Eclipse下运行Hadoop (测试WordCount) upon Ubuntu12.04 + JDK1.7.0
来源:互联网 发布:nba2k球星数据 编辑:程序博客网 时间:2024/05/25 05:36
××××××××××××××××××××××××××××××××自述 可忽略×××××××××××××××××××××××××××××××××××××××
大数据,分布式近年来被炒得非常热,而Hadoop作为一种开源的分布式平台也越来越受人关注,其热度从CSDN的主页上的曝光率就可知一二。 我最早接触Hadoop是在大二的时候,听香港理工的曹建农教授介绍Hadoop这个开源的新武器,当时来蹭讲座的我怎么也不会想到两年后我要用这个平台做我的毕业设计。上学期在做课程设计的时候的大胆挑战了分布式这个课题,然后选择了Hadoop这个平台,实现了一个7节点的distributed cluster。现在毕设更上一层,要在Hadoop上作出一套系统,免不了要用Eclipse这个神器来写程序,所以花了几天时间查阅资料,实现了Eclipse下运行Hadoop程序WordCount。
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
目标: 用Eclipse控制Hadoop文件系统HDFS, 在Eclipse下写程序直接在Hadoop上运行
环境参数:
OS: ubuntu 12.04 (most updated) 32 bit
JVM: JDK1.7.0
Eclipse: eclipse-java-juno-SR1-linux-gtk
Hadoop: hadoop-1.4.0
P.S.以上所有的资料都是开源的,都是从开源官网下的。(真心喜欢开源啊)
为了简单及不失普遍性,所搭建的Hadoop平台为伪分布式系统。
特别注意:
Eclipse所属用户必须对HADOOP_HOME具有可执行的权限,最简单的就是让这两者属于同一个用户。我就是一开始没有注意这点,一直失败。
***************************************************************************************************************************
前期准备工作: 实现Hadoop伪分布式系统
如何实现Hadoop伪分布式,有很多很好的博文可以借鉴,但是网上也有很多文章没有将清楚细节,所以我这里将我自己参考的资料列出来:
http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/ 这个外国哥们写得很详细,很多操作的原因也写得笔记清楚, 但是有一些细节还是要照着自己的环静该一下,比如: java的Path, Hadoop 的Path,你自己的用户名等。
