聚类
来源:互联网 发布:mac tomcat 编辑:程序博客网 时间:2024/05/17 22:41
聚类(序)——监督学习与无监督学习
(转载本文请注明来源:http://blog.csdn.net/jiang1st2010/article/details/7654120)
机器学习的常用方法,主要分为有监督学习(supervised learning)和无监督学习(unsupervised learning)。监督学习,就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。在人对事物的认识中,我们从孩子开始就被大人们教授这是鸟啊、那是猪啊、那是房子啊,等等。我们所见到的景物就是输入数据,而大人们对这些景物的判断结果(是房子还是鸟啊)就是相应的输出。当我们见识多了以后,脑子里就慢慢地得到了一些泛化的模型,这就是训练得到的那个(或者那些)函数,从而不需要大人在旁边指点的时候,我们也能分辨的出来哪些是房子,哪些是鸟。监督学习里典型的例子就是KNN、SVM。无监督学习(也有人叫非监督学习,反正都差不多)则是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。这听起来似乎有点不可思议,但是在我们自身认识世界的过程中很多处都用到了无监督学习。比如我们去参观一个画展,我们完全对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别(比如哪些更朦胧一点,哪些更写实一些,即使我们不知道什么叫做朦胧派,什么叫做写实派,但是至少我们能把他们分为两个类)。无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
那么,什么时候应该采用监督学习,什么时候应该采用非监督学习呢?我也是从一次面试的过程中被问到这个问题以后才开始认真地考虑答案。一种非常简单的回答就是从定义入手,如果我们在分类的过程中有训练样本(training data),则可以考虑用监督学习的方法;如果没有训练样本,则不可能用监督学习的方法。但是事实上,我们在针对一个现实问题进行解答的过程中,即使我们没有现成的训练样本,我们也能够凭借自己的双眼,从待分类的数据中人工标注一些样本,并把他们作为训练样本,这样的话就可以把条件改善,用监督学习的方法来做。当然不得不说的是有时候数据表达的会非常隐蔽,也就是说我们手头的信息不是抽象的形式,而是具体的一大堆数字,这样我们很难凭借人本身对它们简单地进行分类。这个说的好像有点不大明白,举个例子说就是在bag-of-words模型的时候,我们利用k-means的方法聚类从而对数据投影,这时候用k-means就是因为我们当前到手的只有一大堆数据,而且是很高维的,当我们想把他们分为50个类的时候,我们已经无力将每个数据标记说这个数应该是哪个类,那个数又应该是哪个类了。所以说遇到这种情况也只有无监督学习能够帮助我们了。那么这么说来,能不能再深入地问下去,如果有训练样本(或者说如果我们可以获得到一些训练数据的话),监督学习就会比无监督学习更合适呢?(照我们单纯地想,有高人教总比自己领悟来的准,来的快吧!)我觉得一般来说,是这样的,但是这要具体看看训练数据的获取。本人在最近课题的研究中,手动标注了大量的训练样本(当然这些样本基本准确了),而且把样本画在特征空间中发现线性可分性非常好,只是在分类面附近总有一些混淆的数据样本,从而用线性分类器进行分类之后这样样本会被误判。然而,如果用混合高斯模型(GMM)来分的话,这些易混淆的点被正确分类的更多了。对这个现象的一个解释,就是不管是训练样本,还是待聚类的数据,并不是所有数据都是相互独立同分布的。换句话说,数据与数据的分布之间存在联系。在我阅读监督学习的大量材料中,大家都没有对训练数据的这一假设(独立同分布)进行说明,直到我阅读到一本书的提示后才恍然大悟。对于不同的场景,正负样本的分布如果会存在偏移(可能是大的偏移,也可能偏移比较小),这样的话用监督学习的效果可能就不如用非监督学习了。
聚类(1)——混合高斯模型 Gaussian Mixture Model
聚类的方法有很多种,k-means要数最简单的一种聚类方法了,其大致思想就是把数据分为多个堆,每个堆就是一类。每个堆都有一个聚类中心(学习的结果就是获得这k个聚类中心),这个中心就是这个类中所有数据的均值,而这个堆中所有的点到该类的聚类中心都小于到其他类的聚类中心(分类的过程就是将未知数据对这k个聚类中心进行比较的过程,离谁近就是谁)。其实k-means算的上最直观、最方便理解的一种聚类方式了,原则就是把最像的数据分在一起,而“像”这个定义由我们来完成,比如说欧式距离的最小,等等。想对k-means的具体算法过程了解的话,请看这里。而在这篇博文里,我要介绍的是另外一种比较流行的聚类方法----GMM(Gaussian Mixture Model)。
