Android -- SurfaceFlinger 分析
来源:互联网 发布:excel 2013数据有效性 编辑:程序博客网 时间:2024/05/21 05:59
Android -- SurfaceFlinger 概要分析系列 (一)
surfaceflinger 代码追踪
显示速度等等都与其相关,所以是必须破解的障碍,那么就深入学习吧。
基本处理流程:
应用程序直接与Surface交互,Surface就像是UI的画布,则APP则在Surface直接画图,最后由SurfaceFlinger进行混合所有Layer数据,在此利用OpenGL或者2D Copybit进行混合,最终送到framebuffer进行输出。
典型应用框架图如下:

那么以下我们就逐步进行分析吧。
首先看下基本的代码路径:
Frameworks/base/Libs/Surfaceflinger 图形合成系统
Frameworks/base/core/jni/android_view_Surface.cpp
Frameworks/base/core/java/android/view/surface.java
Frameworks/base/Graphics:绘图接口,JAVA及JNI层接口
Frameworks/base/Libs/UI
Frameworks/base/opengl 3D图形库,这里提供的3D软实现库
External/Skia Skia是一个C++的2D图形引擎库,Android的2D绘制系统都是建立在该基础,完成文本输出,位图,点,线,图像解码等功能
基本图形系统采用Client/Server架构:
Client端:应用程序相关部分。代码分为两部分,一部分是由Java提供的供应用使用的api, 另一部分则是由c++写成的底层实现。
Server端:即SurfaceFlinger,负责合成并送入buffer显示。其主要由c++代码编写而成。
Client和Server之前通过Binder的IPC方式进行通信,总体结构图如下:
Surface的client部分其实是提供给各应用程序进行画图操作的一个桥梁,该桥梁通过binder通向server端的 Surfaceflinger,Surfaceflinger负责合成各个surface,然后把buffer传送到framebuffer端进行底层显 示。其中每个surface对应2个buffer,一个front buffer, 一个back buffer,更新时,数据更新在back buffer上,需要显示时,则将back buffer和front buffer互换。
应用程序中的每个窗口,对应本地代码中的Surface,而Surface又对应 于SurfaceFlinger中的各个Layer,SurfaceFlinger的主要作用是为这些Layer申请内存,根据应用程序的请求管理这些 Layer显示、隐藏、
重画等操作,最终由SurfaceFlinger把所有的Layer组合到一起,显示到显示器上。
一、Surface的创建过程:
请看如下序列图:

那么创建 Surface 主要分为两个步骤:
1、建立 SurfaceSession
主要利用 SurfaceComposerClient 实例,调用 sp<ISurfaceFlingerClient> SurfaceFlinger::createConnection() 返回一个 ISurfaceFlingerClient接口给
SurfaceComposerClient,并在createConnection的过程中,SurfaceFlinger创建了用于管理缓冲
区切换的SharedClient。最后,本地层把SurfaceComposerClient的实例返回给 JAVA层,完成
SurfaceSession的建立。 这个过程一般只执行一次。
2、利用 SurfaceSession 创建 Surface
在 WindowManagerService.java 中创建不同属性的 Surface ,目前有如下三种类型: (Surface.java 中定义)
public static final int FX_SURFACE_NORMAL = 0x00000000; public static final int FX_SURFACE_BLUR = 0x00010000; public static final int FX_SURFACE_DIM = 0x00020000;
一般如此使用:
mSurface = new Surface(mSession.mSurfaceSession, mSession.mPid, mAttrs.getTitle().toString(), 0, w, h, mAttrs.format, flags)
比如没有硬件光标层就是在此创建一个Surface用于鼠标移动的显示,作为鼠标移动时的画布。
SurfaceFlinger::createSurface
根据flags创建不同类型的Layer,然后调用Layer的setBuffers()方法, 为该Layer创建了两个缓冲区,然后返回该Layer的ISurface接口,SurfaceComposerClient使用这个 ISurface接 口创建一个SurfaceControl实例,并把这个SurfaceControl返回给JAVA层。
重要代码:
sp<Layer> layer = new Layer(this, display, client, id); status_t err = layer->setBuffers(w, h, format, flags); ... return layer ;
二、获得Surface对应的显示缓冲区:
SurfaceFlinger在创建Layer时已经为每个Layer申请了两个缓冲区,但是此时在JAVA层并看不到这两个缓冲区, JAVA层要想在Surface上进行画图操作,必须要先把其中的一个缓冲区绑定到Canvas中,然后所有对该Canvas的画图操作最后都会画到该缓冲区内.

