JVM调优:选择合适的GC collector
来源:互联网 发布:阿里云 安装包 编辑:程序博客网 时间:2024/05/18 00:59
正文之前,先介绍一人:Jon Masamitsu。此人背景不详,不过他在SUN做的就是JVM,所以他的blog我认为是每一个想对JVM调优的人都应该读一读的。本文的很多观点和一些图也是取自他的blog。
blog link:http://blogs.sun.com/jonthecollector/
在他的一篇blog【1】中,写到了GC调优的最重要的三个选项:
排在第三位的是young generation在整个JVM heap中所占的比重;
排在第二位的是整个JVM heap的大小;
排在第一位的就是选择合适的GC collector,这也是本文的内容所在。
基本概念
先科普一些基本知识。JVM Heap在实现中被切分成了不同的generation(很多中文翻译成‘代’),比如生命周期短的对象会放在young generation,而生命周期长的对象放在tenured generation中,如下图(摘自【2】)。

当GC只发生在young generation中,回收young generation中的对象,称为Minor GC;当GC发生在tenured generation时则称为Major GC或者Full GC。一般的,Minor GC的发生频率要比Major GC高很多。
关于generation的知识,这里不多谈了,感兴趣的参见【2】,或者很多网上的文章。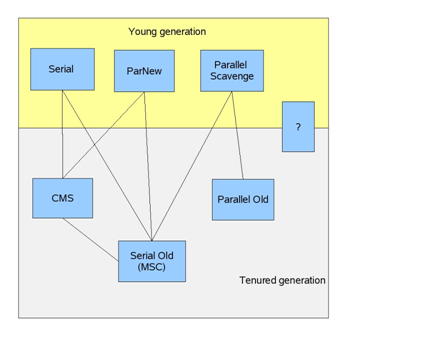
上图(摘自【3】)很清楚的列出了JVM提供的几种GC collector。
其中负责Young Generation的collector有三种:
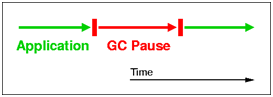
Serial :最简单的collector,只有一个thread负责GC,并且,在执行GC的时候,会暂停整个程序(所谓的“stop-the-world”),如下图所示;
Parallel Scavenge:
和Serial相比,它的特点在于使用multi-thread来处理GC,当然,在执行的时候,仍然会“stop-the-world”,好处在于,暂停的时间也许更短;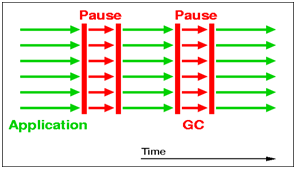
ParNew:
它基本上和Parallel Scavenge非常相似,唯一的区别,在于它做了强化能够和CMS一起使用;
负责Tenured Generation的collector也有三种:
Serial Old:
单线程,采用的是mark-sweep-compact回收方法(好吧,我承认我不知道什么是mark-sweep-compact,对我来说,只记住了它是单线程的),图示和Serial类似;
Parallel Old:
同理,多线程的GC collector;
CMS:
全称“concurrent-mark-sweep”,它是最并发,暂停时间最低的collector,之所以称为concurrent,是因为它在执行GC任务的时候,GC thread是和application thread一起工作的,基本上不需要暂停application thread,如下图所示;
6种collector介绍完了。不过,在设定JVM参数的时候,很少有人去分别制定young generation和tenured generation的collector,而是提供了几套选择方案:
-XX:+UseSerialGC:
相当于”Serial” + “SerialOld”,这个方案直观上就应该是性能最差的,我的实验证明也确实如此;
