GLIBC内存分配机制引发的“内存泄露”
来源:互联网 发布:在线编辑器 源码 编辑:程序博客网 时间:2024/05/17 00:53
http://www.longyusoft.com/detail.php?id=295
作者: Chuanhui | 可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明
本文链接地址: http://www.nosqlnotes.net/archives/105
我们正在开发的类数据库系统有一个内存模块,出现了一个疑似”内存泄露”问题,现象如下:内存模块的内存释放以后没有归还操作系统,比如内存模块占用的内存为10GB,释放内存以后,通过TOP命令或者/proc/pid/status查看占用的内存有时仍然为10G,有时为5G,有时为3G, etc,内存释放的行为不确定。
首先说一下内存模块的内存管理机制。我们的内存管理很简单,使用全局的定长内存池,每一个内存块为64KB,如果申请的内存小于等于64KB时,直接从内存池的空闲链表中获取一个内存块,内存释放时归还空闲链表;如果申请的内存大于64KB,直接通过操作系统的malloc和free获取。某些数据结构涉及到很多小对象的管理,比如Hash表,B-Tree,这些数据结构从全局内存池获取内存后再根据数据结构的特点进行组织。为了提高内存申请/释放的效率,减少锁冲突,为每一个线程单独保留一个8MB的内存块,每个线程优先从线程专属的8MB内存块获取内存,专属内存不足时才从全局的内存池获取。
由于我们的所有内存申请/释放操作都需要通过全局的内存池进行,我们在全局的内存池中加入对每个子模块的内存统计功能:每个子模块申请内存时都将子模块编号传给全局的内存池,全局的内存池进行统计。复现问题后发现全局的内存池的统计结果符合预期,因此怀疑是操作系统或者glibc的行为。
Linux下Glibc的内存管理机制大致如下:
从操作系统的角度看,进程的内存分配由两个系统调用完成:brk和mmap。brk是将数据段(.data)的最高地址指针_edata往高地址推,mmap是在进程的虚拟地址空间中找一块空闲的。其中,mmap分配的内存由munmap释放,内存释放时将立即归还操作系统;而brk分配的内存需要等到高地址内存释放以后才能释放。也就是说,如果先后通过brk申请了A和B两块内存,在B释放之前,A是不可能释放的,仍然被进程占用,通过TOP查看疑似”内存泄露”。默认情况下,大于等于128KB的内存分配会调用mmap/mummap,小于128KB的内存请求调用sbrk(可以通过设置M_MMAP_THRESHOLD来调整)。详细的内存管理机制可以参考百度分享的文章。
我们的内存模块申请/释放内存都是以2MB为单位的,按理说应该是使用mmap和munmap进行内存分配和释放的,不会出现内存释放以后仍然被进程占用的情况。在内核同学的协助下,经过长时间的分析定位,发现了Glibc的新特性:M_MMAP_THRESHOLD可以动态调整。M_MMAP_THRESHOLD的值在128KB到32MB(32位机)或者64MB(64位机)之间动态调整,每次申请并释放一个大小为2MB的内存后,M_MMAP_THRESHOLD的值被调整为2M到2M + 4K之间的一个值(具体可以参考Glibc的patch说明)。例如:
char* no_used = new char[2 * 1024 * 1024];
memset(no_used, 0xfe, 2 * 1024 * 1024);
delete[] no_used;
// M_MMAP_THRESHOLD的值调整为2M到2M + 4K之间的一个值,后续申请 <= 2 * 1024 * 1024的内存块都会走sbrk而不是mmap
了解到这种现象后,我们找到了”内存泄露”的原因:M_MMAP_THRESHOLD的值动态调整,后续的2MB的内存申请通过sbrk实现,而sbrk需要等到高地址内存释放以后低地址内存才能释放。可以通过显式设置M_MMAP_THRESHOLD或者M_MMAP_MAX来关闭M_MMAP_THRESHOLD动态调整的特性,从而避免上述问题。
