DM6446的视频前端VPFE驱动之ioctl控制(视频缓存区,CCDC,decoder)解析之一
来源:互联网 发布:重生之星际淘宝主百度 编辑:程序博客网 时间:2024/04/30 06:48
本文均属自己阅读源码的点滴总结,转账请注明出处谢谢。http://blog.csdn.net/gzzaigcn/article/details/7750509
欢迎和大家交流。qq:1037701636 email:200803090209@zjut.com,gzzaigcn2012@gmail.com
在这里分析驱动的ioctl的内容时,需要结合相关的应用层的操作,之前我已经说过,这块V4L2的控制都是Ioclt实现的,在完成前期的驱动后,后续的系统调用都由他来完成,主要通过应用层发送一定的命令来完成调用。之前看过很多V4L2的内容,都会涉及到ioctl的内容,在这里我不再介绍。只解析几个核心的控制命令,来实现一个简单的视频采集。
先简单的说下视频ioctl系统调用的流程如下:

以上的流程图是在应用程序的ioctl和mmap的核心调用过程。每一个ioctl命令代表着对视频设备的控制。下面我选择涉及到缓存区相关操作的命令进行展开:
1.VIDIOC_REQBUFS申请视频缓存区,对应的源码位于davinci_vpfe.c的doioctl函数中,部分代码人如下:
- case VIDIOC_REQBUFS: //Initiates memory mapping or user pointer I/O,申请内存
- dev_dbg(vpfe_dev, "\nEnd of VIDIOC_REQBUFS ioctl");
- if (vpfe->io_usrs != 0) {
- ret = -EBUSY;
- break;
- }
- down_interruptible(&vpfe->lock);
- videobuf_queue_init(&vpfe->bufqueue, &video_qops, NULL,
- &vpfe->irqlock,
- V4L2_BUF_TYPE_VIDEO_CAPTURE,
- vpfe->field, //filed=V4L2_FIELD_INTERLACED
- sizeof(struct videobuf_buffer), fh);//主要完成vpfe_obj中的成员变量videobuf_queue的初始化
- videobuf_set_buftype(&vpfe->bufqueue, VIDEOBUF_BUF_LINEAR);//buf_type=VIDEOBUF_BUF_LINEAR
- fh->io_allowed = TRUE;
- vpfe->io_usrs = 1;
- INIT_LIST_HEAD(&vpfe->dma_queue);//初始化DMA链表头
- ret = videobuf_reqbufs(&vpfe->bufqueue, arg);//获取内存分配,完成相关初始化
- up(&vpfe->lock);
- dev_dbg(vpfe_dev, "\nEnd of VIDIOC_REQBUFS ioctl");
- break;
在这个case中,可以看到主要调用了videobuf_queue_init,在这个函数里主要完成了videobuf_queue这个缓存区队列的初始化,填充了其相关的内容,核心包括video_qops等。随后调用videobuf_reqbufs完成缓存区的真正申请。当然分析源码后核心的其实调用的是 q->ops->buf_setup(q,&count,&size); 函数,也就是队列初始化后的video_qops的buf_setup(所谓的缓存区真正的申请),下面我们来看这块的内容:
- buffer_setup(struct videobuf_queue *q, unsigned int *count, unsigned int *size)
- {
- vpfe_obj *vpfe = &vpfe_device;
- int i;
- unsigned int buf_size;
- dev_dbg(vpfe_dev, "\nstarting buffer_setup");
- if (device_type == TVP5146) {
- *size = buf_size = VPFE_TVP5146_MAX_FBUF_SIZE; //最大缓冲区768*576*2
- } else {
- *size = buf_size = VPFE_MT9T001_MAX_FBUF_SIZE;
- }
- for (i = VPFE_DEFNUM_FBUFS; i < *count; i++) { //VPFE_DEFNUM_FBUFS=3,如果多余3个再申请,否则跳过
- u32 size = PAGE_SIZE << (get_order(buf_size));
- void *mem = (void *)__get_free_pages(GFP_KERNEL | GFP_DMA, //DMA内存申请
- get_order(buf_size));
- if (mem) {
- unsigned long adr = (unsigned long)mem;
- while (size > 0) {
- /* make sure the frame buffers are never
- swapped out of memory *///交换内存
- SetPageReserved(virt_to_page(adr));
- adr += PAGE_SIZE;