-XX:+UseParallelGC:
相当于” Parallel Scavenge” + “SerialOld”,也就是说,在young generation中是多线程处理,但是在tenured generation中则是单线程;
-XX:+UseParallelOldGC:
相当于” Parallel Scavenge” + “ParallelOld”,都是多线程并行处理;
-XX:+UseConcMarkSweepGC:
相当于"ParNew" + "CMS" + "Serial Old",即在young generation中采用ParNew,多线程处理;在tenured generation中使用CMS,以求得到最低的暂停时间,但是,采用CMS有可能出现”Concurrent Mode Failure”(这个后面再说),如果出现了,就只能采用”SerialOld”模式了;
【3】中还提到了一个方案:UseParNewGC,不过我在其它地方很少看见有人用它,就不介绍了。
实验和结果
说了这么多,还是用实验验证一下吧。
被实验的系统可以看做是一个内存数据库,所有的数据和查询都是在内存中进行,测试用的workload即包含将数据写入到内存中,也包含各式各样的查询。这样一个系统和测试数据,在运行过程中,由于处理大量的查询,所以肯定会随时产生很多的短周期对象,所以young generation对应的Minor GC会比较频繁,同时,由于不断有新的数据写入到数据库,而这些数据都属于长周期对象,所以tenured generation的使用率是不断增长。
实验使用的是一台DELL的服务器,有48G内存,有2个CPU,各4个core,所以总共8个core。为了实验的方便,我只是用了大概16G内存给JVM使用。
SerialGC
先看第一张图:
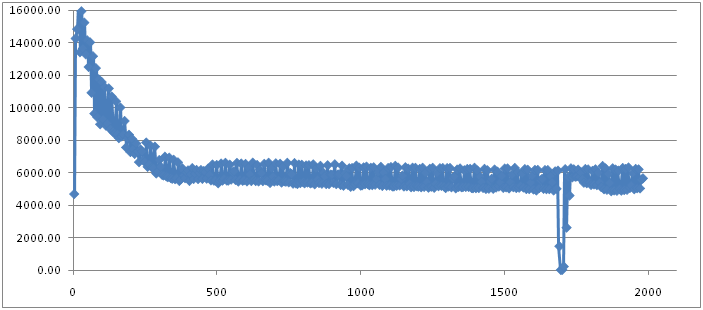
图中的采样点有些密集,截取其中的一小段放大如下:

图的纵轴表示的是系统的throughput,单位是request/second。我设定的计算throughput的时间间隔是5秒,也就是说,图中的每一个点,都是一个5秒时间区间内系统throughput的平均值。
图的横轴表示的是时间维度。
后面几张图的设定和这个图是一样的。
这张图采用的是SerialGC ,整个JVM的参数设置如下:
java -jar -Xms10g -Xmx15g -XX:+UseSerialGC -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:./log/gc.log Slaver.jar
其中,-XX:NewSize=6g -XX:MaxNewSize=6g 表示的是将young generation的初始化size和最大size都设置成了6G,也就是说在整个系统运行过程中,young generation的size是不会变的。这是因为JVM会根据实际的运行情况动态的调节young generation和tenured generation的比例,而这样的设置能够避免这种动态的调整,便于观察实验结果。
-Xms10g -Xmx15g 表示将JVM Heap的初始Size设置为10G,而它的最大Size设置为15G。相当于初始的时候tenured generation的大小约等于(10-6)G,而它可以增长为(15-6)G (只是近似计算,忽略了perm generation的size)。
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:./log/gc.log 这些参数,是将GC的细节和Heap的变化记录到gc.log中。
Slaver.jar 是俺的程序....
