Sparse Autoencoder3-Gradient checking and advanced optimization
来源:互联网 发布:欧洲哪里最好玩 知乎 编辑:程序博客网 时间:2024/06/03 03:35
Backpropagation is a notoriously difficult algorithm to debug and get right, especially since many subtly buggy implementations of it—for example, one that has an off-by-one error in the indices and that thus only trains some of the layers of weights, or an implementation that omits the bias term—will manage to learn something that can look surprisingly reasonable (while performing less well than a correct implementation). Thus, even with a buggy implementation, it may not at all be apparent that anything is amiss. In this section, we describe a method for numerically checking the derivatives computed by your code to make sure that your implementation is correct. Carrying out the derivative checking procedure described here will significantly increase your confidence in the correctness of your code.
Suppose we want to minimize 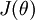 as a function of
as a function of 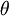 . For this example, suppose
. For this example, suppose 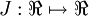 , so that
, so that 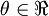 . In this 1-dimensional case, one iteration of gradient descent is given by
. In this 1-dimensional case, one iteration of gradient descent is given by
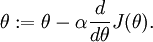
Suppose also that we have implemented some function 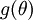 that purportedly computes
that purportedly computes 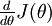 , so that we implement gradient descent using the update
, so that we implement gradient descent using the update 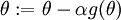 . How can we check if our implementation of
. How can we check if our implementation of 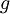 is correct?
is correct?
Recall the mathematical definition of the derivative as
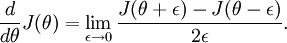
Thus, at any specific value of , we can numerically approximate the derivative as follows:
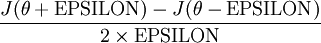
In practice, we set EPSILON to a small constant, say around 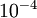 . (There's a large range of values of EPSILON that should work well, but we don't set EPSILON to be "extremely" small, say
. (There's a large range of values of EPSILON that should work well, but we don't set EPSILON to be "extremely" small, say 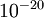 , as that would lead to numerical roundoff errors.)
, as that would lead to numerical roundoff errors.)
Thus, given a function that is supposedly computing , we can now numerically verify its correctness by checking that
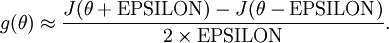
The degree to which these two values should approximate each other will depend on the details of 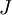 . But assuming
. But assuming 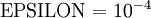 , you'll usually find that the left- and right-hand sides of the above will agree to at least 4 significant digits (and often many more).
, you'll usually find that the left- and right-hand sides of the above will agree to at least 4 significant digits (and often many more).
Now, consider the case where 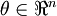 is a vector rather than a single real number (so that we have
is a vector rather than a single real number (so that we have 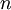 parameters that we want to learn), and
parameters that we want to learn), and 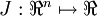 . In our neural network example we used "
. In our neural network example we used "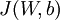 ," but one can imagine "unrolling" the parameters
," but one can imagine "unrolling" the parameters 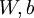 into a long vector . We now generalize our derivative checking procedure to the case where may be a vector.
into a long vector . We now generalize our derivative checking procedure to the case where may be a vector.
Suppose we have a function 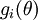 that purportedly computes
that purportedly computes 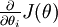 ; we'd like to check if
; we'd like to check if 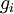 is outputting correct derivative values. Let
is outputting correct derivative values. Let 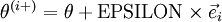 , where
, where
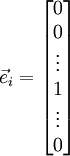
is the  -th basis vector (a vector of the same dimension as , with a "1" in the -th position and "0"s everywhere else). So,
-th basis vector (a vector of the same dimension as , with a "1" in the -th position and "0"s everywhere else). So, 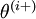 is the same as , except its -th element has been incremented by EPSILON. Similarly, let
is the same as , except its -th element has been incremented by EPSILON. Similarly, let 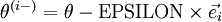 be the corresponding vector with the -th element decreased by EPSILON. We can now numerically verify 's correctness by checking, for each , that:
be the corresponding vector with the -th element decreased by EPSILON. We can now numerically verify 's correctness by checking, for each , that:
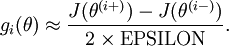
When implementing backpropagation to train a neural network, in a correct implementation we will have that
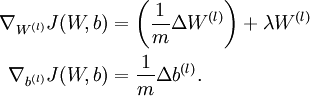
This result shows that the final block of psuedo-code in Backpropagation Algorithm is indeed implementing gradient descent. To make sure your implementation of gradient descent is correct, it is usually very helpful to use the method described above to numerically compute the derivatives of , and thereby verify that your computations of 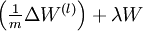 and
and 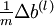 are indeed giving the derivatives you want.
are indeed giving the derivatives you want.