- size -= PAGE_SIZE;
- }
- vpfe->fbuffers[i] = mem;
- } else {
- break;
- }
- }
- *count = vpfe->numbuffers = i; //3
- dev_dbg(vpfe_dev, "\nEnd of buffer_setup");
- return 0;
- }
在这个函数中,我们可以看到会根据用户应用程序设置的count参数,来判断是否还需要设置额外的缓存区,因为在注册驱动初始化的函数是已经申请了3个缓存区。获取了3个缓存区的虚拟内存地址。这个采用get_free_pages完成一个缓存区的页式申请,以4K一页为单位,完成申请,同时SetPageReserved完成每一页内存的驻留(在未释放前,不允许再申请)。最后将每一个缓存区内存首地址存入fbuffers[]数组之中。
同时在videobuf_reqbufs函数中还会调用videobuf_mmap_setup完成缓存区队列中的缓存区实例完成初始化,包括这个缓存区的相关性质。同时在该函数buffer_config中完成虚拟内存地址到实际物理地址的转换,存入到缓存区实例中。
2.VIDIOC_QUERYBUF查询缓存区的信息
执行函数videobuf_querybuf,最终会调用videobuf_status,完成当前缓存区信息的传递到用户层。
3.mmap的相关操作
在这里,针对视频数据量较大的内容,用户和内存之间的数据交互,是最为关键的内容。因此不能使用简单的read,write等系统调用来完成数据的读取,合理的方式是采用mmap这个系统调用,直接将物理内存映射到用户空间,不必要再使用read,write等从内核空间将数据进行拷贝,只需获取内存物理映射后的首地址即可。
内核中调用的函数为videobuf_mmap_mapper,代码如下:
- int videobuf_mmap_mapper(struct videobuf_queue *q,
- struct vm_area_struct *vma)
- {
- struct videobuf_mapping *map;
- unsigned int first,last,size,i;
- int retval;
- down(&q->lock);
- retval = -EINVAL;
- if (!(vma->vm_flags & VM_WRITE)) {
- dprintk(1,"mmap app bug: PROT_WRITE please\n");
- goto done;
- }
- if (!(vma->vm_flags & VM_SHARED)) {
- dprintk(1,"mmap app bug: MAP_SHARED please\n");
- goto done;
- }
- /* look for first buffer to map */
- for (first = 0; first < VIDEO_MAX_FRAME; first++) {
- if (NULL == q->bufs[first])
- continue;
- if (V4L2_MEMORY_MMAP != q->bufs[first]->memory)
- continue;
- if (q->bufs[first]->boff == (vma->vm_pgoff << PAGE_SHIFT))//在这里boff对应的为缓存区的物理首地址
- break;
- }
- if (VIDEO_MAX_FRAME == first) {
- dprintk(1,"mmap app bug: offset invalid [offset=0x%lx]\n",
- (vma->vm_pgoff << PAGE_SHIFT));
- goto done;
- }
- /* look for last buffer to map */
- for (size = 0, last = first; last < VIDEO_MAX_FRAME; last++) {
- if (NULL == q->bufs[last])
- continue;
- if (V4L2_MEMORY_MMAP != q->bufs[last]->memory)
- continue;
- if (q->bufs[last]->map) {
- retval = -EBUSY;
- goto done;
- }
- size += q->bufs[last]->bsize;
- if (size == (vma->vm_end - vma->vm_start))
- break;
- }
- if (VIDEO_MAX_FRAME == last) {
- dprintk(1,"mmap app bug: size invalid [size=0x%lx]\n",
- (vma->vm_end - vma->vm_start));
- goto done;
- }
- /* create mapping + update buffer list */
- retval = -ENOMEM;
- map = kmalloc(sizeof(struct videobuf_mapping),GFP_KERNEL);
- if (NULL == map)
- goto done;
- for (size = 0, i = first; i <= last; size += q->bufs[i++]->bsize) {
- q->bufs[i]->map = map;