重要的几个操作分析:
/** draw into a surface */lockCanvas -> lockCanvasNative() --> JNI 函数static jobject Surface_lockCanvas(JNIEnv* env, jobject clazz, jobject dirtyRect){ /* 利用 SurfaceControl对象,通过getSurface() 取得本地层的Surface对象*/ const sp<Surface>& surface(getSurface(env, clazz)); // 利用dequeueBuffer(&backBuffer) 返回该Surface的信息,其中包含 Surface 缓冲区的首地址vaddr, 最后调用到libgralloc.so 动态库中去了,这个后面分析 status_t err = surface->lock(&info, &dirtyRegion);==> void* vaddr; status_t res = backBuffer->lock( GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN, newDirtyRegion.bounds(), &vaddr);...// 需要将 Surface 转换成 Bitmap 对象,这个JAVA对象直接在Canvas画图,其所有操作都会在以// vaddr为首的缓冲区中, 两个对象的关系通过setBitmapDevice建立SkBitmap bitmap; ssize_t bpr = info.s * bytesPerPixel(info.format); bitmap.setConfig(convertPixelFormat(info.format), info.w, info.h, bpr); if (info.format == PIXEL_FORMAT_RGBX_8888) { bitmap.setIsOpaque(true); } if (info.w > 0 && info.h > 0) { bitmap.setPixels(info.bits); } else { // be safe with an empty bitmap. bitmap.setPixels(NULL); } nativeCanvas->setBitmapDevice(bitmap); // bitmap绑定到Canvas中...}下面对 Surface::lock 补充说明一下:
a、dequeueBuffer(&backBuffer)获取backBuffer
SharedBufferClient->dequeue()获得当前空闲缓冲区的编号
通过缓冲区编号获得真正的GraphicBuffer:backBuffer 如果还没有对Layer中的buffer进行映射(Mapper),getBufferLocked通过ISurface接口重新重新映射
sp<GraphicBuffer> buffer = s->requestBuffer(index, usage);
b、获取frontBuffer --> const sp<GraphicBuffer>& frontBuffer(mPostedBuffer);
c、根据两个Buffer的更新区域,把frontBuffer的内容拷贝到backBuffer中,这样保证了两个Buffer中显示内容同步
利用 copyBlt(backBuffer, frontBuffer, copyback); --> 这里通过 memcpy,效率上是否有影响?
d、backBuffer->lock() 获得backBuffer缓冲区的首地址vaddr,最后通过info参数返回vaddr
三、释放Surface对应的显示缓冲区
画图完成后,要想把Surface的内容显示到屏幕上,需要把Canvas中绑定的缓冲区释放,并且把该缓冲区从
变成可投递(因为默认只有两个 buffer,所以实际上就是变成了frontBuffer),SurfaceFlinger的工作线程会
在适当的刷新时刻,把系统中所有的 frontBuffer混合在一起,然后通过OpenGL刷新到屏幕上。

/** unlock the surface and asks a page flip */public native void unlockCanvasAndPost(Canvas canvas);JNI 操作:static void Surface_unlockCanvasAndPost( JNIEnv* env, jobject clazz, jobject argCanvas){ const sp<Surface>& surface(getSurface(env, clazz));// 绑定一个空的bitmap到Canvas中nativeCanvas->setBitmapDevice(SkBitmap()); // unlock surface status_t err = surface->unlockAndPost();}status_t Surface::unlockAndPost() { status_t err = mLockedBuffer->unlock();err = queueBuffer(mLockedBuffer.get());}调用Surface的unlockAndPost方法
1、 调用GraphicBuffer的unlock(),解锁缓冲区
2、queueBuffer()调用了SharedBufferClient的queue(),把该缓冲区更新为可投递状态
================= 小概念==========================================
画图需要“四大金钢”相互合作:
Bitmap: 用于存储像素,也就是画布,可把它当做一块数据存储区域
Canvas: 用于记载画图的动作,比如画一个圆,矩形等,提供这些基本的绘图函数
Paint: 用于描述绘画时使用的颜色,风格(如实线,虚线)等
Drawing primitive: 绘图基元,如矩形,圆,文本,图片等
三、
SurfaceFlinger 属于system_server进程,在system_init.cpp中利用SurfaceFlinger::instantiate()启动,在此加入到service manager中,所以本身提供service服务功能。
首先看下SurfaceFlinger的类声明:
class SurfaceFlinger : public BinderService<SurfaceFlinger>, public BnSurfaceComposer, protected Thread
从接口可以看出使用Binder与客户端通讯,并且继承线程 Thread 类,则循环执行threadLoop。完成系统中的各个Layer-Surface进行混合,然后将一帧帧混合好的图像传送到显示framebuffer中。
其主线程工作流程图如下:
下面就这以上图五步将代码一一过一遍:
1、waitForEvent() 等待什么事情呢?
