制:对于该level的周围8个点以及上下scale level相应位置的9*2个点,一共26个点进行比较行列式的大小,若该点是周围26个点中行列式最大的,则保留。(每一个Octave的头尾两个scale level是没法计算的。)
为什么可以用Hessian矩阵来判断极小值/极大值,请见最后。
最后,内插子像素精确定位(具体未看)。
第二部分:特征描述子
1、 主方向的确定(U-Surf没有此步骤)
s = 当前mask大小 * 1.2 / 9
以兴趣点为中心,确定6s为半径的圆。对圆内以s为步长的采样点计算haar小波响应(边长为4s)。
以兴趣点为中心,对小波响应进行高斯加权()。对一个扇形区间(比如π/3)的水平和垂直方向的小波响应分别求和。最长矢量对应的扇形方向就是主方向。(每一个扇形窗可否有重复?)
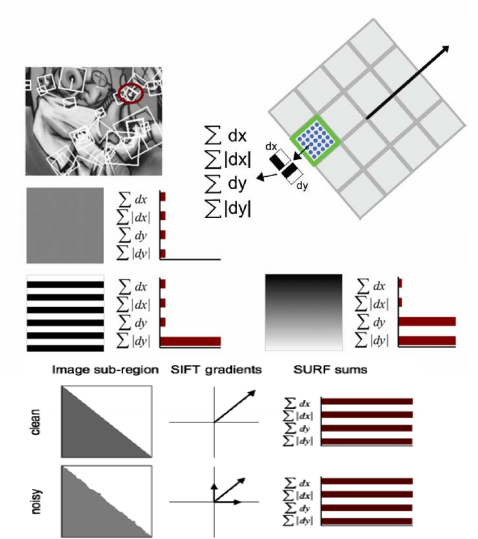
2、 以兴趣点为中心,主方向为参考x轴方向,20s为边长,做正方形区域,并将该区域分为4*4个子区域。(SURF-36把它分为3*3个子区域,区分性略差但速度快。)每个子区域取5*5个采样点,计算这些采样点上的haar小波响应dx和dy。以兴趣点为中心,对响应进行高斯加权(σ=3.3s)。
3、 对每个子区域的dx、dy、|dx|、|dy|进行求和,归一化为单位向量。对于4*4个子块一共可以构成64维空间。(SURF-128在统计dx和|dx|时,把dy分为大于0时候和小于0时候两种情况,而在统计dy和|dy|时将dx分为大于0和小于0两种情况,这样每个子区域是8维向量)。
附:最近的思考(2011.7.10补充):
1、为什么Hessian矩阵可以用来判断极大值/极小值
我的理解如下:
在x0点上,hessian矩阵是正定的,且各分量的一阶偏导数为0,则x0为极小值点。
在x0点上,hessian矩阵是负定的,且各分量的一阶偏导数为0,则x0为极大值点。
对于某个局部区域,若hessian矩阵是半正定的,则这个区域是凸的(反之依然成立);若负定,则这个区域是凹的(反之依然成立)。而对于正定和负定来说,Hessian矩阵的行列式总是大于等于0的。反过来就是说:某个点若是极大值/极小值,hessian矩阵的行列式必然要大于等于0,而大于等于0如果是满足的,这个点不一定是极大值/极小值(还要判断一阶导数)。所以后面还要进行极大值抑制。
与SURF相关的局部特征是SIFT,已经有很多专家对它讨论过了,这里我也不再多谈,如果大家对它感兴趣的话,请看这里,而接下来的这篇博客则对SIFT和SURF做了比较
局部特征(4)——SIFT和SURF的比较
(转载请注明来源: http://blog.csdn.net/jiang1st2010/article/details/6567452)
