SSE intrinsic函数_优化
来源:互联网 发布:通达信布林线公式源码 编辑:程序博客网 时间:2024/05/20 17:10
原文地址http://blog.csdn.net/guoqiangma/article/details/5455661
编写一个基于SSE多媒体指令集的快速矩阵加法运算函数,输入参数为两个单精度浮点型数组srcA与srcB,长度为N,输出结果保存在一个单精度浮点型数组dest中,假设srcA、srcB以及dest内存空间的首地址均按照16-byte对齐。请利用多媒体指令集获得最大的程序性能(可以使用Visual Studio中的SSE intrinsic函数)
推荐函数定义:void SSE_Add(float* srcA, float* srcB, float* dest, int M) {}
编程实现:
// SSE.cpp : 定义控制台应用程序的入口点。//#include "stdafx.h"#include <xmmintrin.h>#include <iomanip>#include <stdlib.h>#include <time.h>#include <windows.h>#include<iostream>using namespace std; void SSE_Add(float* srcA, float* srcB, float* dest, int N){ __m128 a, b, c; int len = N/4; for(int i=0;i<4*len;i=i+4) { a = _mm_set_ps(srcA[i+3], srcA[i+2], srcA[i+1], srcA[i]); b = _mm_set_ps(srcB[i+3], srcB[i+2], srcB[i+1], srcB[i]); c = _mm_set_ps(0, 0, 0, 0); c = _mm_add_ps(a, b); dest[i+3] = c.m128_f32[3]; dest[i+2] = c.m128_f32[2]; dest[i+1] = c.m128_f32[1]; dest[i] = c.m128_f32[0]; } int last = N-4*len; //cout <<last<<endl; if(last == 3) { int i = 4*len; a = _mm_set_ps(0, srcA[i+2], srcA[i+1], srcA[i]); b = _mm_set_ps(0, srcB[i+2], srcB[i+1], srcB[i]); c = _mm_set_ps(0, 0, 0, 0); c = _mm_add_ps(a, b); dest[i+2] = c.m128_f32[2]; dest[i+1] = c.m128_f32[1]; dest[i] = c.m128_f32[0]; } if(last == 2) { int i = 4*len; a = _mm_set_ps(0, 0, srcA[i+1], srcA[i]); b = _mm_set_ps(0, 0, srcB[i+1], srcB[i]); c = _mm_set_ps(0, 0, 0, 0); c = _mm_add_ps(a, b); dest[i+1] = c.m128_f32[1]; dest[i] = c.m128_f32[0]; } if(last == 1) { int i = 4*len; a = _mm_set_ps(0, 0, 0, srcA[i]); b = _mm_set_ps(0, 0, 0, srcB[i]); c = _mm_set_ps(0, 0, 0, 0); c = _mm_add_ps(a, b); dest[i] = c.m128_f32[0]; }} void normal_Add(float* srcA, float* srcB, float* dest, int N){ for(int i=0;i<N;i++) dest[i] = srcA[i] + srcB[i];} int main(){ double len=100009;//len=100010; double run_time; double duration,duration1; float *srcA = new float[len]; float *srcB = new float[len]; float *dest = new float[len]; int i; for( i=0;i<len;i++) { srcA[i] = (float)i; srcB[i] = (float)i; } SYSTEMTIME sys; SYSTEMTIME sys_end; double calcRunTime; /* SSE_Add(srcA,srcB,dest,len); for(int i=0;i<len;i++) cout<<setw(7)<<dest[i]<<endl;*/ for(int m =0 ;m<3;m++) { cout<<"第"<<m<<"次测试:"<<endl; run_time = 10; for(;run_time <1000000;run_time = run_time*10) { calcRunTime = len * run_time; cout<<"运行"<<calcRunTime<<"次加法:"; //优化前 GetLocalTime( &sys ); for(i=0;i<run_time;i++) normal_Add(srcA,srcB,dest,len); GetLocalTime( &sys_end ); duration = sys_end.wHour*3600000+sys_end.wMinute*60000 + sys_end.wSecond*1000+sys_end.wMilliseconds -(sys.wHour*3600000+sys.wMinute*60000 + sys.wSecond*1000+sys.wMilliseconds); cout<<"优化前"<<"用时"<<duration<<"ms "; //优化后 GetLocalTime( &sys ); for(i=0;i<run_time;i++) SSE_Add(srcA,srcB,dest,10000); GetLocalTime( &sys_end ); duration1 = sys_end.wHour*3600000+sys_end.wMinute*60000 + sys_end.wSecond*1000+sys_end.wMilliseconds -(sys.wHour*3600000+sys.wMinute*60000 + sys.wSecond*1000+sys.wMilliseconds); float speedup; if(duration1 == 0) speedup = 0; else speedup = duration/duration1; cout<<"优化后"<<"用时"<<duration1<<"ms"<<"速度提高"<<speedup<<"倍"<<endl; } } return 0;}
运行环境:
Cpu T7250 ,内存:1G,XP系统
优化结果截图
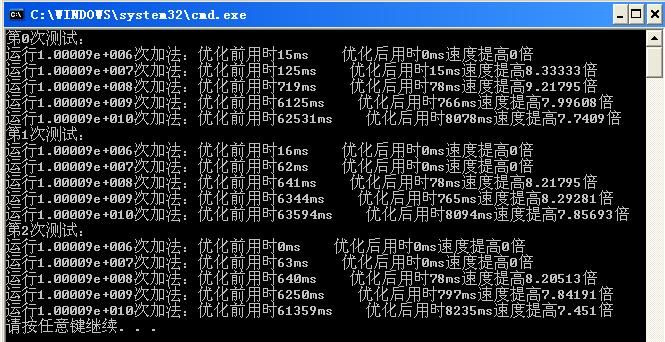
- SSE intrinsic函数_优化
- SSE intrinsic函数_优化
- SSE intrinsic函数_优化
- SSE指令 intrinsic函数总结(持续更新...)
- 在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
- 在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
- 在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
- 在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
- 在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
- 在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
- 在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
- 在C/C++代码中使用SSE等指令集的指令(4)SSE指令集Intrinsic函数使用
- SSE指令集学习:Compiler Intrinsic
- SSE intrinsic的几个指令_mm_prefetch/_mm_movehl_ps/_mm_shuffle_ps
- 跨平台使用Intrinsic函数范例1——使用SSE、AVX指令集 处理 单精度浮点数组求和(支持vc、gcc,兼容Windows、Linux、Mac)
- 使用SSE指令优化的数学函数(整理)
- 使用SSE指令优化的数学函数(整理)
- 使用SSE指令优化的数学函数(整理)
- CentOS 6.3 VNC安装
- [IOS视图切换]ViewDeck类似path效果的实现
- ubuntu字典stardict安装——屏幕取词,好用
- Mac OS X 过往12年的演变史
- winsock
- SSE intrinsic函数_优化
- seandroid对selinux的改进
- Java中一个简单易用的JAD 反编译工具
- STL经典算法集锦之排列(next_permutation/prev_permutation
- ubuntu12.04 安装chromium
- 关于System.out.println
- Why are destructors not virtual by default?
- 黑马程序员----JAVA----基础小结----
- 在Openssl 0.9.7c 下找不到 SHA512 算法