我也把我自己的步骤贴出来,但是由于是很早以前写在实验报告里的,所以没有截图,而且格式比较乱。
JAVA环境设置(离线安装jdk7)
1.首先解压压缩包
$tarzxf jdk-7-linux-i586.tar.gz
将得到的jdk1.7.0存到/usr/local/java下
2.配置环境变量
在/etc/environment中添加如下内容:
exportJAVA_HOME=/usr/local/java/jdk1.7.0
exportJRE_HOME=/usr/local/java/jdk1.7.0/jre
exportCLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
在/etc/profile下,添加以下四行
exportJAVA_HOME=/usr/local/java/jdk1.7.0
exportJRE_HOME=/usr/local/java/jdk1.7.0/jre
exportCLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
exportPATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
umask022
验证java环境配置成功
重启系统,然后在命令行输入:
$java-version
如果显示一下内容则成功:
javaversion "1.7.0"
Java(TM)SE Runtime Environment (build 1.7.0)
JavaHotSpot(TM) Client VM (build 16.3-b01, mixed mode, sharing)
添加Hadoop系统的用户
$sudo addgroup hadoop$sudo adduser --ingroup hadoop hduser
配置SSH远程免密登录
1.在线安装SSH:
$sudoapt-get install openssh-server
2.生成SSH密钥:
$su - hduser$ssh-keygen -t rsa -P ""
将公钥添加到服务器上:
$cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
这样就完成了SSH远程登录设置,下面尝试一下SSH远程登录:
$ssh localhost
如果无需输入密码就可以登录到localhost下面的话就完成了SSH设置
禁用ipv6功能
在/etc/sysctl.conf 下面添加如下内容实现ipv6禁用:
net.ipv6.conf.all.disable_ipv6= 1