GMM和k-means其实是十分相似的,区别仅仅在于对GMM来说,我们引入了概率。说到这里,我想先补充一点东西。统计学习的模型有两种,一种是概率模型,一种是非概率模型。所谓概率模型,就是指我们要学习的模型的形式是P(Y|X),这样在分类的过程中,我们通过未知数据X可以获得Y取值的一个概率分布,也就是训练后模型得到的输出不是一个具体的值,而是一系列值的概率(对应于分类问题来说,就是对应于各个不同的类的概率),然后我们可以选取概率最大的那个类作为判决对象(算软分类soft assignment)。而非概率模型,就是指我们学习的模型是一个决策函数Y=f(X),输入数据X是多少就可以投影得到唯一的一个Y,就是判决结果(算硬分类hard assignment)。回到GMM,学习的过程就是训练出几个概率分布,所谓混合高斯模型就是指对样本的概率密度分布进行估计,而估计的模型是几个高斯模型加权之和(具体是几个要在模型训练前建立好)。每个高斯模型就代表了一个类(一个Cluster)。对样本中的数据分别在几个高斯模型上投影,就会分别得到在各个类上的概率。然后我们可以选取概率最大的类所为判决结果。
得到概率有什么好处呢?我们知道人很聪明,就是在于我们会用各种不同的模型对观察到的事物和现象做判决和分析。当你在路上发现一条狗的时候,你可能光看外形好像邻居家的狗,又更像一点点女朋友家的狗,你很难判断,所以从外形上看,用软分类的方法,是女朋友家的狗概率51%,是邻居家的狗的概率是49%,属于一个易混淆的区域内,这时你可以再用其它办法进行区分到底是谁家的狗。而如果是硬分类的话,你所判断的就是女朋友家的狗,没有“多像”这个概念,所以不方便多模型的融合。
从中心极限定理的角度上看,把混合模型假设为高斯的是比较合理的,当然也可以根据实际数据定义成任何分布的Mixture Model,不过定义为高斯的在计算上有一些方便之处,另外,理论上可以通过增加Model的个数,用GMM近似任何概率分布。
混合高斯模型的定义为:
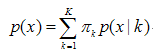
其中K为模型的个数,πk为第k个高斯的权重,则为第k个高斯的概率密度函数,其均值为μk,方差为σk。我们对此概率密度的估计就是要求πk、μk和σk各个变量。当求出的表达式后,求和式的各项的结果就分别代表样本x属于各个类的概率。
在做参数估计的时候,常采用的方法是最大似然。最大似然法就是使样本点在估计的概率密度函数上的概率值最大。由于概率值一般都很小,N很大的时候这个连乘的结果非常小,容易造成浮点数下溢。所以我们通常取log,将目标改写成:

也就是最大化log-likelyhood function,完整形式则为:

一般用来做参数估计的时候,我们都是通过对待求变量进行求导来求极值,在上式中,log函数中又有求和,你想用求导的方法算的话方程组将会非常复杂,所以我们不好考虑用该方法求解(没有闭合解)。可以采用的求解方法是EM算法——将求解分为两步:第一步是假设我们知道各个高斯模型的参数(可以初始化一个,或者基于上一步迭代结果),去估计每个高斯模型的权值;第二步是基于估计的权值,回过头再去确定高斯模型的参数。重复这两个步骤,直到波动很小,近似达到极值(注意这里是个极值不是最值,EM算法会陷入局部最优)。具体表达如下:
1、对于第i个样本xi来说,它由第k个model生成的概率为:
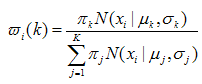
在这一步,我们假设高斯模型的参数和是已知的(由上一步迭代而来或由初始值决定)。
(E step)

(M step)
3、重复上述两步骤直到算法收敛(这个算法一定是收敛的,至于具体的证明请回溯到EM算法中去,而我也没有具体关注,以后补上)。

最后总结一下,用GMM的优点是投影后样本点不是得到一个确定的分类标记,而是得到每个类的概率,这是一个重要信息。GMM每一步迭代的计算量比较大,大于k-means。GMM的求解办法基于EM算法,因此有可能陷入局部极值,这和初始值的选取十分相关了。GMM不仅可以用在聚类上,也可以用在概率密度估计上。
聚类(2)——层次聚类 Hierarchical Clustering
(转载请注明来源:http://blog.csdn.net/jiang1st2010/article/details/7685809)
不管是GMM,还是k-means,都面临一个问题,就是k的个数如何选取?比如在bag-of-words模型中,用k-means训练码书,那么应该选取多少个码字呢?为了不在这个参数的选取上花费太多时间,可以考虑层次聚类。
假设有N个待聚类的样本,对于层次聚类来说,基本步骤就是:
1、(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2、寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3、重新计算新生成的这个类与各个旧类之间的相似度;