void SurfaceFlinger::waitForEvent(){ while (true) { ...... sp<MessageBase> msg = mEventQueue.waitMessage(timeout); ...... if (msg != 0) { switch (msg->what) { //等的就是这个消息事件哟。。。。 case MessageQueue::INVALIDATE: // invalidate message, just return to the main loop return; } } }}原来是等待收到MessageQueue::INVALIDATE重绘消息才退回到主线程,那么这个消息由谁来发送呢?请看下面代码:
void SurfaceFlinger::signalEvent() { mEventQueue.invalidate();}void SurfaceFlinger::signal() const { // this is the IPC call const_cast<SurfaceFlinger*>(this)->signalEvent();}这是就是发送消息的点,这个函数signalEvent由谁来调用呢?其个这个发起都是上一节说的,在释放Surface对应的显示缓冲区需要显示时调用:
unlockAndPost() --> queueBuffer() --> mClient.signalServer() --> SurfaceFlinger::signal()
2、handlePageFlip()
该阶段会遍历各个Layer,在每个Layer中,取得并锁住该Layer的frontBuffer,然后利用frontBuffer 中的图像数据生成该Layer的2D贴图(Texture),并且计算更新区域,为后续的混合操作做准备。
void SurfaceFlinger::handlePageFlip(){//调用 lockPageFlipvisibleRegions |= lockPageFlip(currentLayers);//取得屏幕的区域const Region screenRegion(hw.bounds());if (visibleRegions) { Region opaqueRegion; computeVisibleRegions(currentLayers, mDirtyRegion, opaqueRegion); ..... mWormholeRegion = screenRegion.subtract(opaqueRegion);}.....//调用 unlockPageFlipunlockPageFlip(currentLayers);}上面的调用实际上是一对函数:lockPageFlip & lockPageFlip,那么主要干些啥呢?bool SurfaceFlinger::lockPageFlip(const LayerVector& currentLayers){ bool recomputeVisibleRegions = false; size_t count = currentLayers.size(); sp<LayerBase> const* layers = currentLayers.array(); //逐个 layer 进行处理 for (size_t i=0 ; i<count ; i++) { const sp<LayerBase>& layer(layers[i]); layer->lockPageFlip(recomputeVisibleRegions); } return recomputeVisibleRegions;}void Layer::lockPageFlip(bool& recomputeVisibleRegions){ SharedBufferServer* lcblk(sharedClient.get());// 获取当前可用的 frontbuffer 索引号ssize_t buf = lcblk->retireAndLock();// 计算当前的脏区域 sp<GraphicBuffer> newFrontBuffer(getBuffer(buf)); if (newFrontBuffer != NULL) { // get the dirty region // compute the posted region const Region dirty(lcblk->getDirtyRegion(buf)); mPostedDirtyRegion = dirty.intersect( newFrontBuffer->getBounds() ); ....// 如果有脏区域需要重绘,则生成 OpenGL ES 纹理贴图reloadTexture( mPostedDirtyRegion );}void SurfaceFlinger::unlockPageFlip(const LayerVector& currentLayers){ const GraphicPlane& plane(graphicPlane(0)); const Transform& planeTransform(plane.transform()); size_t count = currentLayers.size(); sp<LayerBase> const* layers = currentLayers.array(); for (size_t i=0 ; i<count ; i++) { const sp<LayerBase>& layer(layers[i]);//进行区域的清理工作 layer->unlockPageFlip(planeTransform, mDirtyRegion); }}void Layer::unlockPageFlip( const Transform& planeTransform, Region& outDirtyRegion){ Region dirtyRegion(mPostedDirtyRegion); if (!dirtyRegion.isEmpty()) { mPostedDirtyRegion.clear();.... if (visibleRegionScreen.isEmpty()) { // an invisible layer should not hold a freeze-lock // (because it may never be updated and therefore never release it) mFreezeLock.clear(); }}以上的工作就是按照 Zorder 序计算自已屏幕上的可显示区域:1、以自己的W,H给出自己初始的可见区域