net.ipv6.conf.default.disable_ipv6= 1
net.ipv6.conf.lo.disable_ipv6= 1
重启,然后输入如下指令,如果输出结果为1,则ipv6禁用成功,如果结果为0,则没有禁用ipv6:
$cat /proc/sys/net/ipv6/conf/all/disable_ipv6
安装Hadoop包
1.在/usr/local路径下解压hadoop包,并且更换hadoop文件夹的用户:
$sudo tar xzf hadoop-1.0.4.tar.gz$sudo mv hadoop-1.0.4 hadoop$sudo chown -R hduser:hadoop hadoop
#更换用户一定不能忘记,linux下就是用户权限最要注意
2.hduser用户的主文件夹下的.bashrc内添加内容,如下:
#Set Hadoop-related environment variables
exportHADOOP_HOME=/usr/local/hadoop
#Set JAVA_HOME (we will also configure JAVA_HOME directly for Hadooplater on)
exportJAVA_HOME=/usr/local/java/jdk1.7.0
#Some convenient aliases and functions for running Hadoop-relatedcommands
unaliasfs &> /dev/null
aliasfs="hadoop fs"
unaliashls &> /dev/null
aliashls="fs -ls"
lzohead() {
hadoopfs -cat $1 | lzop -dc | head -1000 | less
}
#Add Hadoop bin/ directory to PATH
exportPATH=$PATH:$HADOOP_HOME/bin
配置Hadoop系统
1.确定SecondaryNameNode的主机名,修改/usr/local/hadoop/conf/master文件:
localhost
2.确定SecondaryNameNode的主机名,修改/usr/local/hadoop/conf/slaves文件:
localhost
3.修改core-site.xml文件,配置NameNode的主机名和端口号:
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
4.修改mapred-site.xml:,配置JobTracker的主机名和端口号:
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