对于后面的实验,这些参数都不会变动。唯一变动的就只是选择不同的Collector。
OK,回到实验结果图。
这张图有一个很有趣的现象是它的抖动非常大,几乎总是一个点高,紧挨着一个点就会低。这意味着系统的throughput在不断的震荡。这个现象的原因是实验过程中,Minor GC的发生频率基本上是7-9秒一次(通过log观察到的),而前面提到了我们计算throughput的时间区间是5秒,所以,基本上每隔一个时间区间就会发生一次Minor GC,而发生Minor GC的时间区间它的平均throughput就会降低。
为了证明这一点,我随意找了一段Minor GC的log:
900.692: [GC 900.692: [DefNew: 5334222K->300781K(5662336K), 0.8988610 secs] 7654628K->2641401K(9856640K), 0.8990190 secs] [Times: user=0.86 sys=0.03, real=0.89 secs ]
解释一下这段log:
900.692 表明这次GC发生在系统启动后的900.062秒这一时刻;
5334222K->300781K(5662336K) 表明young generation在这次GC中从5334222K降低到了300781K,而young generation的size是5662336K(注意,这个值近似于我们之前设定的6G),这个过程花费了0.8988610秒;
7654628K->2641401K(9856640K) 表明这个JVM Heap从7654628K降低到了2641401K(这两个值之差应该和上面的那两个值之差几乎相等,因为这是Minor GC,所以整个Heap清理出的空间其实就是young generation清理出的空间);
user=0.86 sys=0.03, real=0.89 secs 表明这次GC的user time是0.86,而real time是0.89秒 (不理解user/sys/real的见【4】)
我们之前提到过,SerialGC是需要将整个application暂停的,所以,这次GC将整个application暂停了0.89秒,就是这个暂停导致了系统throughput的下降;
图中更有意思的现象是在横轴1700附近,系统的throughput直线下降到几乎为0。直观的猜测,这里应该是发生了Full GC。果然,在log中找到了它:
1700.750: [GC 1700.750: [DefNew: 5335802K->302541K(5662336K), 0.9367800 secs ]1701.687: [Tenured: 4210828K->4211008K(4211008K), 17.6799010 secs ] 9526754K->4513370K(9873344K), [Perm : 11048K->11048K(21248K)], 18.6220490 secs] [Times: user=18.61 sys=0.01, real=18.62 secs ].
这里最重要的是这句:[Tenured: 4210828K->4211008K(4211008K), 17.6799010 secs] ,表示对tenured generation进行了GC,花费了17.6799010秒(由于我写入的数据是要一直保存的,所以这次GC几乎没有在tenured generation中清除任何的dead object,所以下降幅度不大4210828K->4211008K)。
而这次GC总的花费了18.62 secs,意味着系统在这18秒内都被暂停了,在这18秒内系统几乎没有任何的throughput。所以,采用Seral GC,意味着系统在发生Full GC的时候,将会有大概十几秒的时间对外界的请求没有响应,如果是一个Web Server的话,意味着这十几秒用户没法浏览网页。这个感觉可不好。
此外,log还记录了Full GC发生前后Heap的情况:
{Heap before GC invocations=204 (full 0):
...........................................
tenured generation total 4194304K , used 4190951K [0x00007fe2c82e0000, 0x00007fe3c82e0000, 0x00007fe5082e0000)
the space 4194304K, 99% used [0x00007fe2c82e0000, 0x00007fe3c7f99dd8, 0x00007fe3c7f99e00, 0x00007fe3c82e0000)
........................................
........................................
Heap after GC invocations=205 (full 1):
....................................................................
tenured generation total 7018348K , used 4211008K [0x00007fe2c82e0000, 0x00007fe4748bb000, 0x00007fe5082e0000)
the space 7018348K, 59% used [0x00007fe2c82e0000, 0x00007fe3c9330000, 0x00007fe3c9330000, 0x00007fe4748bb000)
......................................................