2、减去自己上面窗口所覆盖的区域
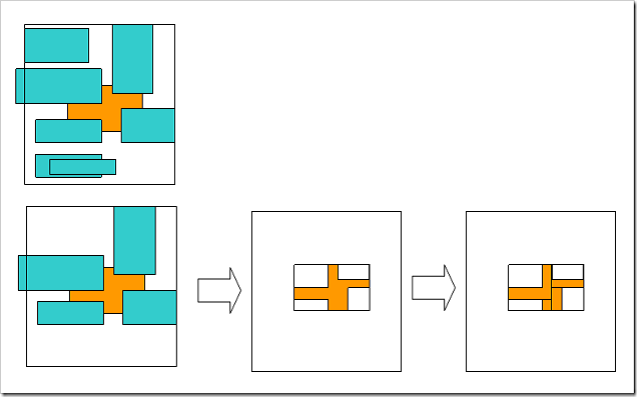
3、handleRepaint
每个Layer的数据都准备好了,并且各个脏区域也计算ok,下步就是根据 Zorder 序从底部将数据绘制到主Surface上
void SurfaceFlinger::handleRepaint(){ // compute the invalid region mInvalidRegion.orSelf(mDirtyRegion);.... // compose all surfaces composeSurfaces(mDirtyRegion); // clear the dirty regions mDirtyRegion.clear();}void SurfaceFlinger::composeSurfaces(const Region& dirty){... const size_t count = layers.size(); for (size_t i=0 ; i<count ; ++i) { const sp<LayerBase>& layer(layers[i]); const Region clip(dirty.intersect(layer->visibleRegionScreen)); if (!clip.isEmpty()) { // 这就是绘图核心函数 layer->draw(clip); } }}void Layer::onDraw(const Region& clip) const---> drawWithOpenGL(clip, tex); 基本上都是OpenGL ES 操作函数 while (it != end) { const Rect& r = *it++; const GLint sy = fbHeight - (r.top + r.height()); // 裁剪 glScissor(r.left, sy, r.width(), r.height()); // 画矩形 glDrawArrays(GL_TRIANGLE_FAN, 0, 4); }4、unlockClients()
释放 handlePageFlip 占用的 frontbuffer 索引号,以便客户端可以继续在新的surface画图
void SurfaceFlinger::unlockClients(){... for (size_t i=0 ; i<count ; ++i) { const sp<LayerBase>& layer = layers[i]; layer->finishPageFlip(); }}-->SharedBufferServer* lcblk(sharedClient.get());status_t err = lcblk->unlock( buf );现在已经将所有的Layer图层数据合成完成,最后就是输入到屏幕上显示了
void SurfaceFlinger::postFramebuffer(){//调用此函数将混合后的图像传递到屏幕中进行显示hw.flip(mInvalidRegion);...}void DisplayHardware::flip(const Region& dirty) const{// 显示图像吧。。。。。 eglSwapBuffers(dpy, surface);}- Android -- SurfaceFlinger 分析
- Android SurfaceFlinger分析
- Android Surfaceflinger源码分析
- Android surfaceflinger 源代码分析
- Android Graphic SurfaceFlinger分析
- Android SurfaceFlinger process 流程分析
- Android Display System --- SurfaceFlinger分析
- Android -- SurfaceFlinger 概要分析系列
- Android SurfaceFlinger VSync流程分析
- Android -- SurfaceFlinger 概要分析系列 (一)
- Android -- SurfaceFlinger 概要分析系列 (一)
- Android SurfaceFlinger服务启动过程源码分析
- android L 的surfaceflinger服务启动分析
- Android Application与SurfaceFlinger连接过程分析
- android surfaceflinger
- Android display架构分析七-Surfaceflinger process流程分析
- Android display架构分析七-Surfaceflinger process流程分析
- android surfaceflinger研究----SurfaceFlinger loop
- 逆序输出数字并求最大最小值
- WPF multi-thread - Dispatcher WPF多线程 - Dispatcher
- 抽象的操作系统(六) --- 网络
- hdu 1426——Dancing links
- EditText的监听事件
- Android -- SurfaceFlinger 分析
- 提高你开发效率的十五个Visual Studio 2010使用技巧
- 嵌入式系统--ARM指令格式及其寻址方式
- 在 SQLplus 上用普通用户登录的步骤。
- usb枚举流程图
- Shell定时利用data dump导出完整数据库
- Java NIO使用及原理分析(二)
- 六种方式实现hibernate查询
- 判断浮点数溢出的方法