当然,mmap调用是会导致进程产生缺页中断的,为了提高性能,常见的做法如下:
1, 将动态内存改为静态,比如采用内存池技术或者启动的时候给每个线程分配一定大小,比如8MB的内存,以后直接使用;
2, 禁止mmap内存调用,禁止Glibc内存缩紧将内存归还系统,Glibc相当于实现了一个内存池功能。只需要在进程启动的时候加入两行代码:
mallopt(M_MMAP_MAX, 0); // 禁止malloc调用mmap分配内存
mallopt(M_TRIM_THRESHOLD, 0); // 禁止内存缩进,sbrk申请的内存释放后不会归还给操作系统
花絮:
追查”内存泄露”问题的过程中,尝试使用Glibc的钩子函数(Malloc Hook) 统计malloc和free的内存量:具体做法为malloc的时候多申请8个字节,其中4个字节记录长度,4个字节记录magic_num,malloc和free的时候统计进程申请和释放的内存量。实践表明无论自定义钩子函数是否加锁,malloc和free钩子函数在多线程的情况下运行都不正常,其它同学也发现了相同的问题(Malloc Hook多线程问题)。
http://bbs.csdn.net/topics/330179712
现象
1 压力测试过程中,发现被测对象性能不够理想,具体表现为:
进程的系统态CPU消耗20,用户态CPU消耗10,系统idle大约70
2 用ps -o majflt,minflt -C program命令查看,发现majflt每秒增量为0,而minflt每秒增量大于10000。
初步分析
majflt代表major fault,中文名叫大错误,minflt代表minor fault,中文名叫小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
检查要访问的虚拟地址是否合法
查找/分配一个物理页
填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
建立映射关系(虚拟地址到物理地址)
重新执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
此进程minflt如此之高,一秒10000多次,不得不怀疑它跟进程内核态cpu消耗大有很大关系。
分析代码
查看代码,发现是这么写的:一个请求来,用malloc分配2M内存,请求结束后free这块内存。看日志,发现分配内存语句耗时10us,平均一条请求处理耗时1000us 。 原因已找到!
虽然分配内存语句的耗时在一条处理请求中耗时比重不大,但是这条语句严重影响了性能。要解释清楚原因,需要先了解一下内存分配的原理。
内存分配的原理
从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。brk是将数据段(.data)的最高地址指针_edata往高地址推,mmap是在进程的虚拟地址空间中(一般是堆和栈中间)找一块空闲的。这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
下面以一个例子来说明内存分配的原理:
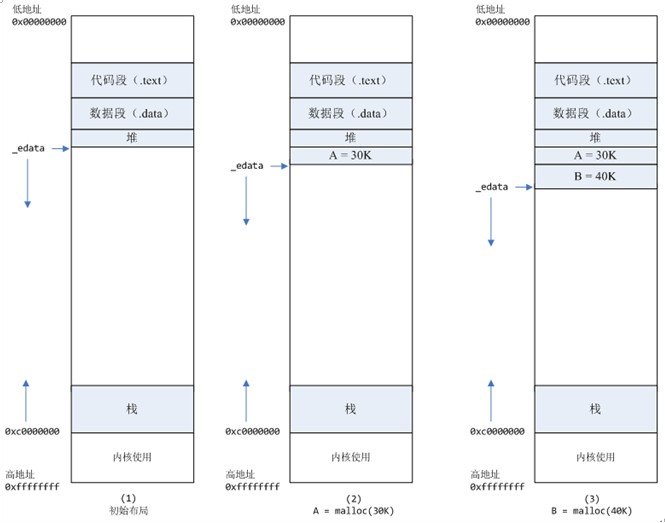
1进程启动的时候,其(虚拟)内存空间的初始布局如图1所示。其中,mmap内存映射文件是在堆和栈的中间(例如libc-2.2.93.so,其它数据文件等),为了简单起见,省略了内存映射文件。_edata指针(glibc里面定义)指向数据段的最高地址。
2进程调用A=malloc(30K)以后,内存空间如图2:malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配。你可能会问:只要把_edata+30K就完成内存分配了?事实是这样的,_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3进程调用B=malloc(40K)以后,内存空间如图3.