}
从log可以看到,在GC发生之前,Heap里面的tenured generation的占用率已经到了99%,意味着tenured generation已经满了。所以,可以判断出,Full GC发生的条件就是tenured generation已经满了。
而在GC发生之后,发现total space从4194304K增长到了7018348K。还记得吗,我们在设置JVM的时候,初始Heap的Size是10G,最大的Size是15G,那多出的5G就是用于generation的增长的。
最后,你能够发现,无论是Minor GC还是Major GC,它的user time和real time的值相差不大,如果你了解user time和real time的意义,就能够知道这意味着GC这个任务是有单线程执行的,才会出现这种情况。这也和SerialGC的概念相吻合了。
ParallelGC
再来看看parallelGC的结果。
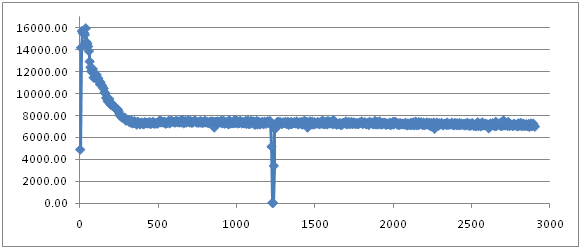
截取其中一段放大如下:
JVM参数如下:
java -jar -Xms10g -Xmx15g -XX:+UseParallelGC -XX:ParallelGCThreads=8 -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:./log/gc.log Slaver.jar
XX:ParallelGCThreads是用来设置GC并行线程的数量,由于我的测试服务器是8个core,所以这里也设置成了8;
和上一篇中SerialGC的实验结果图相比,有了很大的差别:
首先是整条throughput曲线的抖动明显下降了,并且,更重要的是,整个系统的平均throughput提高了。SerialGC中的曲线在6000左右抖动,而这的实验结果图中,throughput基本上在7000以上。这说明MinorGC对系统造成的影响变小了,为了确认这一点,可以随意看一条Minor GC的log:
1020.911: [GC [PSYoungGen: 6252096K->22304K(6260544K)] 9744749K->3537437K(10454848K), 0.0831140 secs] [Times: user=0.62 sys=0.06, real=0.09 secs ]
从log中读出,一个minor GC在0.09秒内就完成了,相当于只阻塞了application 0.09秒的时间,和SerialGC相比,大概缩短为它的几分之一。正是因为minor GC的时间变短,所以系统受到的影响变小,整体性能也显著提高。
实际上,在Sun的官方文档中,ParallelGC也是被推荐为“能够最大化系统的throughput”。而且,在服务器一级的机器上,ParallelGC是被设置为默认的GC collector,也就是说,如果JVM参数什么没有,那么就是采用Parallel GC。
有一个需要注意的是,虽然real time是0.09秒,但是user time是real time的好几倍,正好说明在执行minor GC的时候是由多个thread共同完成的。
不过,和SerialGC一样,它也有一个大峡谷,和SerialGC一样,这也是Full GC发生的地方:
1239.230: [Full GC [PSYoungGen: 22048K->17780K(6268352K)] [PSOldGen: 4190181K->4194303K(9437184K)] 4212229K->4212084K(15705536K) [PSPermGen: 11049K->11049K(22400K)], 14.1572170 secs] [Times:user=14.15 sys=0.01, real=14.16 secs ]
整个Full GC持续了14.16秒,这段时间系统的throughput下降为0。这点上,ParallelGC和SerialGC相比并没有任何优势。并且,user time和real time值差不多,说明也是由单线程完成的Full GC的工作。
最后需要指出的是,采用ParallelGC的实验发生Full GC的时间和Seral GC相比要更早一些。这主要是因为平均的throughput要比前者更好,所以插入数据的速度更快,所以tenured generation更早的就被数据填满了。
ParallelOldGC
JVM参数如下:
java -jar -Xms10g -Xmx15g -XX:+UseParallelOldGC -XX:ParallelGCThreads=8 -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:./log/gc.log Slaver.jar
实验结果:
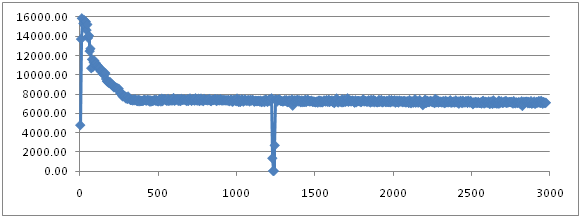
实验结果几乎和ParallelGC一模一样。
它的minor GC的机制和ParallelGC是一样的,所以就不多说了。
但是在Full GC的时候还是有一些差别:
1248.458: [Full GC [PSYoungGen: 22176K->0K(6268224K)] [ParOldGen: 4179368K->4166292K(9437184K)] 4201544K->4166292K(15705408K) [PSPermGen: 11047K->11032K(22400K)], 17.1588660 secs] [Times:user=124.85 sys=0.53, real=17.16 secs ]