</property>
5.修改hdfs-site.xml, 配置HDFS的默认副本数:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
格式化HDFS
切换到/usr/local/hadoop目录下:
$bin/hadoop namenode -format
启动Hadoop
1.同样在/usr/local/hadoop目录下:
$bin/start-all.sh
再输入指令查看守护进程:
$jps
如果输出如下六个守护进程则hadoop启动成功,否则失败。
TaskTracker
JobTracker
DataNode
SecondaryNameNode
Jps
系统监控窗口
Hadoop系统给用户提供了三个监控窗口实时监测系统状态,分别是:
(NameNode主机名):50030#TaskTracker Status
(NameNode主机名):50060#MapReduce Status
(NameNode主机名):50070#NameNode Status
************************************伪分布式Hadoop配置完毕*********************************************
***********************************Eclipse 安装插件**************************************************
为Eclipse添加Hadoop插件 hadoop-{version}-eclipse-plugin.jar
在hadoop-1.0.4的安装包里没有提供包装好的hadoop-eclipse-plugin, 但是在它的 HADOOP_HOME/src/contrib/eclipse-plugin下面有插件的源码,网上有一些教程是教你如何用这个源码做出插件,我按照他们的步骤是了一下,我自己生成的插件无法使用,就索性用网上高手提供的插件。
http://www.linuxidc.com/Linux/2013-01/77921.htm 这篇文章里既有生成插件的教程又有做好的插件 hadoop-eclipse-plugin-1.0.4.jar 。
这个插件可以放在eclipse_home目录下的两个地方:plugins 和dropins。 但是有一点他们没有说清楚,如果插件放在 plugins下面,插件名改为: hadoop-1.0.4-eclipse-plugin.jar,如果是在dropins下面,维持原来的插件名: hadoop-eclipse-plugin-1.0.4.jar 。
安装完插件后一定要重启Eclipse。