共同点:
SIFT/SURF为了实现不同图像中相同场景的匹配,主要包括三个步骤:
1、尺度空间的建立;
2、特征点的提取;
3、利用特征点周围邻域的信息生成特征描述子
4、特征点匹配。
从博客上看到一片文章,http://blog.csdn.net/cy513/archive/2009/08/05/4414352.aspx,这一段的大部分内容源于这篇文章,推荐大家去看看。
如果两幅图像中的物体一般只是旋转和缩放的关系,加上图像的亮度及对比度的不同,要在这些条件下要实现物体之间的匹配,SIFT算法的先驱及其发明者想到只要找到多于三对物体间的匹配点就可以通过射影几何的理论建立它们的一一对应。
如何找到这样的匹配点呢?SIFT/SURF作者的想法是首先找到图像中的一些“稳定点”,这些点是一些特殊的点,不会因为视角的改变、光照的变化、噪音的干扰而消失,比如角点、边缘点、暗区域的亮点以及亮区域的暗点。这样如果两幅图像中有相同的景物,那么这些稳定点就会在两幅图像的相同景物上同时出现,这样就能实现匹配。因此,SIFT/SURF算法的基础是稳定点。
SIFT/SURF提取的稳定点,首先都要求是局部极值。但是,当两个物体的大小比例不一样时,大图像的局部极值点在小图像的对应位置上有可能不是极值点。于是SIFT/SURF都采用图像金字塔的方法,每一个截面与原图像相似,这样两个金字塔中就有可能包含大小最近似的两个截面了。
这样找到的特征点会比较多,经过一些处理后滤掉一些相对不稳定的点。
接下来如何去匹配相同物体上对应的点呢?SIFT/SURF的作者都想到以特征点为中心,在周围邻域内统计特征,将特征附加到稳定点上,生成特征描述子。在遇到旋转的情况下,作者们都决定找出一个主方向,然后以这个方向为参考坐标进行后面的特征统计,就解决了旋转的问题。
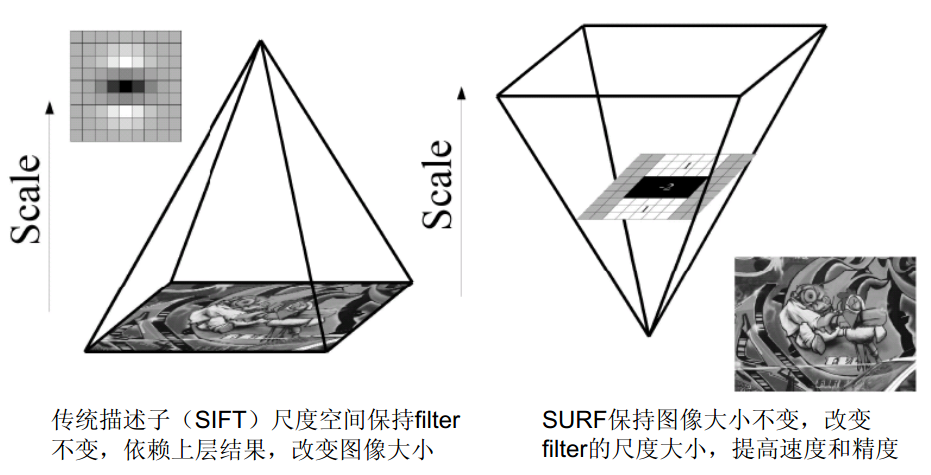
共同的大问题有以下几个:
1、为什么选用高斯金字塔来作特征提取?
为什么是DOG的金字塔?因为它接近LOG,而LOG的极值点提供了最稳定的特征,而且DOG方便计算(只要做减法。)
为什么LOG的极值点提供的特征最稳定,有参考文献,未看。
(7.12补充:)直观理解:特征明显的点经过不同尺度的高斯滤波器进行滤波后,差别较大,所以用到的是DOG。
但是直观上怎么理解?如果相邻Octave的sigma不是两倍关系还好理解:如果两幅图像只是缩放的关系,那么假设第一个Octave找到了小一倍图像的极值点,那么大一倍图像的极值点会在下一个Octave找到相似的。但是现在,如果把大一倍图像进行一次下采样(这样和小的图像就完全一样了),进行Gauss滤波时,两个图像滤波系数(sigma)是不一样的,不就找不到一样的极值点了么?不理解。
2、Hessian矩阵为什么能用来筛选极值点?