老实说,这个结果有些出乎意料。因为按照文档,ParallelOldGC在执行FullGC的时候是多线程工作的,我原以为Full GC的时间就会相应的缩短很多。但是,至少在我的实验中,两者的Full GC的时间差不多(14.16 vs 17.16)。唯一让我确定ParallelOldGC确实是采用多线程工作的是,user time相比real time委实大了好几倍。但是貌似多线程的Full GC在我这里没有起到作用。
CMS Collector
在很多地方,CMS Collector常被翻译成“并发”,而ParallelGC被称为“并行”,但中文里,这两词的区分度并不明显。事实上,所谓的Parallel是指,在执行GC的时候将会有多个GC线程共同工作,但是,在执行GC的过程中仍然是“stop-the-world”。CMS的区别在于,在执行GC的时候,GC线程是不需要暂停application的线程,而是和它们“并发”一起工作。
所以,采用CMS的原因就在于它可以提供最低的pause time。
回到CMS的示意图: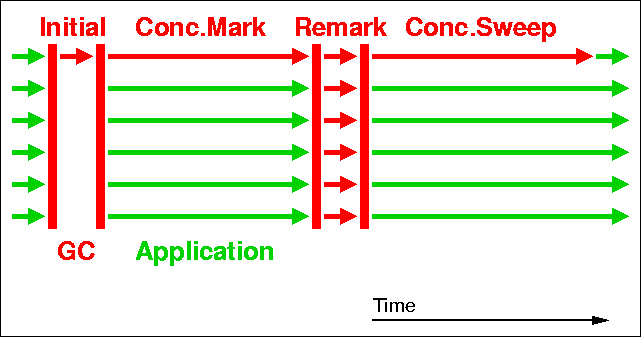
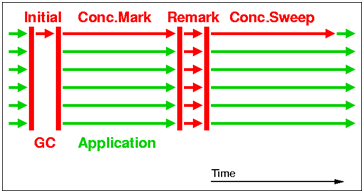
这张图表示的是CMS在执行Full GC的过程,这个过程包括了6个步骤:
# STW initial mark
# Concurrent marking
# Concurrent precleaning
# STW remark
# Concurrent sweeping
# Concurrent reset
STW表示的意思就是“stop-the-world”。
所以,CMS也并不是完全不会暂停application的,在这六个步骤中,有两个步骤需要STW,分别是:initial mark和remark(如图所示)。而其它的四个步骤是可以和application“并发”执行。initial mark是由一个GC thread来执行,它的暂停时间相对比较短。而remark过程的暂停时间要比initial mark更长,且通常由多个thread执行。
这六个步骤的具体内容我就不写了(其实俺也似懂非懂),有兴趣的可以参考【2】,【5】。
接下来看看实验结果。
实验结果
JVM参数如下:
java -jar -Xms10g -Xmx15g -XX:+UseConcMarkSweepGC -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:./log/gc.log Slaver.jar
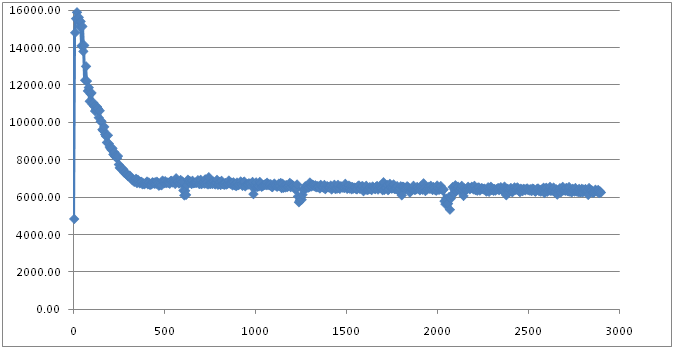
从图中可以看出,采用CMS Collector的最大的不同在于它已经没有了那个“大峡谷”,意味着发生的Full GC并没有导致系统的throughput降低到0。虽然图中也有几次曲线的下降(事实上,这就是发生Full GC的地方),但是曲线的下降很微弱,并且,持续时间也不太长。
整体而言,系统的平均throughput大概在7000 – 6000 request/sec之间,要比Serial GC好,但略低于Parallel GC。
看一个Minor GC的log:
519.514: [GC 519.514: [ParNew: 5149852K->83183K(5662336K), 0.0831770 secs] 6955196K->1905793K(9856640K), 0.0833560 secs] [Times: user=0.57 sys=0.03, real=0.08 secs ]
采用CMS GC在发生Minor GC的时候采用的collector类似于Parallel GC,log也和Parallel GC的log类似。不多解释。
重点在于Full GC的log:
2051.800: [GC [1 CMS-initial-mark : 6040466K(6555784K)] 6161554K(12218120K), 0.1028810 secs] [Times: user=0.10 sys=0.00, real=0.11 secs ]
2051.903: [CMS-concurrent-mark-start ]
2059.492: [GC 2059.492: [ParNew: 5153779K->129958K(5662336K), 0.1145560 secs] 11194245K->6189004K(12218120K), 0.1147330 secs] [Times: user=0.82 sys=0.04, real=0.11 secs]
2067.229: [GC 2067.229: [ParNew: 5163174K->92868K(5662336K), 0.1136260 secs] 11222220K->6170498K(12218120K), 0.1137820 secs] [Times: user=0.82 sys=0.00, real=0.12 secs]
2075.005: [GC 2075.005: [ParNew: 5126084K->126301K(5662336K), 0.1205450 secs] 11203714K->6222479K(12218120K), 0.1207120 secs] [Times: user=0.84 sys=0.01, real=0.12 secs]