Finally, so far our discussion has centered on using gradient descent to minimize . If you have implemented a function that computes and 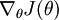 , it turns out there are more sophisticated algorithms than gradient descent for trying to minimize . For example, one can envision an algorithm that uses gradient descent, but automatically tunes the learning rate
, it turns out there are more sophisticated algorithms than gradient descent for trying to minimize . For example, one can envision an algorithm that uses gradient descent, but automatically tunes the learning rate 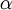 so as to try to use a step-size that causes to approach a local optimum as quickly as possible. There are other algorithms that are even more sophisticated than this; for example, there are algorithms that try to find an approximation to the Hessian matrix, so that it can take more rapid steps towards a local optimum (similar to Newton's method). A full discussion of these algorithms is beyond the scope of these notes, but one example is the L-BFGS algorithm. (Another example is the conjugate gradient algorithm.) You will use one of these algorithms in the programming exercise. The main thing you need to provide to these advanced optimization algorithms is that for any , you have to be able to compute and . These optimization algorithms will then do their own internal tuning of the learning rate/step-size (and compute its own approximation to the Hessian, etc.) to automatically search for a value of that minimizes . Algorithms such as L-BFGS and conjugate gradient can often be much faster than gradient descent.
so as to try to use a step-size that causes to approach a local optimum as quickly as possible. There are other algorithms that are even more sophisticated than this; for example, there are algorithms that try to find an approximation to the Hessian matrix, so that it can take more rapid steps towards a local optimum (similar to Newton's method). A full discussion of these algorithms is beyond the scope of these notes, but one example is the L-BFGS algorithm. (Another example is the conjugate gradient algorithm.) You will use one of these algorithms in the programming exercise. The main thing you need to provide to these advanced optimization algorithms is that for any , you have to be able to compute and . These optimization algorithms will then do their own internal tuning of the learning rate/step-size (and compute its own approximation to the Hessian, etc.) to automatically search for a value of that minimizes . Algorithms such as L-BFGS and conjugate gradient can often be much faster than gradient descent.
- Sparse Autoencoder3-Gradient checking and advanced optimization
- fminunc isnot Gradient Descent but a Advanced Optimization
- Advanced FPGA Design: Architecture, Implementation, and Optimization
- Gradient Boosting Classifier sparse matrix issue using pandas and scikit
- deeplearning-Gradient Checking
- MLlib - Optimization Module - Gradient
- Optimization:Stochastic Gradient Descent
- Optimization: Stochastic Gradient Descent
- CS231n Optimization: Stochastic Gradient Descent
- Improving Deep Neural Networks Gradient Checking 参考答案
- 改善深层神经网络第一周-Gradient Checking
- deeplearning.ai-lecture2-week1-Gradient Checking-homework
- Filesystem Formatting and Checking
- Testing and Checking Refined
- Gradient-based Hyperparameter Optimization through Reversible Learning
- An overview of gradient descent optimization algorithms
- An overview of gradient descent optimization algorithms
- An overview of gradient descent optimization algorithms
- 如何使Android应用程序获取系统权限【转】
- 个人常用 Linux
- drupal7 内核 自带的模板文件
- USTCOJ 1365 字符串计数
- sphinx全文索引教程 .
- Sparse Autoencoder3-Gradient checking and advanced optimization
- Android权限机制总结与常见权限不足问题分析
- gethostbyname出错 获取错误描述 Host name lookup failure
- 完全卸载oracle11g步骤
- 性能调优
- Linux下动态链接
- 画出wav文件声音数据的波形曲线
- 如何说服开发人员和设计师加入你的创业团队
- 什么是多态?为什么用多态?有什么好处?