Eclipse里设置MapReduce Location
由于前面提到的权限问题,我下面提到的HADOOP_HOME和用户都变掉了,请按照自己的环境设置。
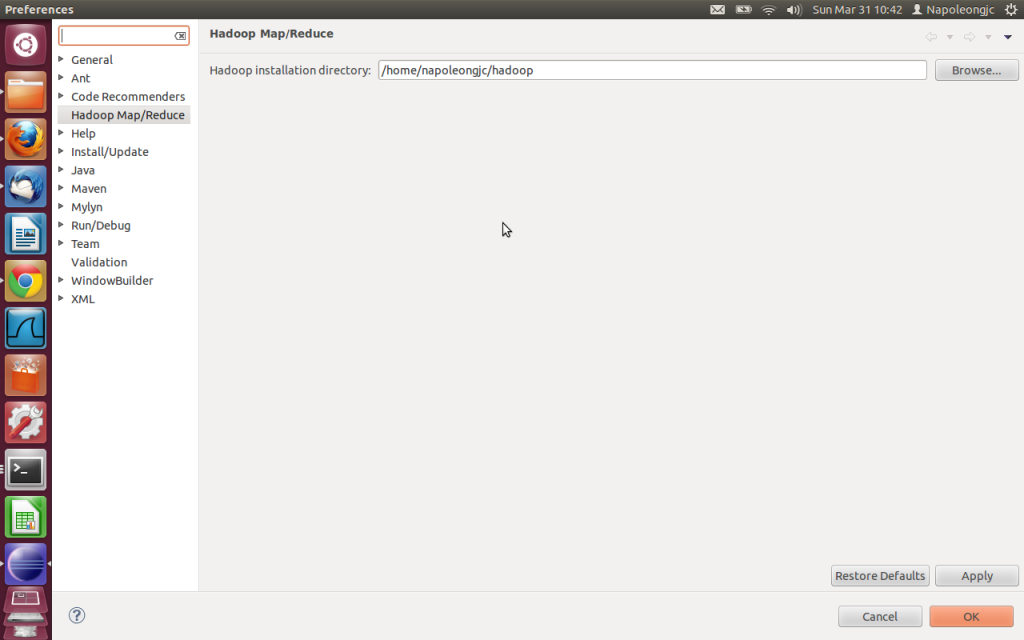
1. 打开Window-->Preferences,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation directory。配置完成后退出。
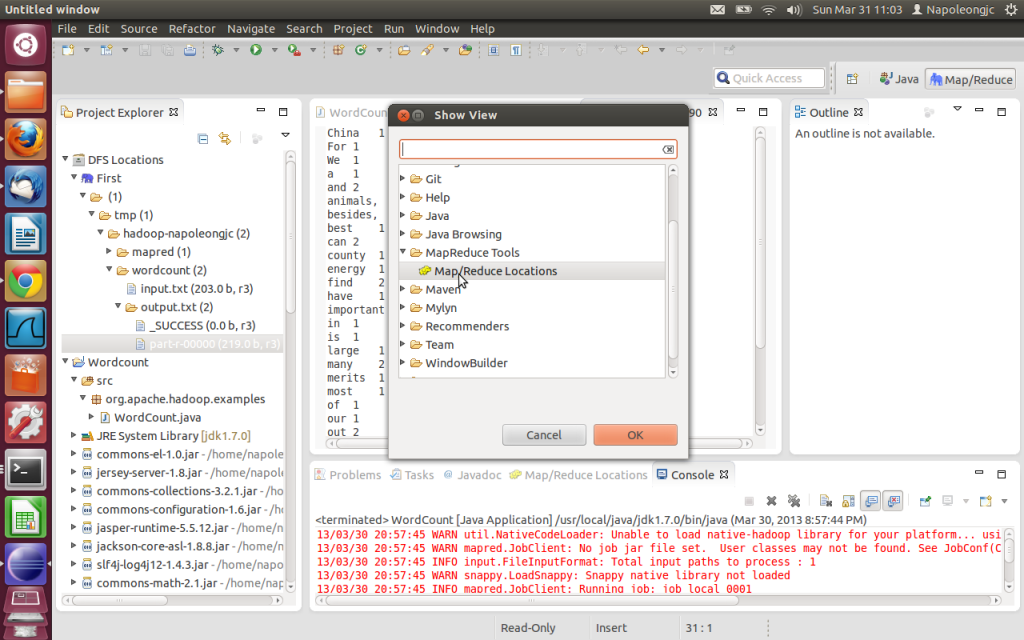
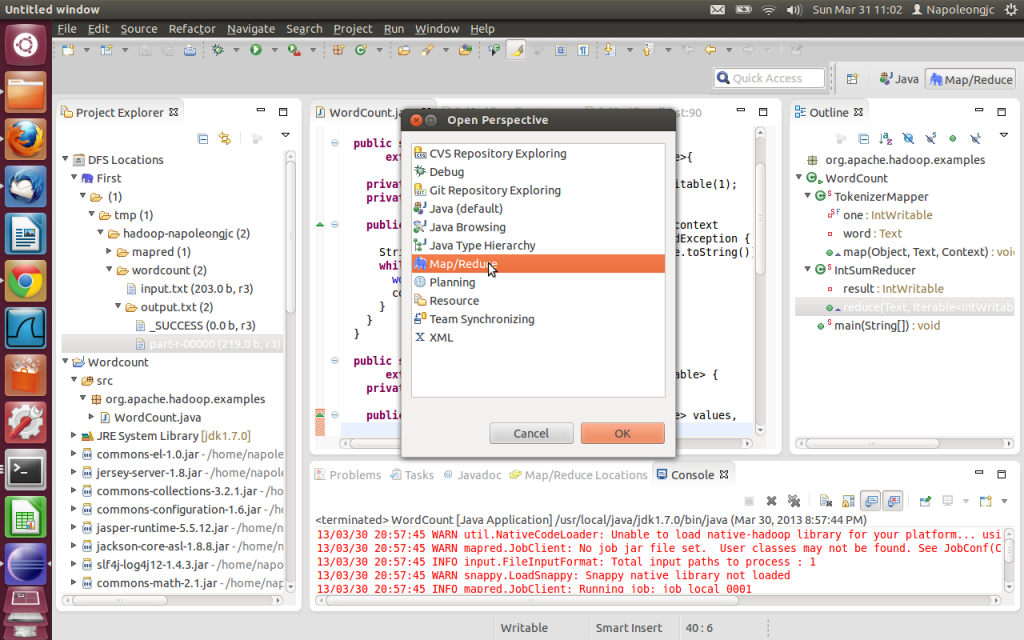
2. 在Window-->Show View-->Other-->MapReduce Tools中打开Map/Reduce Locations, 在Window-->Other Perspective-->Other--> MapReduce。
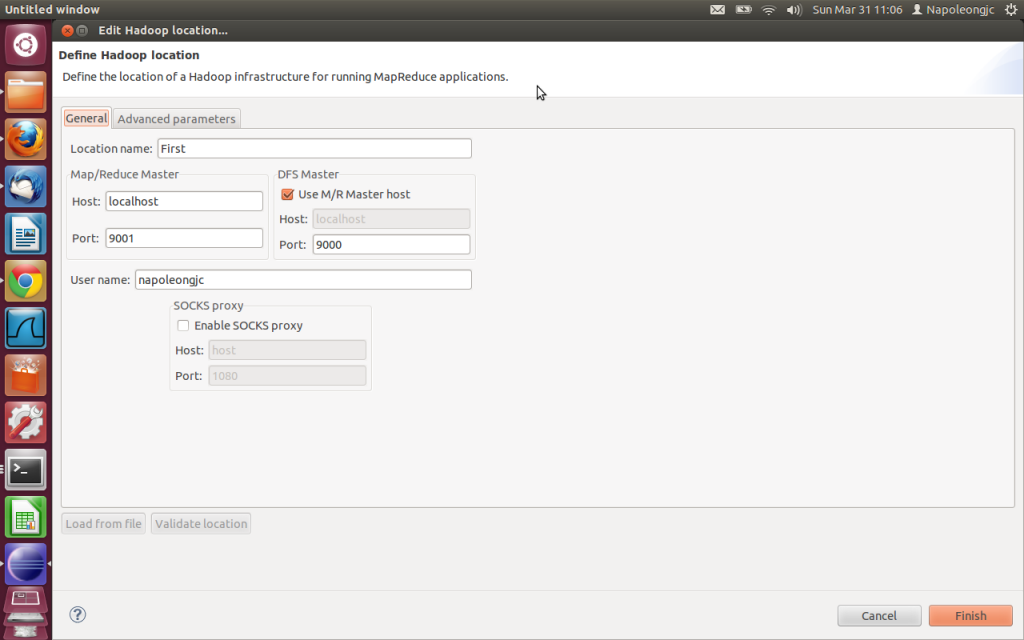
3. 在Map/Reduce Locations中新建一个Hadoop Location。在这个View中,右键-->New Hadoop Location。在弹出的对话框中你需要配置Location name,还有Map/Reduce Master和你在mapred-site.xml中设置一样; DFS Master和core-site.xml中配置的地址及端口一样。
4. 在Advanced parameters页面里,一般教程都没有说如何设置,可我觉得有一项必须要设置, 其中所有的文件夹地址都是默认的/tmp/hadoop-{username}/... 这个地址其实是HDFS在本地的地址,要和core-site.xml中设置一致。我这里为了方便,直接采用他默认的地址,因为后面还有很多选项的地址内都含有这个目录,如果要用这个系统做点什么,还是不要用/tmp的目录。
5. 配置完后退出。点击DFS Locations-->myubuntu如果能最后显示 jobtracker.info,说明配置正确。
下面是就新建MapReduce 工程,跑 WordCount程序了。
*********************************************************************
*************************运行 WordCount*******************************
运行WordCount
1. 新建MapReduce工程
File->New->Project, 选择MapReduce Project 。
、
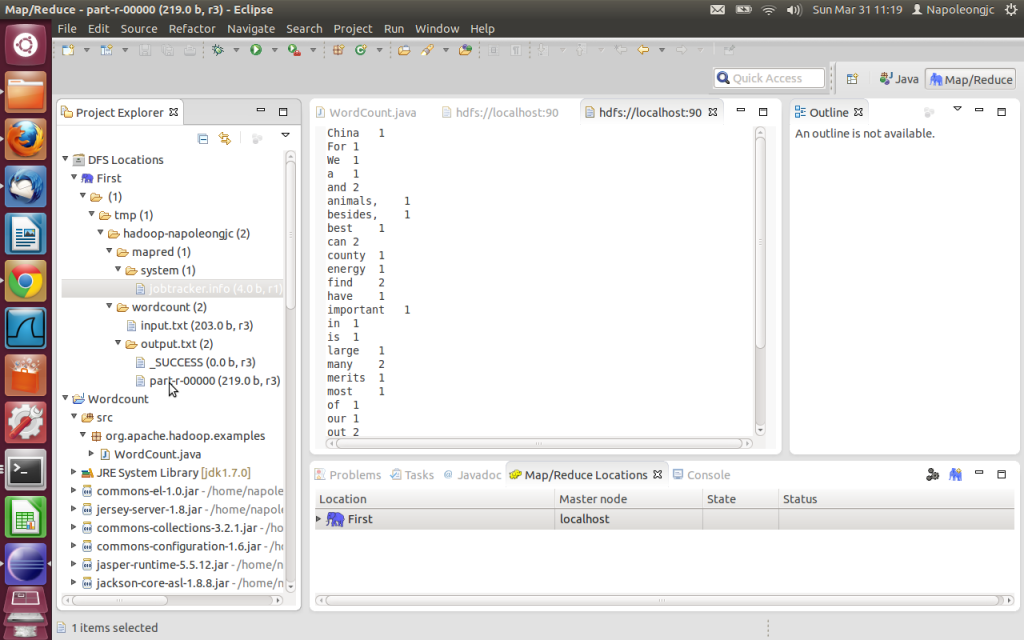