2077.487: [CMS-concurrent-mark: 25.231/25.584 secs] [Times: user=158.91 sys=22.71, real=25.58 secs ]
2077.487: [CMS-concurrent-preclean-start ]
2078.512: [CMS-concurrent-preclean: 0.961/1.025 secs] [Times: user=5.97 sys=1.20, real=1.03 secs]
2078.513: [CMS-concurrent-abortable-preclean-start]
2082.466: [GC 2082.467: [ParNew: 5159517K->89444K(5662336K), 0.1162740 secs] 11255695K->6204092K(12218120K), 0.1164340 secs] [Times: user=0.82 sys=0.01, real=0.12 secs]
CMS: abort preclean due to time 2083.642: [CMS-concurrent-abortable-preclean: 4.933/5.129 secs] [Times: user=31.10 sys=4.89, real=5.12 secs]
2083.644: [GC[YG occupancy: 877128 K (5662336 K)]2083.644: [Rescan (parallel) , 0.5058390 secs]2084.150: [weak refs processing, 0.0000630 secs] [1 CMS-remark: 6114647K(6555784K)] 6991776K(12218120K), 0.5060260 secs] [Times: user=3.35 sys=0.01, real=0.50 secs ]
2084.150: [CMS-concurrent-sweep-start ]
2090.416: [GC 2090.416: [ParNew: 5122660K->124614K(5662336K), 0.1247190 secs] 11237258K->6257803K(12218120K), 0.1248800 secs] [Times: user=0.88 sys=0.00, real=0.12 secs]
2095.868: [CMS-concurrent-sweep: 11.593/11.718 secs] [Times: user=70.11 sys=11.53, real=11.72 secs]
2095.896: [CMS-concurrent-reset-start ]
2096.124: [CMS-concurrent-reset: 0.227/0.227 secs] [Times: user=1.33 sys=0.19, real=0.23 secs]
Full GC的log和其它的collector完全不同,简单解释一下:
log的第一行CMS-initial-mark 表示CMS执行它的第一步:initial mark。它花费的时间是real=0.11 secs,由于这一步骤是STW的,所以整个application被暂停了0.11秒。并且,user time和real time相差不大,所以确实是只有一个thread执行这一步;
CMS-concurrent-mark-start 表示开始执行第二步骤:concurrent marking。它执行时间是real=25.58 secs,但因为这一步是可以并发执行的,所以系统在这段时间内并没有暂停;
CMS-concurrent-preclean-start 表示执行第三步骤:concurrent precleaning。同样的,这一步也是并发执行;
最重要的是这一条语句:
2083.644: [GC[YG occupancy: 877128 K (5662336 K)]2083.644: [Rescan (parallel) , 0.5058390 secs]2084.150: [weak refs processing, 0.0000630 secs] [1 CMS-remark: 6114647K(6555784K)] 6991776K(12218120K), 0.5060260 secs] [Times: user=3.35 sys=0.01, real=0.50 secs]
这一步是步骤:remark的执行结果,它的执行时间是real=0.50 secs。因为这是STW的步骤,并且它的pause time一般是最长的,所以这一步的执行时间会直接决定这次Full GC对系统的影响。这次只执行了0.5秒,系统的throughput未受太大影响。
后面的log分别记录了concurrent-sweep和concurrent-reset。就不多说了,更详细的log分析可见【6】。
结论
比较了这几种Collector,发现CMS应该是最适合我的系统的。因为它并不会因为Full GC而在未来的某一时刻突然停滞工作。这一点其实在很多系统中都是非常重要的,比如Web Server ....