SIFT先利用非极大抑制,再用到Hessian矩阵进行滤除。SURF先用Hessian矩阵,再进行非极大抑制。SURF的顺序可以加快筛选速度么?(Hessian矩阵滤除的点更多?)
至于SURF先用Hessian矩阵,再进行非极大抑制的原因,是不管先极大值抑制还是判断Hessian矩阵的行列式,金字塔上的点的行列式都是要计算出来的。先判断是否大于0只要进行1次判断,而判断是否是极大值点或者极小值点要与周围26个点比较,只比较1次肯定快。
而在SIFT中,构建的高斯金字塔只有一座(不想SURF是有3座),要进行非极大抑制可以直接用金字塔的结果进行比较。而如果计算Hessian矩阵的行列式,还要再计算Dxx、Dxy、Dyy。因此先进行非极大抑制。这两个步骤的先后与SIFT/SURF的实际计算情况有关的,都是当前算法下的最佳顺序,而不是说哪种先计算一定更好。
3、为什么采用梯度特征作为局部不变特征?
这与人的视觉神经相关。采用梯度作为描述子的原因是,人的视觉皮层上的神经元对特定方向和空间频率的梯度相应很敏感,经过SIFT作者的一些实验验证,用梯度的方法进行匹配效果很好。
4、为什么可以采用某些特征点的局部不变特征进行整幅图像的匹配?
我在一份博客上找到这样一句话:(http://apps.hi.baidu.com/share/detail/32318290,大家可以看看这篇文章。)
从直观的人类视觉印象来看,人类视觉对物体的描述也是局部化的,基于局部不变特征的图像识别方法十分接近于人类视觉机理,通过局部化的特征组合,形成对目标物体的整体印象,这就为局部不变特征提取方法提供了生物学上的解释,因此局部不变特征也得到了广泛应用。
还有:
图像中的每个局部区域的重要性和影响范围并非同等重要,即特征不是同等显著的,其主要理论来源是Marr的计算机视觉理论和Treisman的特征整合理论,一般也称为“原子论”。该理论认为视觉的过程开始于对物体的特征性质和简单组成部分的分析,是从局部性质到大范围性质。
SIFT/SURF都是对特征点的局部区域的描述,这些特征点应该是影响重要的点,对这些点的分析更加重要。所以在局部不变特征的提取和描述时也遵循与人眼视觉注意选择原理相类似的机制,所以SIFT/SURF用于匹配有效果。
不同点的比较:
从博客上看到一个总结,我修改了一些内容。大家可以参看以下链接:
http://blog.csdn.net/ijuliet/archive/2009/10/07/4640624.aspx
SIFT
SURF
尺度空间
DOG与不同尺度的图片卷积
不同尺度的box filters与原图片卷积
特征点检测
先进行非极大抑制,再去除低对比度的点。再通过Hessian矩阵去除边缘的点
先利用Hessian矩阵确定候选点,然后进行非极大抑制
方向
在正方形区域内统计梯度的幅值的直方图,找max对应的方向。可以有多个方向。
在圆形区域内,计算各个扇形范围内x、y方向的haar小波响应,找模最大的扇形方向
特征描述子
16*16的采样点划分为4*4的区域,计算每个区域的采样点的梯度方向和幅值,统计成8bin直方图,一共4*4*8=128维
20*20s的区域划分为4*4的子区域,每个子区域找5*5个采样点,计算采样点的haar小波响应,记录∑dx,∑dy,∑|dx|,∑|dy|,一共4*4*4=64维
SURF—金字塔仅仅是用来做特征点的检测。在计算描述子的时候,haar小波响应是计算在原图像(利用积分图)。而SIFT是计算在高斯金字塔上(注意不是高斯差分金字塔。)
性能的比较:
论文:A comparison of SIFT, PCA-SIFT and SURF 对三种方法给出了性能上的比较,源图片来源于Graffiti dataset,对原图像进行尺度、旋转、模糊、亮度变化、仿射变换等变化后,再与原图像进行匹配,统计匹配的效果。效果以可重复出现性为评价指标。
比较的结果如下:
method
Time
Scale
Rotation
Blur
Illumination
Affine
Sift
common
best
best
common
common
good
Pca-sift
good
good
good
best
good
best
Surf
best
common
common
good
best
good
由此可见,SIFT在尺度和旋转变换的情况下效果最好,SURF在亮度变化下匹配效果最好,在模糊方面优于SIFT,而尺度和旋转的变化不及SIFT,旋转不变上比SIFT差很多。速度上看,SURF是SIFT速度的3倍。
局部特征(5)——如何利用彩色信息 Color Descriptors
(转载请注明出处:http://blog.csdn.net/jiang1st2010/article/details/7647766)
前面两讲中主要是针对SIFT和SURF做了一些介绍。他们的检测子比较稳定,描述子比较鲁棒,好像非常棒的样子。但是有一点非常遗憾,就是他们在对图像进行处理的过程中,都把图像转化为灰度图像进行处理,这样就丢失了颜色信息。而颜色,本身提供了很大的信息量,丢失了特别可惜。很多人可能就会想,如何在描述子中加入颜色信息。在这一讲中,我们就重点介绍一下改进的SIFT/SURF的Color Descriptor。
这里的Descriptor,其实我们可以把它当做大家传统上理解的特征。而特征,应该具有两个比较重要的特点。第一就是它应该是最有区分度、最有代表性的,应该尽可能减少冗余的信息。如果对于大多数物体来说,这个变量的值非常相近,没有什么区分性,自然不适合做特征。而另一个方面,它应该尽可能的稳定和鲁棒。对于同样的物体来说,当它因为噪声的变化或者图像的旋转、尺度变换等影响时,这个变量的值应该是尽可能不变的(invariant)。 我们要评价一个描述子是否鲁棒,重点就看图像被加入噪声后,形成的描述子是否依然稳定(也就是特征的各维是否不发生变化)。这里所谓的噪声,无外乎以下几种:

这里几乎把所有可能发生的线性变化都列出来了。可以考虑到,现有的灰度的SIFT/SURF特征对于1-3的变化具有不变性。这主要得益于1)他们都采用梯度的直方图(Haar小波也是计算了梯度),这样可以消除intensity shift。2)RGB的线性变化不影响梯度的方向。3)最终都对描述子向量做了归一化,解决了灰度的尺度变化。这样的话,我们需要考虑的就是如何解决4-5的颜色上的变化了。在此之前,我们先看看目前不用在SIFT/SURF上有哪些颜色特征,然后考虑把这些颜色特征放到描述子中。
1、RGB histogram,最常见的颜色直方图,你懂的,但是不具有任何不变性,想到这里以后还是换个特征用吧。
2、Opponent histogram
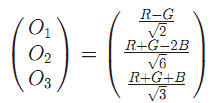
O1和O2表征了颜色信息,对lightintensity shift是不变的,不过O3这个直接与灰度相关的变量就不是了。
3、Hue histogram
这个大家也熟悉,它对灰度的尺度变化和增量变化具有不变性。所以说HSV颜色空间对于RGB颜色空间,在这一点上有着优势。