4进程调用C=malloc(200K)以后,内存空间如图4:默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存。这样子做主要是因为brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的),而mmap分配的内存可以单独释放。当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5进程调用D=malloc(100K)以后,内存空间如图5.
6进程调用free(C)以后,C对应的虚拟内存和物理内存一起释放

7进程调用free(B)以后,如图7所示。B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。
8进程调用free(D)以后,如图8所示。B和D连接起来,变成一块140K的空闲内存。
9默认情况下:当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
真相大白
说完内存分配的原理,那么被测模块在内核态cpu消耗高的原因就很清楚了:每次请求来都malloc一块2M的内存,默认情况下,malloc调用mmap分配内存,请求结束的时候,调用munmap释放内存。假设每个请求需要6个物理页,那么每个请求就会产生6个缺页中断,在2000的压力下,每秒就产生了10000多次缺页中断,这些缺页中断不需要读取磁盘解决,所以叫做minflt;缺页中断在内核态执行,因此进程的内核态cpu消耗很大。缺页中断分散在整个请求的处理过程中,所以表现为分配语句耗时(10us)相对于整条请求的处理时间(1000us)比重很小。
解决办法
将动态内存改为静态分配,或者启动的时候,用malloc为每个线程分配,然后保存在threaddata里面。但是,由于这个模块的特殊性,静态分配,或者启动时候分配都不可行。另外,Linux下默认栈的大小限制是10M,如果在栈上分配几M的内存,有风险。
禁止malloc调用mmap分配内存,禁止内存紧缩。
在进程启动时候,加入以下两行代码:
mallopt(M_MMAP_MAX, 0); // 禁止malloc调用mmap分配内存
mallopt(M_TRIM_THRESHOLD, -1); // 禁止内存紧缩
效果:加入这两行代码以后,用ps命令观察,压力稳定以后,majlt和minflt都为0。进程的系统态cpu从20降到10。
小结
可以用命令ps -o majflt minflt -C program来查看进程的majflt, minflt的值,这两个值都是累加值,从进程启动开始累加。在对高性能要求的程序做压力测试的时候,我们可以多关注一下这两个值。
如果一个进程使用了mmap将很大的数据文件映射到进程的虚拟地址空间,我们需要重点关注majflt的值,因为相比minflt,majflt对于性能的损害是致命的,随机读一次磁盘的耗时数量级在几个毫秒,而minflt只有在大量的时候才会对性能产生影响。
- GLIBC内存分配机制引发的“内存泄露”
- GLIBC内存分配机制引发的“内存泄露”
- GLIBC内存分配机制引发的“内存泄露”
- 转载-------GLIBC内存分配机制引发的“内存泄露”
- Message引发的内存泄露
- handler引发内存泄露
- java finalize 方法引发的内存泄露
- 继承threading.local引发的内存泄露
- 内存泄露可以引发的问题
- 使用Handler引发内存泄露的改进
- 错误使用Handler引发的内存泄露
- glibc内存分配实现细节
- string的内存分配引发的思考
- 【内存泄露】由Handler引发的内存泄漏的思考
- 【内存泄露】由Handler引发的内存泄漏的思考
- android的内存分配机制
- android的内存分配机制
- Matlab 的内存分配机制
- 信息资源管理
- VC++ Unable to register this add-in because its DllRegisterServer returns an error 解决方案
- SQLite学习笔记之二
- Vector sort 排序
- StringUtils
- GLIBC内存分配机制引发的“内存泄露”
- SQLite学习笔记之三
- 【Linux】Linux下MIPS平台交叉编译FFmpeg库 及使用库截取视频中的某一帧
- Zebra命令模式分析(二)[补]
- Arduino 入门
- 每日实现一算法之插入排序
- kill 和raise函数
- 错误总结
- struts返回对象json格式数据