4、重复2和3直到所有样本点都归为一类,结束。
整个聚类过程其实是建立了一棵树,在建立的过程中,可以通过在第二步上设置一个阈值,当最近的两个类的距离大于这个阈值,则认为迭代可以终止。另外关键的一步就是第三步,如何判断两个类之间的相似度有不少种方法。这里介绍一下三种:
SingleLinkage:又叫做 nearest-neighbor ,就是取两个类中距离最近的两个样本的距离作为这两个集合的距离,也就是说,最近两个样本之间的距离越小,这两个类之间的相似度就越大。容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。
CompleteLinkage:这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。其效果也是刚好相反的,限制非常大,两个 cluster 即使已经很接近了,但是只要有不配合的点存在,就顽固到底,老死不相合并,也是不太好的办法。这两种相似度的定义方法的共同问题就是指考虑了某个有特点的数据,而没有考虑类内数据的整体特点。
Average-linkage:这种方法就是把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
average-linkage的一个变种就是取两两距离的中值,与取均值相比更加能够解除个别偏离样本对结果的干扰。
这种聚类的方法叫做agglomerative hierarchical clustering(自顶向下)的,描述起来比较简单,但是计算复杂度比较高,为了寻找距离最近/远和均值,都需要对所有的距离计算个遍,需要用到双重循环。另外从算法中可以看出,每次迭代都只能合并两个子类,这是非常慢的。尽管这么算起来时间复杂度比较高,但还是有不少地方用到了这种聚类方法,在《数学之美》一书的第14章介绍新闻分类的时候,就用到了自顶向下的聚类方法。
是这样的,谷歌02年推出了新闻自动分类的服务,它完全由计算机整理收集各个网站的新闻内容,并自动进行分类。新闻的分类中提取的特征是主要是词频因为对不同主题的新闻来说,各种词出现的频率是不一样的, 比如科技报道类的新闻很可能出现的词就是安卓、平板、双核之类的,而军事类的新闻则更可能出现钓鱼岛、航母、歼15、歼20这类词汇。一般对每篇文章提取TF-IDF(词频-逆文本频率值)特征,组成一个高维的特征向量(每一维表示一个词出现的TF-IDF值),然后采用监督学习或者非监督学习的方法对新闻进行分类。在已知一些新闻类别的特征的情况下,采用监督学习的方法是很OK的。但是在未知的情况下,就采用这种agglomerative hierarchical clustering进行自动分类。 这种分类方法的动机很有意思。1998年雅让斯基是某个国际会议的程序委员会主席,需要把提交上来的几百篇论文发给各个专家去评审是否录用。虽然论文的作者自己给定了论文的方向,但方向还是太广,没有什么指导意义。雅让斯基就想到了这个将论文自动分类的方法,由他的学生费罗里安很快实现了。
另外有一种聚类方法叫做divisive hierarchicalclustering(自下而上),过程恰好是相反的,一开始把所有的样本都归为一类,然后逐步将他们划分为更小的单元,直到最后每个样本都成为一类。在这个迭代的过程中通过对划分过程中定义一个松散度,当松散度最小的那个类的结果都小于一个阈值,则认为划分可以终止。这种方法用的不普遍,原文也没有做更多介绍。
不管是 agglomerative还是divisive实际上都是贪心算法了,也并不能保证能得到全局最优的。
层次聚类的一个例子,请参考http://home.dei.polimi.it/matteucc/Clustering/tutorial_html/hierarchical.html
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- 聚类
- .Net配置文件
- android制作开关机动画注意事项
- 二十四随感--我们一起奋斗过的日子
- 64位操作系统的IIS运行32位站点
- Twitter Storm如何保证消息不丢失
- 聚类
- 数据为空。不能对空值调用此方法或属性的解决办法
- Coding更改程序的变式(report variant change)
- Attribute value is quoted with " which must be escaped when used within the value 问题解决
- activity to View
- gif文件导出png
- android中一些基本知识的理解
- java final关键字
- ubuntu 10.10及以后版本修改为默认文本界面


