Hadoop Archive: File Compaction for HDFS
来源:互联网 发布:美工教学 编辑:程序博客网 时间:2024/05/18 18:02
Thanks to Tsz-Wo Nicholas Sze and Mahadev Konar for this article. (Tue July 27, 2010)
The Problem of Many Small Files
The Hadoop Distributed File System (HDFS) is designed to store and process large (terabytes) data sets. At Yahoo!, for example, a large production cluster may have 14 PB disk spaces and store 60 millions of files.
However, storing a large number of small files in HDFS is inefficient. We call a file smallwhen its size is substantially less than the HDFS block size, which is 128 MB by default. Files and blocks are name objects in HDFS and they occupy namespace. The namespace capacity of the system is naturally limited by the physical memory in the NameNode.
When there are many small files stored in the system, these small files occupy a large portion of the namespace. As a consequence, the disk space is underutilized because of the namespace limitation. In one of our production clusters, there are 57 millions files of sizes less than 128 MB, which means that these files contain only one block. These small files use up 95% of the namespace but only occupy 30% of the disk space.
Hadoop Archive (HAR) is an effective solution to the problem of many small files. HAR packs a number of small files into large files so that the original files can be accessed in parallel transparently (without expanding the files) and efficiently.
HAR increases the scalability of the system by reducing the namespace usage and decreasing the operation load in the NameNode. This improvement is orthogonal to memory optimization in NameNode and distributing namespace management across multiple NameNodes.
Hadoop Archive is also MapReduce-friendly — it allows parallel access to the original files by MapReduce jobs.
What is Hadoop Archive?
Hadoop Archive has three components: a data model that defines the archive format, a FileSystem interface that allows transparent access, and a tool for creating archives with MapReduce jobs.
The Data Model: har format
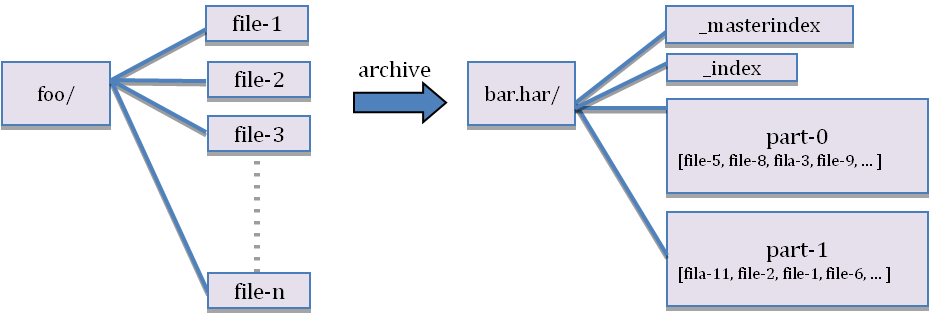
Figure 1: Archiving small files
The Hadoop Archive's data format is called har, with the following layout:
foo.har/_masterindex //stores hashes and offsets
foo.har/_index //stores file statuses
foo.har/part-[1..n] //stores actual file data
The file data is stored in multiple part files, which are indexed for keeping the original separation of data intact. Moreover, the part files can be accessed by MapReduce programs in parallel. The index files also record the original directory tree structures and the file statuses. In Figure 1, a directory containing many small files is archived into a directory with large files and indexes.
HarFileSystem – A first-class FileSystem providing transparent access
Most archival systems, such as tar, are tools for archiving and de-archiving. Generally, they do not fit into the actual file system layer and hence are not transparent to the application writer in that the user had to de-archive the archive before use.
Hadoop Archive is integrated in the Hadoop’s FileSystem interface. The HarFileSystemimplements the FileSystem interface and provides access via the har:// scheme. This exposes the archived files and directory tree structures transparently to the users. Files in a har can be accessed directly without expanding it. For example, we have the following command to copy a HDFS file to a local directory:
hadoop fs –get hdfs://namenode/foo/file-1 localdir
Suppose an archive bar.har is created from the foo directory. Then, the command to copy the original file becomes
hadoop fs –get har://namenode/bar.har#foo/file-1 localdir
Users only have to change the URI paths. Alternatively, users may choose to create a symbolic link (from hdfs://namenode/foo to har://namenode/bar.har#foo in the example above), then even the URIs do not need to be changed. In either case, HarFileSystem will be invoked automatically for providing access to the files in the har. Because of this transparent layer, har is compatible with the Hadoop APIs, MapReduce, the shell command -ine interface, and higher-level applications like Pig, Zebra, Streaming, Pipes, and DistCp.
The Archiving Tool: A MapReduce program for creating har
To create har efficiently in parallel, we implemented an archiving tool using MapReduce. The tool can be invoked by the command
hadoop archive -archiveName <name> <src>* <dest>
A list of files is generated by traversing the source directories recursively, and then the list is split into map task inputs. Each map task creates a part file (about 2 GB, configurable) from a subset of the source files and outputs the metadata. Finally, a reduce task collects metadata and generates the index files.
Future tasks
Currently, a har cannot be modified after it has been created. Supporting modifiable har is one candidate for future work. Once HFDS supports variable length blocks, har could possibly be created by moving the blocks metadata without copying the actual data. Then, har creation would be nearly instantaneous.
- Hadoop Archive: File Compaction for HDFS
- High Availability for the Hadoop Distributed File System (HDFS)
- Hadoop HDFS Wrong FS: hdfs:/ expected file:///
- Hadoop Distributed File System (HDFS)
- Hadoop .Net HDFS File Access
- Hadoop Distributed File System( HDFS)
- HDFS(Hadoop Distributed File System )常用命令示例:
- HDFS(Hadoop Distributed File System)简介
- Wrong FS: hdfs://localhost:9000/home/hadoop/hadoop, expected: file:///
- Archive file
- hadoop archive
- hadoop archive
- Spark WordCount 读写hdfs文件 (read file from hadoop hdfs and write output to hdfs)
- No FileSystem for scheme: hdfs,No FileSystem for scheme: file
- No FileSystem for scheme: hdfs,No FileSystem for scheme: file
- Hadoop使用java查询HDFS 错误:Wrong FS: hdfs://localhost:9000/user/hadoop, expected: file:///
- HDFS File System Shell Guide 转自Hadoop docs
- Hadoop Problem : Wrong FS: hdfs://localhost:9000/output, expected: file:///
- Android 单选按钮和复选框事例
- 静稳更有力量 ——Leo2012年终总结
- 越狱手机中开发bluetooth应用
- <asp.net>OleDb连接Oracle的两种方法
- jboss设置web应用的context root
- Hadoop Archive: File Compaction for HDFS
- 天天记录 - Windows 使用GIT下载Android Framework源码
- <一年成为Emacs高手>更新至20121225版.
- XML和XSL说明
- gcc&g++
- 状态模式和策略模式
- boost serialization 32位库与64位库间二进制数据读写
- 迷茫的大学------李开复
- 表格控件GridPanel