多说一点
贴另外两张实验结果图: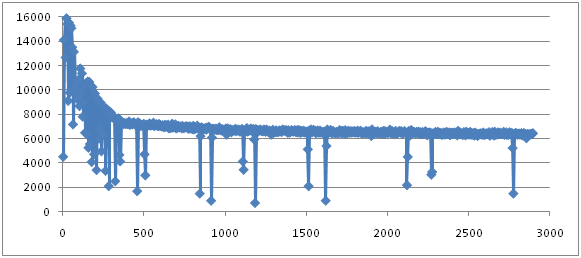

这两张图也是采用CMS Collector实验得到的。区别在于使用了不同的参数。第一张图是CMS Collector采用了incremental model的方式:
java -jar -Xms10g -Xmx15g -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:./log/gc.log Slaver.jar
而第二张图则调整了AbortablePrecleanTime的值:
java -jar -Xms10g -Xmx15g -XX:+UseConcMarkSweepGC -XX:CMSMaxAbortablePrecleanTime=15 -XX:NewSize=6g -XX:MaxNewSize=6g -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:./log/gc.log Slaver.jar
这两个参数有什么用不多解释,只是想说明,即便选择了合适的Collector,也可能由于其它参数的设置而产生巨大差异。
JVM的调优确实不简单。这个并没有绝对的准则或者公式,唯一的好办法就是实验。
Reference:
【1】The Second Most Important GC Tuning Knob
【2】Java SE 6 HotSpot[tm] Virtual Machine Garbage Collection Tuning
【3】Our Collectors
【4】 user / sys /real time
【5】Did You Know ...
【6】Understanding CMS GC Logs
- JVM调优:选择合适的GC collector
- JVM调优:选择合适的GC collector
- JVM调优:选择合适的GC collector
- JVM调优:选择合适的GC collector
- JVM调优:选择合适的GC collector (一)
- JVM调优:选择合适的GC collector (二)
- JVM调优:选择合适的GC collector (三)
- JVM调优:选择合适的GC collector (三)
- JVM调优:选择合适的GC collector (一)
- JVM调优:选择合适的GC collector (二)
- JVM调优:选择合适的GC collector (三)
- JVM调优:选择合适的GC collector (一)
- JVM调优:选择合适的GC collector (二)
- JVM调优:选择合适的GC collector (三)
- JVM调优:选择合适的GC collector (一)
- JVM调优:选择合适的GC collector (二)
- JVM调优:选择合适的GC collector (三)
- JVM locate collector GC
- ldap迁移脚本group
- 商场家电库存模型
- 浅谈观察者设计模式
- GDB常用命令说明
- MercurialHg介绍与安装
- JVM调优:选择合适的GC collector
- 反射+枚举+freemarker,自动生成实体类,自动建表建索引(二)之建表建索引,注解和DatabaseMetaData 获取信息
- Cocos2d-x Android配置
- Linux Fixmap 的作用
- AES简单实现
- WebUI 2013年产品线解析
- windows xp + cocos2d-x搭建
- do{ ... } while(0)
- JAVASE----05----多态