2. 复制 hadoop安装目录/src/example/org/apache/hadoop/example/WordCount.java到刚才新建的项目的src下面, 如上图所示。
3. 在外面新建一个文本文档input.txt,里面随便写点什么,然后在HDFS下新建文件夹 wordcount,将input.txt上传到wordcount下,也如上图所示。
新建文件夹既可以直接在Eclipse里选中hadoop-napoleongjc,然后选择Create New Directory...,也可以在hadoop安装目录下输入命令:
bin/hadoop fs -mkdir /tmp/hadoop-napolepngjc/wordcount
上传文件也是如此, 命令是: bin/hadoop fs -copyFromLocal /home/input.txt /tmp/hadoop-napoleongjc/wordcount/input.txt
4. 运行项目
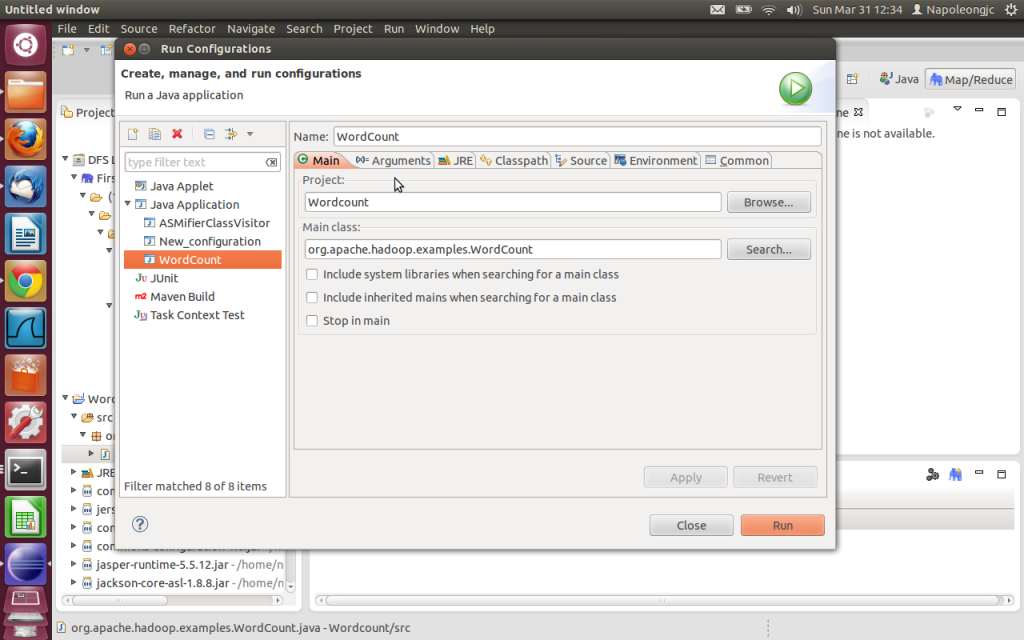
选中WordCount,右击, Run AS--> Run Configuration. 在Java Application内选择WordCount ,可能第一次打开这个没有这个选项,你就先随便选,点击Run,肯定会出错,然后再打开这个对话框就可以在Java Application里看到WordCount。
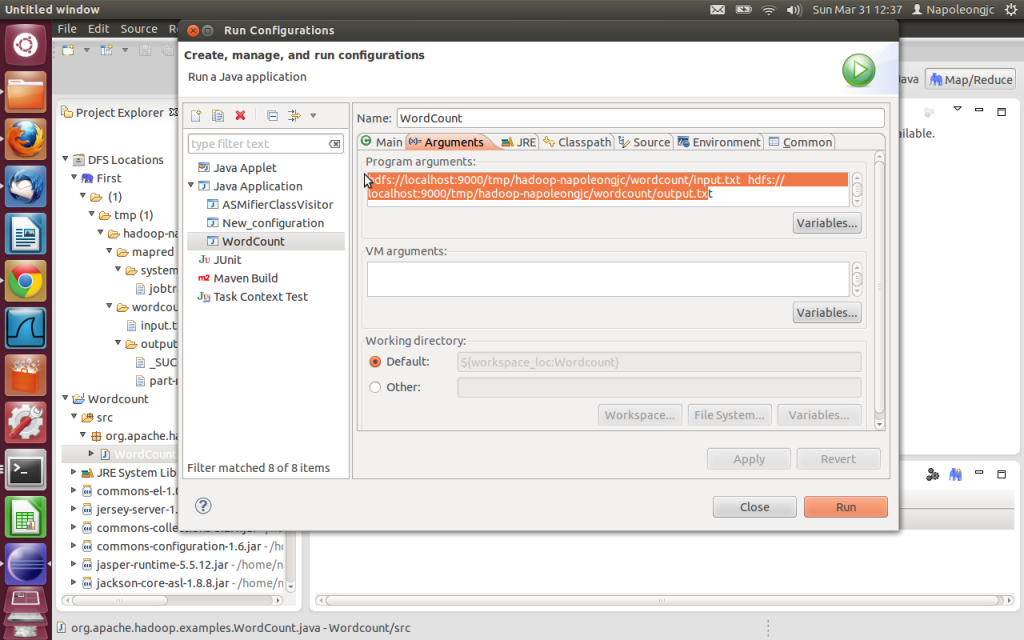
还是则那个对话框内,Arguments那里写 hdfs://localhost:9000/tmp/hadoop-napoleongjc/wordcount/input.txt hdfs://localhost:9000/tmp/hadoop-napoleongjc/wordcount/output.txt
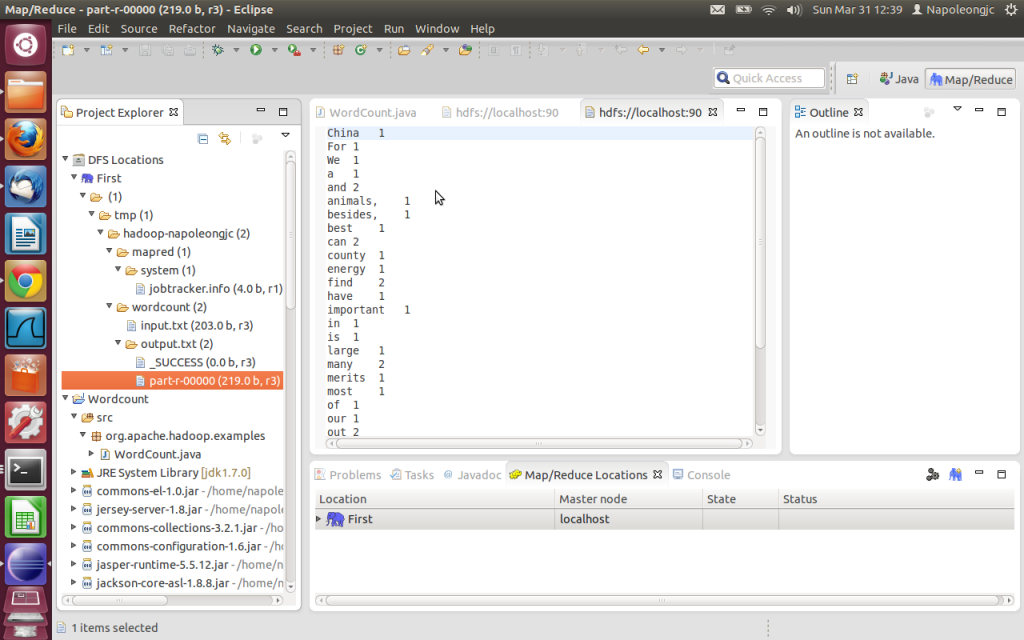
这样就完成了, 点击Run 就可以执行了。执行结果可以在output下面看到。
**************************************The End******************************************
下面把参考的几个网址再列一下:
http://xiaofancn.iteye.com/blog/1435099
http://phz50.iteye.com/blog/932373
http://ebiquity.umbc.edu/Tutorials/Hadoop/00%20-%20Intro.html
http://www.cnblogs.com/wly603/archive/2012/04/18/2454936.html