- q->bufs[i]->baddr = vma->vm_start + size;
- }
- map->count = 1;
- map->start = vma->vm_start;
- map->end = vma->vm_end;
- map->q = q;
- if(q->buf_type == VIDEOBUF_BUF_LINEAR){
- vma->vm_page_prot = pgprot_writecombine(vma->vm_page_prot);
- if (io_remap_page_range(vma, vma->vm_start, //建立页表,完成用户空间和物理内存的直接映射
- (vma->vm_pgoff << PAGE_SHIFT),//实际所在的需要映射的物理页地址
- (vma->vm_end - vma->vm_start),
- vma->vm_page_prot)){
- return -EAGAIN;
- }
- vma->vm_flags |= VM_RESERVED | VM_IO;
- }else {
- vma->vm_ops = &videobuf_vm_ops;
- vma->vm_flags |= VM_DONTEXPAND | VM_RESERVED;
- vma->vm_flags &= ~VM_IO; /* using shared anonymous pages */
- }
- vma->vm_private_data = map;
- dprintk(1,"mmap %p: q=%p %08lx-%08lx pgoff %08lx bufs %d-%d\n",
- map,q,vma->vm_start,vma->vm_end,vma->vm_pgoff,first,last);
- retval = 0;
- done:
- up(&q->lock);
- return retval;
- }
- int videobuf_set_buftype(struct videobuf_queue *q, enum videobuf_buf_type type)
- {
- q->buf_type = type;
- return 0;
- }
对于mmap的相关概念理解在这里不做解释,本人也是参考着网上的资料学习而得。整个映射过程简单如图:
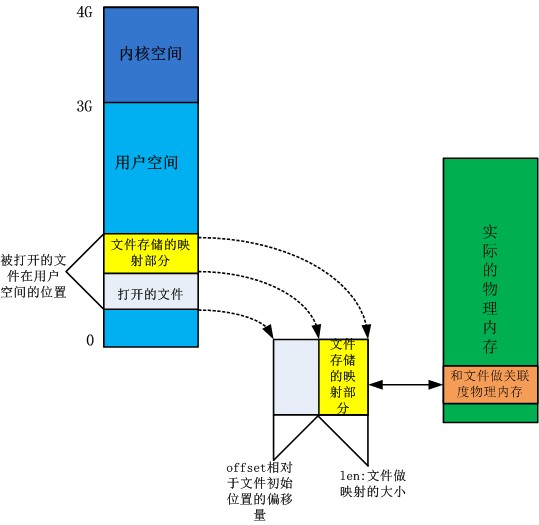
结合此图和mmap在驱动代码中的实现,我们可以分析出申请的缓存区物理地址的boff偏移量就等于vm_start与文件打开时在用户空间的虚拟首地址的差值,即用户层调用mmap时设置的offset。其实对于普通的文件以及/dev/mem linux内核已经都做好了系统调用的驱动实现。而针对自己需要使用mmap实现设备文件盒物理内存的关联即做映射,则需要自己实现mmap的功能。主要实现的函数io_remap_page_range完成页式的物理内存映射,传入的参数分别为vma这个结构体,文件映射部分在用户空间的首地址addr,以及在物理内存中的实际地址页帧号pfn,即物理地址》4K(一个页的大小),以及整个文件映射部分的大小size。实际上这个pfn参数虽然来自于offset参数,但是整个offset先前已经设置为了我们申请的缓存区在物理内存中的偏移值。换句话说,这个和设备文件做关联的内存并不是凭空产生的,而是先前已经获取。这样的合理设计整个缓存区,是整个V4L2这个视频驱动的重要部分。内存的合理分配也显得格外重要。
具体后续的缓存区队列的相关操作,我在下一篇博文中进行简单的分析和介绍。
- DM6446的视频前端VPFE驱动之ioctl控制(视频缓存区,CCDC,decoder)解析之一
- DM6446的视频前端VPFE驱动之ioctl控制(视频缓存区,CCDC,decoder)解析之一
- DM6446的视频前端VPFE驱动之ioctl控制(视频缓存区,CCDC,decoder)解析之二
- DM6446的视频前端VPFE驱动之ioctl控制(视频缓存区,CCDC,decoder)解析之二
- DM6446的视频前端VPFE的驱动大框架解析
- DM6446的视频前端VPFE的驱动大框架解析
- DM6446的视频前端VPFE的驱动大框架解析
- 视频虚拟驱动 ioctl 流程
- 视频驱动V4L2子系统驱动架构 - ioctl
- 基于DM6446的视频采集回放
- DM6446开发攻略:V4L2视频驱动和应用分析
- [前端] 音频/视频播放控制
- linux设备驱动之Ioctl控制
- Linux设备驱动之Ioctl控制
- Linux设备驱动之Ioctl控制
- Linux设备驱动之ioctl控制
- Linux设备驱动之Ioctl控制
- Linux设备驱动之Ioctl控制
- DM6446的视频前端VPFE的驱动大框架解析
- eclipse奇淫技巧
- 《代码大全》学习笔记(6):模块化设计
- 使用Microsoft Enterprise Library开发前配置
- hdu2955 解决问题的思路不错 逆向求解
- DM6446的视频前端VPFE驱动之ioctl控制(视频缓存区,CCDC,decoder)解析之一
- Oracle分页
- HDFS Federation设计动机与基本原理
- url-pattern配置技巧
- win32汇编 MASM03
- 如何在Delphi TImageList 中使用 透明 png 图标
- 关于qt中的tr()函数
- Python中的抽象超类
- 字符串全排列,去除重复