4、rg histogram
相当于对rgb分量做了一个归一化,归一化之后r/g分量就可以描述图像的颜色信息。其中b分量是多余的,因为r+g+b=1。Rg直方图对light intensity change是不变的,对于存在阴影的场景中可以尝试用。
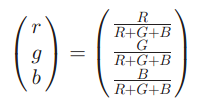
5、transformed colorhistogram
考虑到rgb直方图对于灰度和颜色的线性变化不具有任何不变性,但是如果我们考虑对RGB三个通道分别做归一化,归一化的方法如:
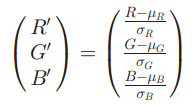
这样,通过减去均值可以抵消各通道的valueshift,通过除以方差可以抵消各通道的value scale change。(均值和方差以待统计的块为单位进行计算。)这样归一化之后的直方图对于light color change and shift是具有不变性的。
列举了颜色直方图的几种统计方法之后,我们可以把他们用在SIFT/SURF描述子之中。因为传统的SIFT/SURF描述子是对单通道进行统计的,当使用上述特征进行统计时,就是对多个通道分别计算描述子,最后形成一个多维的特征作为颜色描述子。重点想提一下的就是:
C-SIFT:利用Opponentinformation中的 O1/O3和O2/O3作为颜色特征,这么做的目的是为了消除O1和O2中的灰度信息,但是,这样做却不能对intensity shift有不变性。
Transformedcolor SIFT:这个特征将不仅对灰度的change和shift具有不变性,同时还对各颜色的shift和change都具有不变性;
RGB-SIFT:很有意思的就是由于Transformedcolor SIFT对各通道的线性变化都具有不变性,而Transformed就是RGB特征经过线性变换而来,因此RGB-SIFT和Transformed color SIFT具有同样的不变性(效果是一样的)。
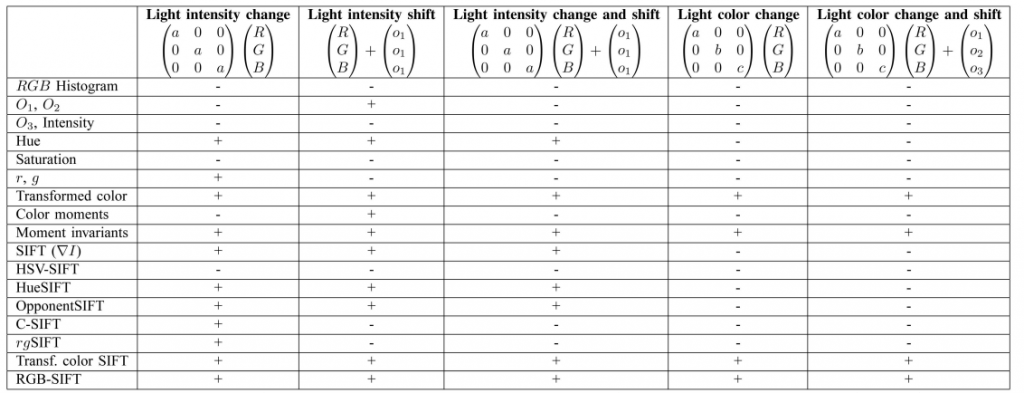
最后,对上面介绍的所有特征的不变性做一个总结,见下表,其中“+”表示对这一变化具有不变性,“-”则表示不具有这种不变性。
转载请注明出处:http://blog.csdn.net/jiang1st2010/article/details/7647766
- 局部特征
- 局部特征
- 局部特征
- 局部特征
- 局部特征算子简述
- 局部特征算子简述
- 局部特征算子简述
- 局部特征描述
- 局部特征算子简述
- 关于局部特征介绍
- 局部特征提取
- 局部特征图像描述
- SIFT局部特征算法
- 图像局部特征抽取
- 图像全局特征与局部特征
- 图像局部特征(十二)--BRISK特征
- 图像局部特征(十三)--FREAK特征
- 图像局部特征(十四)--MSER特征
- ASP.NET验证控件之CustomValidator
- V4L2 框架分析
- CAS技术原理及分析
- C++成长历程 之 小项目
- 使用jquery的lazy loader插件实现图片的延迟加载
- 局部特征
- CSS框架-SASS 用法指南
- linux sfdisk partition
- 集合映射
- Drools Planner(第1.1章节)
- CURD中添加操作存在的问题?
- Java RMISecurityManager
- 简单awk 命令
- Mjpg-Streamer 拍照功能移植