- Eclipse下运行Hadoop (测试WordCount) upon Ubuntu12.04 + JDK1.7.0
- Eclipse下运行Hadoop测试WordCount
- Hadoop Eclipse下运行WordCount
- eclipse下安装配置hadoop(含WordCount程序测试)
- Ubuntu12.04+hadoop-1.1.2运行wordcount示例
- eclipse运行hadoop wordcount example
- Eclipse运行Hadoop WordCount例程
- Eclipse下伪分布式运行hadoop例子wordcount
- linux下eclipse上运行hadoop自带wordcount程序
- Eclipse下运行hadoop自带的mapreduce程序--wordcount
- eclipse 环境下运行hadoop-2.5.1wordcount程序
- 在windows7下Eclipse中运行Hadoop的WordCount程序
- hadoop下运行实例wordcount
- Eclipse下运行Hadoop程序(以WordCount为例,使用Maven)
- Eclipse 运行WordCount实例 (连接Linux下的Hadoop集群)
- hadoop学习之HDFS(2.5):windows下eclipse远程连接linux下的hadoop集群并测试wordcount例子
- hadoop学习之HDFS(2.5):windows下eclipse远程连接linux下的hadoop集群并测试wordcount例子
- hadoop学习之HDFS(2.1):linux下eclipse中配置hadoop-mapreduce开发环境并运行WordCount.java程序
- 调节小根堆算法
- 1046
- A3、限制函数内部循环使用局部变量的数目,最多不超过12个
- Ubuntu下搭建嵌入式nfs
- 源码编译搭建Key形式openvpn v2.1.3
- Eclipse下运行Hadoop (测试WordCount) upon Ubuntu12.04 + JDK1.7.0
- 源码编译搭建Key形式支持ipv6的openvpn v2.1.3
- mysql“Access denied for user 'root'@'localhost'”问题的解决
- yum搭建Key形式openvpn v2.3.2
- openvpn v2.3.2添加ipv6支持
- 专题2-4逻辑运算符使用分析
- VS2005下wxWidgets-2.8.x环境的搭建
- windows无法完成格式化
- Tomcat内存溢出分析及解决方法


